以太坊数据编码实现;智能合约
以太坊作为公开区块链技术平台,因为其良好的扩展性和灵活度,有很强的业务适用场景,这主要归功于其图灵完备的虚拟机与其上运行的智能合约。以太坊通过特定的编码方式实现对智能合约与账户数据的编码存储,同时又能在其数据基础上实现对区块与交易执行结果的完备共识证明。以下分几个部分来详细阐述。
以太坊RLP编码
RLP(Recursive Length Prefix)编码是以太坊中数据序列化的一个主要编码方式,可以将任意的嵌套二进制数据进行序列化。以太坊中针对RLP的编码规则定义如下:
1. 如果是一个单字节并且其值在[0x00,0x7f]范围内,RLP编码就是自身。 [0,127] = [0x00,0x7f]
2. 否则,如果一个数据串的字节长度是0-55字节,那么它的RLP编码是在数据串开头增加一个字节,这个字节的值是0x80加上数据串的字节长度。因此增加的该字节的取值范围为[0x80, 0xb7]。 [128,128+55] = [128,183] = [0x80, 0xb7]
3. 如果一个数据串的字节长度大于55,那么它的RLP编码是在开头增加一个字节,这个字节的值等于0xb7加上数据串字节长度的二进制编码的字节长度,然后依次跟着数据串字节长度部分和内容部分。比如:一个长度为1024字节的数据串,其字节长度用16进制表示为0x0400,长度为2个字节,因此RLP编码头字节的值为0xb9(0xb7 + 0x02),然后跟着两字节为0x0400,后面再加上数据串的具体内容。因此增加的首字节的取值范围为[0xb8, 0xbf],因此其能编码的最大数据长度为2^56。
4. 如果是一个嵌套的列表数据,则需要先将列表中的数据按照单元素的编码规则进行RLP编码后串联得到列表数据的payload。如果一个列表数据的payload的字节长度为0-55,那么列表的RLP编码在其payload前加上一个字节,这个字节的值是0xc0加上payload的字节长度。因此首字节的取值范围为[0xc0, 0xf7]。
5. 如果一个列表数据的payload的长度大于55,那么它的RLP编码是在开头增加一个字节,这个字节的值等于0xf7加上列表payload字节长度的二进制编码的字节长度,然后依次跟着payload字节长度部分和payload部分。因此首字节的取值范围为[0xf8, 0xff],因此一个列表中存储的所有元素的字节长度不能超过2^56。
如下是一些RLP编码的参考样例。
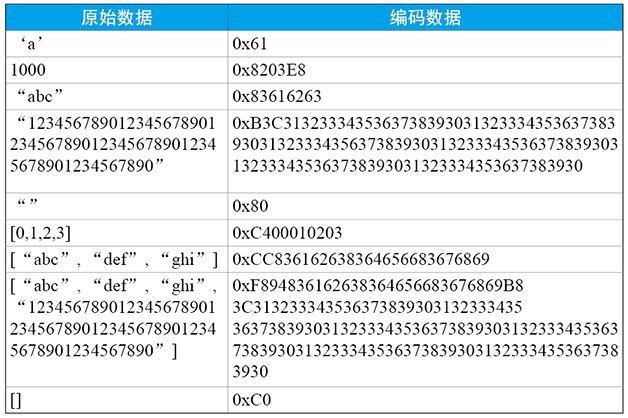
表1 RLP编码样例
以太坊MPT
MPT(Merkle Patricia Tree)是以太坊用来将Key-Value进行紧凑编码的一种数据组织形式。基于该数据组织形式,MPT上任何存储数据的细微变化都会导致MPT的根节点发生变更,因此可以校验数据的一致性。
在MPT中,存在如下三类节点。
1. 叶子节点:用于数据存储的节点。其Key值是一个对应插入数据的特殊16进制编码(需要剔除掉从根节点到当前叶子节点的前缀部分内容),Value值对应插入数据的RLP编码。
2. 扩展节点:扩展节点用来处理具有共同前缀的数据,通过扩展节点可以扩展出一个多分叉的分支节点。其Key值存储的是共同的前缀部分的16进制,Value值存储的是扩展出的分支节点的hash值(sha3(RLP(分支节点数据List)))。
3. 分支节点:由于MPT存储的Key是16进制的编码数据,那么在不具备共同前缀时就通过分支节点进行分叉。分支节点的key是一个16个数据的数组,数组的下标对应16进制的0-F,用来扩展不同的数据。
数组中存储的的是分叉节点的hash值,同时数组的下标也对应一个数据的一个16进制位(4bit)。分支节点的Value一般为空,如果有数据的Key值在其上的扩展节点终止,那么数据Key对应的Value值则存储在分支节点的Value属性上。
扩展节点和叶子节点的Key值前面存在一个4bit或者8bit nibble,用来标示节点类型和后续的数据长度的奇偶性(原始数据Key值16进制后长度为偶数,但是经过扩展节点和分支节点的前缀剔除后剩下的长度可能是奇数,也可能为偶数)。

表2 Nibble取值含义
如下是一个样例数据的MPT形象化表示:
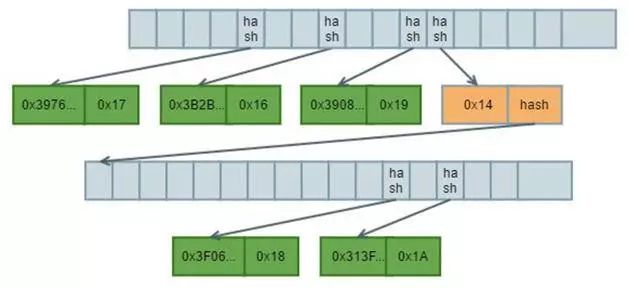
图1 MPT样例结构
该图中蓝色标注的为分支节点;橙色标注的为扩展节点;绿色标注的为叶子节点。
eg:上述样例结构中存储的是如下的Key-Value原始数据:

表 3 原始样例数据
在MPT树上节点存储的数据是原始数据的如下映射:
Key = sha3(原始数据key)
Value = RLP(原始数据Value)
因此在上述样例MPT中,存储的节点数据为如下表格所示:
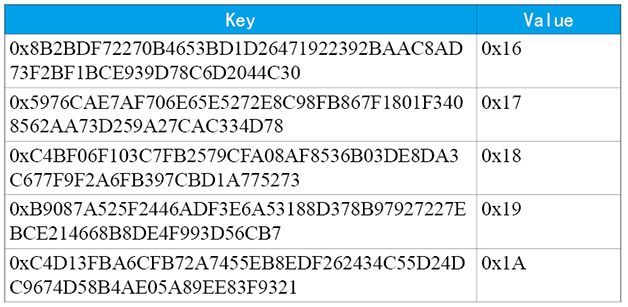
表4 MPT节点数据
上述数据的插入过程如下:
a. 插入[“00000000000000000000000000000022”, 22]
1. 将key值进行sha3求hash值得到
sha3(key) = 0x8B2BDF72270B4653BD1D26471922392BAAC8AD73F2BF1BCE939D78C6D2044C30,将value计算RLP得到 RLP(value) = 0x16;
2. 由于当前没有任何节点,则直接生成一个新的叶子节点,将该节点作为根节点。由于MPT key值长度为偶数,所以在MPT key值前增加16进制nibble值20,得到的树如下:

图2 One Node
b. 插入[“00000000000000000000000000000023”, 23]
1. 将key值进行sha3求hash值得到
sha3(key) = 0x5976CAE7AF706E65E5272E8C98FB867F1801F3408562AA73D259A27CAC334D78,将value计算RLP得到 RLP(value) = 0x17;
2. 当前树只有一个叶子节点,并且两个key的hash值没有公共前缀(一个以8开头,一个以5开头),因此增加一个分支节点用以扩展不同前缀的节点,并且构造两个新的叶子节点挂在分支节点下面。
3. 将上述value为22的key值hash取16进制的首位得到8,那么将key值去掉1位得到
0xB2BDF72270B4653BD1D26471922392BAAC8AD73F2BF1BCE939D78C6D2044C30,去掉1位后由于长度为奇数,那么增加16进制的nibble值 3 ,得到新的叶子节点
[0x3B2BDF72270B4653BD1D26471922392BAAC8AD73F2BF1BCE939D78C6D2044C30, 0x16] 。
4. 将上述新得到的叶子节点作为RLP List进行编码,并计算hash值得到
0xDDCB61885A1C577BE083824D6761932FDCF0A496072A5932B021CD801F65076D,将得到的hash值填入父分支节点的第8位(原有hash值首字符为8)。
5. 同理计算value为23的节点,得到新的叶子节点
[0x3976CAE7AF706E65E5272E8C98FB867F1801F3408562AA73D259A27CAC334D78, 0x17],并计算RLP编码的hash值0xB5BB9644C549233F9B3D462844E565AE9A5EF2D0687DB8739B3FEA5B1260FACF并填入父分支节点的第5位(原有hash值首字符为5)。
6. 得到新的树结构如下:
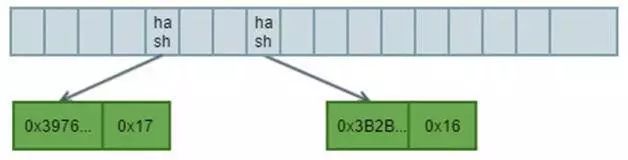
图3 Two Nodes
c. 插入[“00000000000000000000000000000024”, 24]
1. 按照相同的计算规则插入value为24的节点,由于没有共同的前缀,所以在分支节点第12位下增加一个新的叶子节点。
2. 得到新的树结构如下:
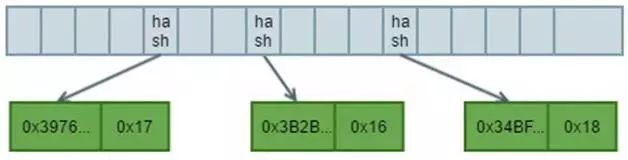
图4 Three Nodes
d. 插入[“00000000000000000000000000000025”, 25]
1. 按照相同的计算规则插入value为25的节点,由于没有共同的前缀,所以在分支节点第13位下增加一个新的叶子节点。
2. 得到新的树结构如下:
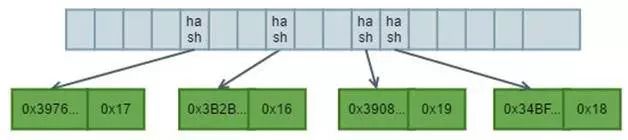
图5 Four Nodes
e. 插入[“00000000000000000000000000000026”, 26]
1. 将key值进行sha3求hash值得到0xC4D13FBA6CFB72A7455EB8EDF262434C55D24DC9674D58B4AE05A89EE83F9321
,将value计算RLP得到0x1A。
2. 根据hash值得首字符“C”查找根节点的插入点为分支节点的第12位,由于在第12位存在了相同的节点(value值为24),由于去掉首字符“C”后还存在共同的前缀“4”,则需要增加一个扩展节点用来存储共同前缀“4”,并且在扩展节点下增加一个分支节点用来扩展后续的不同部分。
3. 将上述value为24的key值hash去掉共同的前缀“C4”并增加nibble后得到节点[0x3F06F103C7FB2579CFA08AF8536B03DE8DA3C677F9F2A6FB397CBD1A775273, 0x18],求其节点RLP的hash值填入新增加分支节点的第11位(去掉共同前缀“C4”后的首字符为B)。
4. 按照相同的计算规则构造value值为26的叶子节点
[0x313FBA6CFB72A7455EB8EDF262434C55D24DC9674D58B4AE05A89EE83F9321, 0x1A],求其节点RLP的hash值填入新增加分支节点的第13位(去掉共同前缀“C4”后的首字符为D)。
5. 调整完上述两个叶子节点后,得到新的分支节点,并计算新的分支节点的RLP Hash值0xD7C0D0160345D3EF2F758D15598965BE1A2C71682995890C5341171EF72A54B2作为value值填入父扩展节点的value部分。
6. 新增加的扩展节点保留共同的前缀“4”(剔除其父分支节点的共同部分“C”),并增加16进制nibble值1,得到其MPT key值为0x14。
7. 计算新的扩展节点的RLP hash值0x7DADADF4464529492D2C475DA62C1F64FAAE150A7355E921E805CF82B5E90A69填入其父分支节点的第12位。
8. 得到新的树结构如下:
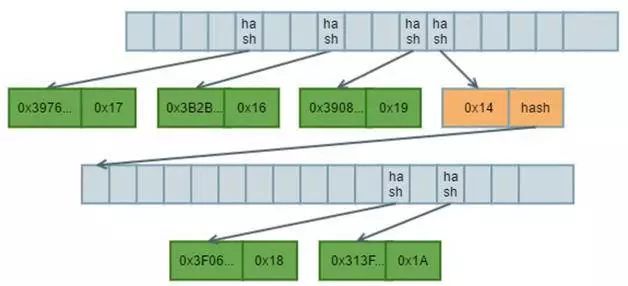
图6 Five Nodes
上述过程是通过新增节点构建一个MPT的过程,存储数据的更新和删除逻辑就不在此累述,读者可以举一反三进行类推。需要注意的是任何数据的更新操作都需要先基于树的检索路径找到对应的节点进行更新,并且从该节点逐层向上调整检索路径上的所有节点直至根节点,中间有可能会涉及到节点类型的调整和节点的合并。
以太坊合约存储规则
以太坊提供了一种图灵完备的虚拟机与智能合约编写规则。我们可以在智能合约中定义复杂的数据模型以及在该数据模型上执行的一系列函数操作。我们知道,以太坊是以Key-value的形式来存储数据的,那么智能合约的复杂数据结构是如何映射到这样的键值对上的呢?
以太坊采用如下的编码规则来将数据结构定义和数据值映射成Key-Value:
1. 智能合约的任何结构都会被映射成[key, value]的形式,其中key和value均是无符号32字节的数据。
2. 所有的存储成员按照成员定义位置从0开始索引编排,每次累加1,作为其对应的key值进行存储。Value为具体的成员属性值。
3. 固定长度数据类型(例如:uint8、uint16、uint32、enum)Value按照32字节右对齐的原则。相邻的存储成员如果其长度不满足32字节,则会将Value进行压缩合并存储。例如如下的变量定义和数据取值:
enum a = 1;
uint8 b = 15;
Key:0x00000000000000000000000000000000000
00000000000000000000000000000
Valu0x00000000000000000000000000000000000
000000000000000
4. 可变长度数据类型(例如:string、bytes)按照左对齐的原则进行编码,如果其长度不大于31字节,则按照一条记录存储,该记录Value的最后一个字节存储其可变内容的实际长度,例如如下的变量定义和数据取值:
string a = "123";
Key:0x0000000000000000000000000000000000
000000000000000000000000000000
Value:0x31323300000000000000000000000000
00000000000000000000000000000006
5. 如果可变长度类型变量的数据内容长度超过31字节,则将会被拆分成多条记录进行存储。第一条记录的key值为其索引编号,Value值为其实际数据长度加1;然后将内容按照32字节拆分成多条记录,每条记录的key值为首条记录key值进行sha3后得到的hash值从0开始每次累加1得到,value值为拆分的内容部分。例如如下的变量定义和数据取值:
string a = "1234567890123456789012345678
901234567890";
Key1:0x000000000000000000000000000000000
0000000000000000000000000000000
Value1:0x0000000000000000000000000000000
000000000000000000000000000000051
Key2:sha3(0x0000000000000000000000000000
000000000000000000000000000000000000)
Value2:0x3132333435363738393031323334353
637383930313233343536373839303132
Key3:sha3(0x0000000000000000000000000000
000000000000000000000000000000000000)+1
Value3:0x33343536373839300000000000000000
00000000000000000000000000000000
6. 针对结构体定义,可以看成将结构体扩展到结构变量定义位置的索引编号进行累加。例如如下的变量定义和数据取值:
struct Data
{
string name;
int age;
}
string a = "1234567890";
Data d;
d.name = "1234567890";
d.age = 3224115;
Key1:0x000000000000000000000000000000000
0000000000000000000000000000000
Value1:0x3132333435363738393031323334353
637383930000000000000000000000014
Key2:0x000000000000000000000000000000000
0000000000000000000000000000001
Value2:0x313233343536373839303132333435
3637383930000000000000000000000014
Key3:0x000000000000000000000000000000000
0000000000000000000000000000002
Value3:0x0000000000000000000000000000000
000000000000000000000000000313233
7. 针对数组定义,则需要扩展多条记录。第一条记录Key值为数组变量的索引,Value值为数组的元素个数。后续则根据数组的元素增加多条记录,每条记录的Key值在首条记录的Key值上做sha3得到hash值从0开始每次累加1,Value值为数组元素的对应值。例如如下的变量定义和数据取值:
string[] cources;
cources[0] = "123";
cources[1] = "456";
Key1:0x0000000000000000000000000000000
000000000000000000000000000000000
Value1:0x0000000000000000000000000000000
000000000000000000000000000000002
Key2:sha3(0x0000000000000000000000000000
000000000000000000000000000000000000)
Value2:0x3132330000000000000000000000000
000000000000000000000000000000006
Key3:sha3(0x000000000000000000000000000
0000000000000000000000000000000000000)+1
Value3:0x343536000000000000000000000000
0000000000000000000000000000000006
8. 针对Map数据定义,其key值则为map key值加上变量索引进行sha3取hash值。例如如下的变量定义和数据取值:
string a;
mapping(string => string) r;
mapping(string => int) s;
r["abc"] = "123";
r["def"] = "123";
s["abc"] = 123;
Key1:sha3(0x61626300000000000000000000000
00000000000000000000000000000000000000001)
Value1:0x313233000000000000000000000000000
0000000000000000000000000000006
Key2:sha3(0x64656600000000000000000000000
00000000000000000000000000000000000000001)
Value2:0x3132330000000000000000000000000000
000000000000000000000000000006
Key3:sha3(0x616263000000000000000000000000
0000000000000000000000000000000000000002)
Value3:0x00000000000000000000000000000000
0000000000000000000000000000007b
以太坊账户结构
在以太坊中,账户信息以Key-Value的形式存储在区块链的数据库中,每个账户通过一个唯一的地址编码作为Key进行标示,Value存储该账户的相关属性、账户余额、合约代码标示、合约存储标示。其结构如下:
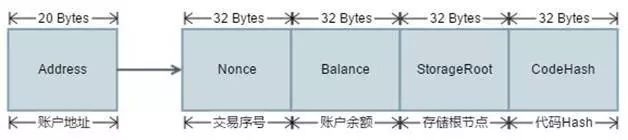
图7 账户结构
1. Address:账户地址,与用户私钥唯一对应的一组20字节的数据串。
2. Nonce:用户账户对应的的交易序列号,每次成功执行交易后累加1。
3. Balance:用于账户对应的账户余额,以wei为单位(1 eth = 1018 wei)。
4. StorageRoot:仅在合约账户上该属性有效,标示合约存储结构的MPT树根节点hash值。
5. CodeHash:仅在合约账户上该属性有效,标示合约代码对应的Hash值。
任何一个以太坊的账户都可以基于其地址在以太坊的数据库中按照MPT树的检索规则找到对应的一条账户存储记录。检索的Key值为账户地址的hash值,检索到的Value值是上述结构的一个RLP编码数据串,可以基于RLP的编码规则逆向解析出其对应的属性值。
以太坊的数据库存储
以太坊用NoSQL数据库以Key-Value的形式存储所有的数据。针对账户数据结构,需要存储的数据主要包含智能合约的Storage和基本的账户信息。对应的存储规则如下:
1. 针对智能合约Storage,将数据按照编码规则映射成MPT,然后将MPT的所有节点的Key和Value构建一个RLP List编码作为数据库存储的Value值,将该Value值进行Sha3计算hash值作为数据库存储的Key值进行存储。
2. 针对基本账户信息,将其对应智能合约Storage的MPT Root Hash保存于账户的StorageRoot属性,然后将系统中的所有Account构建一个MPT。按照和Storage的数据库存储方式将MPT的所有节点进行存储。
上述构建的两个MPT树的结构如图8。
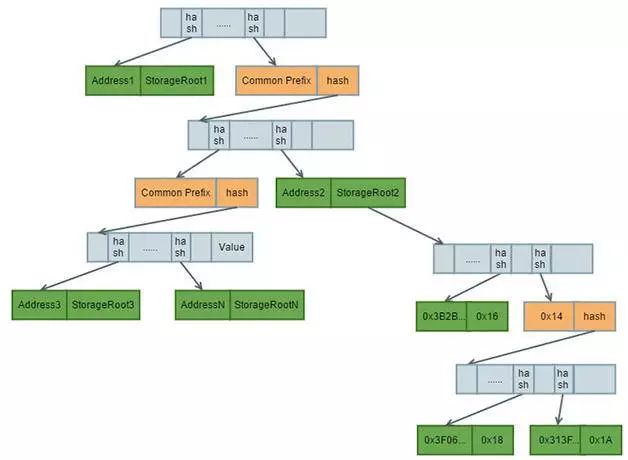
图8 Account & Storage MPT
结论
以太坊的账户以Hash散列与RLP数据编码为基础,结合智能合约的数据对象映射和转换,将Key-Value的数据以MPT的方式进行组织,计算StorageRoot唯一证明并保存于账户模型。最终形成Storage和Account两种MPT,并将MPT的所有节点以Key-Value的形式存储于NoSQL数据库中。这样的编码存储方式可以快速的校验智能合约和账户数据是否发生了变更,进而只需要对比MPT根节点的差异就可以快速校验区块链上分布式节点数据的一致性。
后记
在深刻理解了以太坊的存储模型和原理机制后,可以在某些方面扩展以太坊的能力实现更加丰富的功能集。例如:
1. 实现可视化的工具,完成对以太坊LevelDB数据库的数据解析和呈现。借助智能合约的存储定义,结合账户的StorageRoot遍历LevelDB数据库中的Key-Value键值对,根据编码规则实现数据逆向分析和展示,为DApp应用的开发调试提供更加方便快捷的数据操作。
2. 智能合约的升级一直是一件令开发者颇为头疼的事情,如何保证在完成智能合约的缺陷升级后还能维系访问原有的留存数据就是一个切实的痛点。借助对智能合约的存储机制,可以考虑在以太坊中扩展功能,支持智能合约的升级,并将原有的智能合约StorageRoot迁移复制给升级后的智能合约账户。在满足特定的数据定义要求下,可以达到智能合约升级后的数据平滑迁移效果。
3. 以太坊的数据存储方案并不是最完美的解决方案,因为MPT的特性,海量数据存储账户的更新操作会带来指数级的数据存取,这样会让以太坊的智能合约执行变得非常低效。是否存在可能的解决方案,将海量的数据存储脱离MPT的方式的,提升数据存取的效率,是值得思考的一个问题。
上述的内容只是在以太坊数据存储模型上的简单思考和一些引子,起到抛砖引玉的效果。希望读者能有更新颖的想法和灵感。
作者简介:邓福喜,矩阵元技术(深圳)有限公司的系统架构师。作者在分布式系统和互联网应用的架构设计与研发方面有10多年的从业经验,目前主要从事区块链底层技术平台的设计与研发工作,邮箱[email protected]。
本文首发《程序员》