Drools 规则引擎——向领域驱动进步
1.复杂事件处理
到目前为止,我们已经看到如何使用规则,以基于数据(我们称呼它为fact)来做出决定。这个信息几乎是任何一组Java对象,它们描述了我们正在做决策的域的状态,但是它总是在一个特定的时间点上代表这个世界的状态。本章我们将会去看一些列的概念,配置和规则语法组件,他们可以允许你基于事实数据之间的时间关系做出决定。这个概念也被称为complex event processing(CEP)
Drools以Drools Fusion或Drools CEP的名义提供支持, 一个概念模块完全集成到Drools的核心特性中。这只是概念上的分离,因为所有CEP特性都由提供规则引擎功能的相同模块完全支持。为了完全理解这一点,本章将涵盖以下主题:
>讨论与复杂事件处理相关的不同概念,包括滑动窗口、入口点和时间操作
>将复杂的事件处理装配为一种称为事件驱动架构的特殊架构
>编写规则并配置运行时以充分利用Drools CEP特性
1.1 什么是复杂事件处理
CEP的主要关注点是在不断变化的、不断增长的数据云中,将基于时间的数据关联起来,以便发现难以发现的特殊情况,并为这些情况做些事情。为了充分理解它的工作原理,我们首先需要定义一些其他的概念。让我们从定义事件开始。
1.1.1 什么是事件和复杂事件??
为了了解事件,让我们先谈一个熟悉的概念。到目前为止,我们已经讨论了插入到一个Kie session中的事实数据以及它们如何匹配一个特定的规则。事实数据与事件非常相似,除了事件有一个额外的特征:发生的时间。事件仅仅是关于任何域(表示为Java对象)的数据,以及关于该信息是真实的时间的信息。
在特定的时间里,我们记录的任何事情都可以是一个事件,如下:
>我们的eShop限时折扣
>电话呼叫有一个开始时间和一个结束事件
>任何一种传感器读数都会告诉你它的特定读数(温度、湿度和运动)与特定时刻的关系
事件本身是事件处理的基本结构。我们从外界获得的每一个输入都可以被看作是一个事件。然而,我们将主要关注于检测复杂事件。
一个复杂事件就是一个简单的聚合,组合,或者其他事件的抽象。复杂事件处理的真正威力来自于能够将简单的传入事件关联起来,这样我们就可以检测复杂的情况,而这些情况是无法由任何设备或个人直接检测到的,如下所示:
>我们在某一特定时刻所拥有的所有事务都可以被关联起来,以检测任何可能的欺诈行为(并采取先发制人的措施)。
>在呼叫中心,根据特定区域分组的所有传入调用,可以确定这些区域的服务中断情况,从而自动通知用户。
即使是传感器读数,在很大程度上,也可以通过简单的事件组合来检测复杂的情况。让我们考虑一组传感器读数,作为我们的输入事件。一组地震事件可以告诉我们这座城市发生了什么地震以及它的强度。一组火警警报可以告诉我们在城市里哪里有火灾。
在发生大地震的情况下,结合城市基础设施的信息,我们可以推断出可能发生的结构性崩溃,并派专家来评估当前的形势。如果我们有火警警报,我们就可以派消防队去灭火。
如果我们发现一组小地震,一个接一个,在一秒内,在同一个方向上,我们可以推断出一个很大的大地震正朝着这个方向移动.如果我们也探测到火灾,一个接一个地在同一个方向上,我们可能会把所有的地震和火灾警报事件集合成一个复杂的事件,也许哥斯拉正在朝这个方向移动,如下图所示:
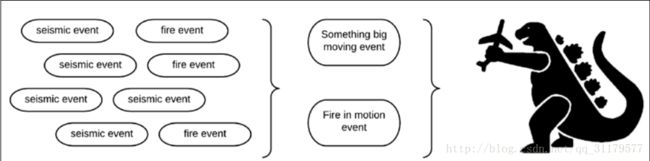
如果是这样的话,我们可能就不希望把架构师和消防队送到那个大方向(他们很可能会被吃掉)。相反,我们可能采取不同的行动,比如派遣军队。正如您所看到的,非常小的简单事件可以使我们能够从这些事件中推断出更多的信息。这是复杂事件处理的主要功能。
1.2 阐述基于CEP的规则
在此之前,我们已经讨论了规则应该如何尝试变为原子性,并一起工作以实现复杂场景的管理。这与CEP很好地结合在一起,因为每个不同的规则都可以处理聚合、组合或其他事件的抽象的一个方面。他们可以一起工作来实现非常复杂的事件的实时解决方案。我们仍然需要一些Drools的附加功能来做到这一点,如下:
>如何指导Drools一个对象被视为一个事件
>如何及时的比较两个事件的
在下一小节中,我们将看到如何使用DRL语法实现此目的。
1.2.1 事件的语义
在我们详细讨论如何定义一个事件之前,我们㤇理解事件的一些特点。第一个特征是两种主要类型的事件——准时和间隔事件之间的区别——如下所示:
>Punctual events(准时事件):它们是在某个特定实例中发生的事件。它们可能代表了我们的领域模型出现了变化的确切时刻,或者它们的生命周期太短而不能被考虑。准时事件的一个例子是传感器读数,它会将传感器的特定值与读数的特定时间相关联。如果时间太短,事务也可以被认为是准时的事件,我们可以忽略它们的持续时间。
>间隔事件:它们是有两个独特时刻的事件:一是开始的时刻,二是结束的时刻。这使得间隔事件比准时事件要复杂一些;如果你有两个准时的事件,你只能比较它们是在同一时间,还是在之前,还是在彼此之后发生的。另一方面,对于间隔事件,您可以比较一个事件在另一个事件中开始和结束的情况,只是为了命名一个场景。
另外,无论什么是准时或间隔事件,它们都有一组概念特征,在我们查看代码之前,它们都是值得提及的。
>他们通常是不可变的:事件应该是我们的领域模型在某个特定时刻的状态的记录。你不能改变过去,因此,你不应该改变你的事件信息。引擎没有强制这个功能,但是在设计我们的活动时,它是要记住的。它们可能通过向它们添加额外的信息来修饰,但是您不需要修改它们在Kie session中插入的内部数据。
>他们有被管理的生命周期:由于引擎将所有事件都理解为具有时间关系的对象,因此Kie session可以根据其定义的规则确定事件何时不再触发规则,并可以从会话中自动删除它。
1.2.2 阐述Drools的time-based-events
为了创建CEP规则,我们需要做的第一件事是指定需要将对象作为事件处理的对象的类型.也就是说,对象应该有时间元数据。这将允许Kie session对这些类型应用时间推理。有几种方法可以用来定义特定的类型应该作为事件处理看待,但是它们都定义了相同的元数据集。要定义的属性如下所示:
>类型的角色:这是唯一的强制元数据,用于定义一个事件的类型。它将有两个特定类型:事实和事件
>时间戳:这是定义类型属性的可选属性,它将定义事件发生的时刻。如果不存在,则每个事件实例的时间戳将是插入到Kie session中的时间。
>持续时间Duration:这是一个可选属性,用于定义指定事件持续时间的类型的属性。如果不赋值,该活动将被视为一个准时的活动。这个属性对于间隔事件是必需的。
>到期Expires:这是一个可选的字符串,以确定在自动删除之前,这个类型的事件应该在多长时间内出现。
现在我们了解了这些属性,让我们看看将它们应用到我们的类型的不同方法。该元数据可以直接定义为Java bean中的类级注解,如下:
@org.kie.api.definition.type.Role(Role.Type.EVENT)
@org.kie.api.definition.type.Duration("durationAttr")
@org.kie.api.definition.type.Timestamp("executionTime")
@org.kie.api.definition.type.Expires("2h30m")
public class TransactionEvent implements Serializable {
private Date executionTime;
private Long durationAttr;
/* class content skipped */
}正如您在前面的代码部分中看到的,我们可以为事件类型的角色、持续时间、时间戳和过期属性定义注释。Duration持续事件属性应该确定一个Long类型的属性,时间戳则是确定一个Date类型的属性。通过这种方式,Kie session将能将插入的上述所指定的对象,看做是一个事件。
定义这些属性的另一种方法是声明类型。类似的注释可用于将声明类型定义为事件,如下:
declare PhoneCallEvent
@role(event)
@timsstamp(whenDidWeReceiveTheCall)
@expires(2h30m)
whenDidWeReceiveTheCall:LOng
callInfo:String
end
上述的代码段展示了我们如果创建我们的声明类型,并且对他进行注解,使其成为一个事件。
声明事件的另一种方法是获取一个已存在的类,并将其声明为DRL中的一个事件。当在不同的系统之间我们需要创建事件去共享,但是我们不能直接修改这些类,使其具有这些事件注解。这时候我们可以像下面代码这样,声明一个已经存在的java类为一个事件:
import path.to.my.shared.ExternalEvent;
...
declare ExternalEvent
@role(event)
end就像上面代码展示的,我们可以在DRL文件内,重新声明没有被注解的java类,使其成为一个事件。正如上文所言,所有的这些注解都是可选的。将一个类声明为一个事件所必须的注解就是@role(event)注解,你可以参考chapter-06/chapter-06-events项目的代码样例。
现在我们已经了解了如何声明事件类型,我们需要开始查看如何比较它们。为了实现这一操作,我们将回顾现有的时间运算符。
1.2.3 运算符
一旦我们定义了我们自己的事件类型,我们需要一种能够方式来基于这些事件的时间戳进行比较。为了这样,我们可以在Drools里使用13运算符。有的运算符只对比较区间事件有意义,但是给予两个事件,他们可以将它们与以下代码片段进行比较:
declare MyEvent
@role(event)
@timestamp(executionTime)
End
rule "my first time operators example"
when
$e1: MyEvent()
$e2: MyEvent(this after[5m] $e1)
Then
System.out.println("We have two events" +
" 5 minutes apart");
end在上面的样例中,我们使用了after操作符,来决定一个事件是否至少比以往的某一个事件新5分钟以上。正如你所见,比较是在特定的事件实例上进行的。在内部,时间比较会发生在被称为executionTime的时间戳属性上,但是在处理事件时我们可以忽略这个事实。如果我们需要修改事件类型的时间戳特性,这就提供了一个优势,因为我们不需要改变使用它的CEP规则。
此外,我们还可以注意到在运算符中使用参数,在方括号内传递。每个时间操作符将准备接收0到4个参数,以更具体的方式使用操作符。在前面的场景中,我们传递了一个5m参数,以指定一个事件应该在另一个事件发生后至少5分钟。
有很多我们可以工作的时间运算符。以下是他们的一份清单和他们的意思:

前面的图显示了不同的时间操作符,以及它们如何在不同的事件之间进行比较。他们都有某些特质,如下所示:
>他们都是操作两个事件。这些操作符都准备着与另一个事件进行比较。
>它们还可以用来比较Date对象,根据定义,它是事件的最简化的表示形式(只有时间信息,而不需要额外的数据)。
>它们可以接收参数来指定它们的内部工作。这些参数的操作在https://docs.jboss.org/drools/release/latest/drools-docs/html/的Temporal Operators主题得到了充分的解释。
关于事件值得一提的一点是,它们仍然是事实数据。引擎将把时间特性添加到事件类型,但是我们仍然可以比较它们的内部属性和方法来创建规则的条件和约束,就像我们在前几章中所做的那样。为了熟悉CEP规则,让我们分析一下我们在chapter-06/chapter-06-rules代码包中可以找到的一个规则,它的目的是检测欺诈行为,如下:
rule "More than 10 transactions in an hour from one client"
when
$t1: TransactionEvent($cId: customerId)
Number(intValue >= 10) from accumulate(
$t2: TransactionEvent(this != $t1,
customerId == $cId, this meets[1h] $t1),
count($t2) )
not (SuspiciousCustomerEvent(customerId == $cId,
reason == "Many transactions"))
then
insert(new SuspiciousCustomerEvent($cId,
"Many transactions"));
end这个例子DRL文件可以子在 chapter-06-rules/src/main/resources/chapter06/cep/cep-rules.drl里找到。为了运行这个例子,我们从前面定义的TransactionEvent事件类型开始。在我们的规则中,我们将检查两件主要的事情:一个小时内是否有10个来自同一客户的事务,并且我们仍然没有一个复杂的事件来反映这种情况。
第一个条件写在一个accumulate累积中。我们计算包含相同客户ID的TransactionEvent对象的数量,并且使用 this meets [1h] $t1来检查是否发生在原始参考交易的一个小时内。
这条规则的结果并不是针对外部的特别行动。相反,我们只是发现了一个复杂的事件,叫做SuspiciousCustomerEvent(是我们样例中所声明的一个类型)。这将表示交易事件的聚合。
第二段条件是一个简单的not字句,我们只是通过SuspiciousCustomerEvent对象来检查我们还没有为特定的客户启动这条规则,如果还没有添加的话,我们需要在结果中添加。
这个规则只会检测到这种情况,因为这是我们可以将其分解为最小的责任。我们可以对可疑的客户做很多事情,但是这条规则只负责理解一个特定的情况,即客户行为可疑。我们需要记住始终保持我们的规则尽可能的原子化。其他规则可能通过其他方法检测客户的可疑活动。
一旦检测到可疑的客户,另一条规则可以在检测到一些可疑的客户事件时决定要做什么。对于这种情况,我们将创建一个不同的规则:
rule "More than 3 suspicious cases in the day and we warn the owner"
when
SuspiciousCustomerEvent($cId: customerId)
not (AlarmTriggered(customerId == $cId))
Number(intValue >= 2) from accumulate(
$s: SuspiciousCustomerEvent(customerId == $cId),
count($s)
)
then
//warn the owner
System.out.println("WARNING: Suspicious fraud case. Client " + $cId);
insert(new AlarmTriggered($cId));
end如前所述,我们可以有多个规则来检测可疑的客户活动。当两个或多个规则被相同的客户触发时,该规则将触发.一旦发生这种情况,我们就向所有者发出警告。在这个例子里,它被表示为一个简单的系统输出,但它也可以很容易地成为一个助手方法或全局变量方法,用来发送电子邮件或SMS。
正如我们从前面的示例中可以看到的,我们可以将复杂的事件处理案例分解成多个规则,每个规则都通过它所消耗或产生的事件连接到CEP场景的其余部分。这些事件的聚合为我们的系统提供了一种特殊的体系结构,事件及其与隔离的应用程序组件之间的关系使我们能够创建非常分离的、高度可扩展的组件。这个体系结构称为事件驱动体系结构,我们将在下一小节中描述它。
1.3 事件驱动架构
事件驱动的体系结构是一种非常容易与CEP结合的概念,因为它定义了一个简单的体系结构来促进生产、检测、消费和对事件的反应。此体系结构的概念是将应用程序组件作为四个可能的元素之一,相关的内容如下图所示:
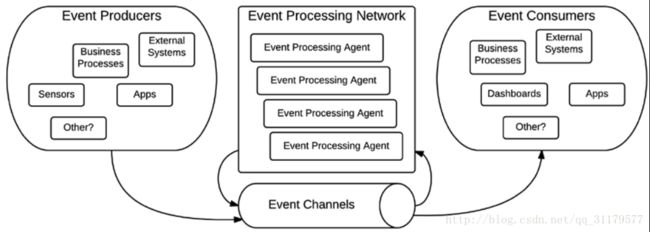
事件驱动架构(EDA)的概念是将以下四个不同类别的组件分类:
| 组件分类 | 描述 |
|---|---|
| Event Producer | 他们在EDA中的作用完全是为了创造事件,所有能产生事件的东西都被认为是生产者,无论它是基于硬件的传感器、应用程序收集请求、业务流程,或者任何其他形式的应用程序,可以将一个新事件引入到我们的体系结构中。 |
| Event Consumer | 他们在EDA中的角色是倾听其他组件产生的事件。它们还可以从各种各样的组件,从应用程序的简单监听器到复杂的仪表板。它们通常表示该体系结构的最终输出,并将生成的值指向外部世界。 |
| Event Channels | 它们是所有其他组件之间的通信协议。事件通道封装了用于将事件从一个组件传输到另一个组件,从一个传输传感器读数的武力电线传输到逻辑组件的任何组件,例如一个Java消息服务队列。 |
| Event Processing Agents | 这些是组织事件来检测和处理复杂事件的核心组件。在Drools里,处理CEP的每一条规则都被认为是事件处理代理。对更复杂的情况进行检测和反应的分组称为事件处理网络。 |
在设计一个围绕复杂事件处理的系统时,这个体系结构是一个非常有用的概念。它可以很容易地集成到任何其他类型的体系结构中,因为它只关心事件如何与组件互连,从而为各种其他特性留出空间。
大多数开始使用CEP的应用程序需要考虑,在设计阶段,有一个概念类似于EDA提出的一个概念,即多个事件生产者连接到一个事件处理代理(即我们的规则)的网络,并将数据生成给多个事件使用者。Drools通过称为入口点的组件提供了源多元化的概念,我们将在下一小节中讨论它。
1.3.1 将事件源与入口点分开
在Drools中提供入口点作为分区工作内存的一种方法。每一个Kie session可以有多个入口点,它可以用来确定传入数据的来源。对于复杂的事件处理,入口点是为事件定义多个源的一个很好的方法。
为了将任何类型的对象插入到一个入口点,我们所需要做的就是使用以下的API:
KieSession ksession = …; //kie session initialization
ksession.getEntryPoint("some entry point").
insert(new Object());前面的代码部分只有在我们在DRL文件中声明一个入口点时才会起作用;否则,它将抛出一个异常。声明和使用入口点可以直接在任何规则中发生。它们可以在规则的条件或结果中使用,如下面的例子所示:
rule "Routing transactions from small resellers"
when
t: TransactionEvent() from
entry-point "small resellers"
then
entryPoints["Stream Y"].insert(t);
end在前面的规则,我们过滤从 small resellers这个入口点传入的TransactionEvent对象。然后,在结果中,我们将把每一个匹配事件插入到另一个叫做Stream Y的入口点。正如您可以看到的,我们可以创建尽可能多的入口点来分割我们信息的来源。
插入一个入口点的事件永远不会失去对它的引用。这意味着,Kie session将把不同的入口点作为完全不同的事件组对待。在您的规则中,您需要指定您想要过滤数据的入口点,以及您想要修改数据的入口点。但是,您可以在一个规则中交叉引用来自多个入口点的信息,也可以在入口点和常规工作内存之间交叉引用。
您可以在CEPEntryPointsTest类上看到一个在不同入口点工作的规则示例。它在 chapter-06-tests项目下。在这个例子里,我们使用两个入口点去将传入的事务分为“big client”和“small client”.每个人都会有不同数量的交易他们会认为是可疑的,因此,每个人用不同的规则来处理这个案例.
1.3.2 滑动窗口
Drools CEP特性的另一个非常有用的概念是使用滑动窗口。因为事件有一个时间戳,它们也有一个固有的顺序。我们可以通过这个特殊的顺序过滤来自工作内存或任何入口点的事件。我们有两种滑动窗口,如下:
>Length-based滑动窗口
>Time-based滑动窗口
1.3.2.1 Length-based滑动窗口
最简单的滑动窗口是基于长度的滑动窗口。您可以使用它来指定插入到流中的最后N个元素。每当将一个新事件添加到流中,窗口的最后一个元素就会被一个新的元素所取代。使用基于长度的滑动窗口是很容易的。下面的规则显示了一个简单的方法来声明一个滑动窗口来从工作内存中获取TransactionEvent类型的最后6个事件:
rule "last 6 transactions are more than 100 dollars"
when
Number(doubleValue > 100.00) from accumulate(
TransactionEvent($amount: totalAmount)
over window:length(6),
sum($amount)
)
then
//... TBD
end在前面的规则中,我们将汇总最后6个事务的所有金额,并在这个金额超过100美元的情况下触发规则。为了得到最后的6个事务,我们使用一个滑动窗口。
如果在TransactionEvent类型的工作内存中有6个或更少的元素,那么这个窗口将包含所有元素。当我们添加第七个TransactionEvent对象时,我们只会得到这个滑动窗口返回的最后6个对象。这就是为什么它被称为滑动窗口。您将只看到一个特定的事件组,每次您添加一个新事件时,窗口将会移动来查看符合条件的最后一个元素。
1.3.2.2 Time-based滑动窗口
可以创建一个类似的窗口,它将返回从现在开始的特定时间内发生的任何元素。这是通过一个基于时间的滑动窗口完成的。让我们来看看下面这个例子:
rule "obtain last five hours of operations"
when
$n: Number() from accumulate(
TransactionEvent($a: totalAmount)
over window:time(5h),sum($a)
)
Then
System.out.println("total = " + $n);
end在前面的示例中,我们会得到在从现在到过去5小时前之内的交易。如果一笔交易发生在5个小时1秒只前,它将不再活跃在这里。在这段时间内,无论我们是有一个交易还是有500个交易,时间窗口将包含所有这些事务。
PS:请注意,这个窗口将随着Kie session的内部时钟而滑动,我们将在本章后面的《使用会话时钟进行测试》这一部分中看到如何在测试中进行配置。
1.3.2.3 声明滑动窗口
滑动窗口通常在使用它们的规则中定义。这是一个很常见的做法,因为它本来是使用滑动窗口的唯一方法。 然而,这就导致了需要从同一个窗口中过滤元素的规则,在每个规则中都必须重新定义它。如果我们这样定义滑动窗口,并且以后需要改变我们使用的窗口的性质,例如 将一个基于长度的滑动窗口转换为基于时间的滑动窗口,我们必将编辑所有使用它的规则。为了避免这样做,Drools有一个特性 被称为窗口声明。
窗口声明允许我们去定义一个窗口作为一个预创建组件,并通过名字,被任意数量的规则调用。这样就允许我们在声明窗口内进行改变,这个窗口仅仅在此处声明一次,被多个规则之间共享。其语法如下:
declare window Beats
@doc("last 10 seconds heart beats")
HeartBeat() over window:time( 10s )
from entry-point "heart beat monitor"
end然后,规则可以通过引用这个名称来使用声明的窗口,如下面的例子所示:
rule "beats in the window"
when
accumulate(
HeartBeat() from window Beats,
$cnt : count(1)
)
then
// there has been $cnt beats over the last 10s
end如你所见,窗口声明允许简单的重用窗户,甚至是为特定入口点声明初始公共过滤器。这可以避免重写许多规则,这些规则可能共享一个逻辑上相同的滑动窗口。
1.4 运行CEP-based场景
现在我们已经看到了CEP规则的主要组件,我们需要开始关注在Drools中成功运行CEP场景所需的一些配置步骤。运行CEP案例的KieBase和session都需要特殊的管理,我们将在下一小节中看到,如下所示:
>如何配置基基以支持复杂事件处理
>连续和离散规则执行的区别
>Kie session内部时钟如何计算时间事件
1.4.1 流处理配置
为了创建CEP Drools运行环境,我们需要从默认的初始化中提供一些额外的配置。我们需要添加的第一个是我们将要使用的Kie base的事件处理模式。
事件处理模式将决定在运行时中插入的新数据的处理方式。默认的事件处理模式称为CLOUD模式,基本上以相同的方式处理任何传入的数据,而不考虑事件还是简单的事实数据。这意味着运在行时将不去理解事件的概念,因此我们不能将其用于CEP。
我们需要配置我们的Kie base以使用STREAM事件处理模式。该配置将通知运行时,它应该管理事件,并根据时间戳将其内部排序。由于这一排序,我们能够对事件运行时间操作,并在其中使用滑动窗口。有许多方法可以在Kie Base中配置STREAM事件处理模式。最简单的方法是直接在kmodule.xml中作为kbase标签的一个属性来配置:
通过这种方式,我们稍后可以直接从对应的Kie Container中使用Kie Base或Kie session,而其运行时的配置将使用流事件处理模式。我们可以看到这个配置的一个例子,位置在chapter-06/chapter-06-rules/src/main/resources/META-INF/kmodule.xml。
配置此事件处理模式的另一种方法是编程方式。这样做的话,我们将会使用到 KieBaseConfiguration这个实体Bean以及他的setOption方法,如下:
KieServices ks = KieServices.Factory.get();
KieContainer kc = ks.getKieClasspathContainer();
KieBaseConfiguration kbconf = ks.newKieBaseConfiguration();
kbconf.setOption(EventProcessingOption.STREAM);
KieBase kbase = kc.newKieBase(kbconf, null);在上一个例子中,我们使用了Kie的类路径容器来简化,但我们可以使用任何Kie Container来创建KieBase。它在定义动态知识模块时非常有用。
一旦我们定义了一个基于STREAM处理模式的Kie base,我们就需要了解不同的选项,我们将需要运行一个Kie session并管理我们的CEP场景。
1.4.2 连续的和离散的规则触发
当运行我们的CEP规则时,我们首先需要理解的是,我们是否需要以连续或离散的方式运行它们。两者之间的主要区别如下:
>离散规则触发将在特定时间点触发规则。我们的应用将会添加事件和事实数据进Kie session,在一个特定的点,它将会使用 fireAllRules方法触发任何与工作内存相匹配的规则
>连续规则触发将有一个特定的线程,用于在某些数据与规则匹配时触发规则。它将使用Kiesession的 fireUntilHalt方法来实现这一点,而一个或多个其他线程将把事件和事实插入到Kie session中。
这两种触发规则的方式完全取决于我们的情况和可能触发规则的情况。如果我们有一个场景,没有事件会触发一个规则,或者换句话说,没有事件可以被抽象成另一个事件,那么您应该使用连续规则触发。另一方面,如果能触发新规则的唯一因素是将新事件插入到Kie session中,那么对于我们的情况来说,离散规则的触发就足够了。
让我们来讨论几个例子来理解这两个场景。
首先,让我们讨论一下离散规则触发的常见情况:欺诈检测。大多数欺诈检测系统将根据来自交易的累积信息工作。基本上,如果我们有特定数量的具有特定参数的交易,我们可能会考虑欺诈的可能性。在这种情况下,我们触发规则的唯一方法是插入一个新交易来匹配规则的条件。对于这种情况,我们可以在每次交易或交易批插入到我们的Kie session时调用fireAllRules。如果在添加最新数据后不立即执行规则,就不需要触发任何规则。
在另一个场景中,让我们想象一个心脏监视器正在向我们的CEP引擎发送事件。大约每隔一秒,我们就会从示波器上获得心跳。如果我们获取事件的时间靠的过近或者不规律,我们可能会发现中风或者心律不齐的复杂事件。如果我们想检测心脏停止跳动会发生什么?这将是一个心脏骤停事件。如果我们想发现它,我们的系统将需要在没有事件发生时触发规则的能力。这种类型的场景是连续规则触发案例的典型特征。
1.4.3 使用会话时钟进行测试
当创建Kie Sessions来运行基于cep的场景时,一个更有用的配置是配置其内部时钟。默认方式,Kie Session将会用其运行所在的机器的时钟来理解时间的流逝。然而,这只是两个可用配置中的一个,称为运行时时钟。另一个允许我们定义一个受应用控制的始终的配置,叫做配置虚拟时钟。
运行时和虚拟时钟都 只向一个方向移动(往前走)。但是,如果您调用一个特定的称为advanceTime的方法,那么伪时钟就会这样做。这里有一个小的例子,说明如何在KIe session中使用虚拟时钟:
SessionPseudoClock clock = ksession.
getSessionClock();
clock.advanceTime(2, TimeUnit.HOURS);
clock.advanceTime(5, TimeUnit.MINUTES);在前面的例子中,我们告诉时钟要提前2小时5分钟。这两个调用只需要几毫秒的时间,这使得这个时钟成为测试CEP场景的一个极好的选择如果您必须检查两个事件(它们被插入到Kie session中),其中两个事件的默认时间戳间隔两个小时,那么虚拟时钟会让您几乎立即运行这个案例,运行时时钟至少需要两个小时。
为了在我们的基会话中使用伪时钟,我们需要通过kmodule.xml文件为它提供一个特定的配置:
我们甚至可以通过KieSessionConfiguration bean来使用它:
KieServices ks = KieServices.Factory.get();
KieContainer kc = ks.getKieClasspathContainer();
KieSessionConfiguration ksconf = ks.
newKieSessionConfiguration();
ksconf.setOption(ClockTypeOption.get(
ClockType.PSEUDO_CLOCK.getId()));
KieSession ksession = kc.newKieSession(ksconf);样例代码在 chapter-06-test项目下。
即使虚拟时钟最常见的用途是测试,但它通常使用的另一种情况是分布式生产环境。这样做的原因是,在大型环境中,CEP场景可能在多个服务器中执行,而虚拟时钟通常用于在不同的服务器中轻松地同步所有会话的时钟。一个额外的线程或服务器可以在几乎相同的时间内调用每个服务器上的定时的机制,并且每个服务器都有一个Kie session可以提前确保它们都在几乎相同的时钟值上运行。这通常比让多个服务器的内部时钟同步更简单,这是规则负责实时决策时的一个要求。
1.5 Drools CEP的局限性
Drools CEP的功能非常强大,并且能够像其他类型的基于Drools的规则一样快速地解决决策问题。但是,它有一些我们需要注意的架构元素,以便充分利用它。
首先,所有的Kie session都在内存中运行。这意味着所有的生存在Kie session中的事件都在内存中,而它们仍然与Kie Base中的至少一个规则相关。这可以通过一个事件类型的@expires注释来克服,但是它仍然需要预先规划定义Drools CEP服务所需的内存数量。一个快速逇方式来确定在一个服务端运行一个Drools CEP需要有多少内存:
>确定每个事件实例在Kie SESSION中应该存在多长时间(因为它可能仍然用于触发规则)。我们称这个值为a。
>确定在特定时间段内可以接收到多少事件。我们称其为B
>确定事件实例的大小.我们称其为C
A * B * C = X,一个非常粗略的估计所需的最少的内存Kie session保持所有生活事件的参考。我们还需要小心,因为我们还没有考虑到存储在规则条件和Beta网络之间的事件之间的存储的内存消耗。我们将在之后的PHREAK介绍中,提及这个知识点。
另一个需要考虑的限制是在任何持久性机制中存储Kie session的可能性。当它的内部表示发生变化时,无论它是工作内存或者是它的匹配agenda,Kie session通常是持久化了的。对于常规的CEP场景,这可能意味着在每次规则触发或插入新事件时都要存储所有的工作内存数据。使用基于CEP的Kie session进行这样的操作,可能意味着每秒存储数gb的数据。因此,需要在另一个系统中复制一个Kie session的其他机制。
目前,唯一可以复制一种基于CEP的KIE session的方法是在Kie session之间复制小的增量(不需要复制整个工作内存)以及制定规则的协调策略(因此,只有一个复制的Kie session实际上会为复制的匹配数据触发规则)。这些都是定制的机制,每个用户都应该根据自己的风险来实现自己的功能,因此,建议的替代方案是按域分解CEP场景,并让不同的服务器只处理一组案例。
为此,通常第一步是根据数据中的类型或特定组件对事件进行过滤,并将其转发给特定的Kie session,以便在特定的情况下管理特定的场景。
举例来说,在服务器中处理来自小型提供商的所有欺诈检测案例,并在两个专用服务器上进行欺诈检测。即使是过滤也可以是一个无状态的会话,创建了将每个事件重定向到相应的Kie Stateful session,如下图所示

通过这种方式,可以在Drools CEP会话中实现事件吞吐量的增加,并通过添加额外的服务器来处理(至少在某种程度上)。