机器学习方法概论
基本概念
学习的定义(Herbert A. Simon)
如果一个系统能够通过执行某个过程改进它的性能,这就是学习。
机器学习的定义(Tom Mitchell)
A program can be said to learn from experience E with respect to some class of task T and performance measure P, if its performance at tasks in T, as measured by P, mproves with experience E.
假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。
机器学习的目标
基于数据构建模型,并运用模型对数据进行预测与分析。
机器学习的基本假设
- 数据具有统计规律性,可用随机变量描述数据中的特征,用概论分布描述数据的统计规律。
- 数据之间符合独立同分布(i.i.d)。
- 要学习的模型属于某个函数的集合,称为假设空间
统计机器学习的三要素
模型、策略和算法,方法 = 模型+策略+算法。
机器学习的基本步骤:
- 得到一个有限的训练数据集合;
- 确定包含所有可能的模型的假设空间,即学习模型的集合;
- 确定模型选择的准则,即学习的策略;
- 实现求解最优模型的算法,即学习的算法;
- 通过学习方法选择最优模型;
- 利用学习得到的最优模型对新数据进行预测或分析。
统计机器学习的分类
监督学习,非监督学习,半监督学习和强化模型。
监督学习中,根据输入变量X和输出变量Y的类型分类
- X和Y均为连续变量称为回归问题。
- Y为有限个离散变量称为分类问题。
- X和Y为变量序列称为标注问题。
模型
条件概率分布P(Y|X)或者决策函数Y=f(X)。
策略
用损失函数(loss function)或者代价函数(cost function)来度量预测错误的程度,常用的损失函数包括:
- 0-1损失函数:

- 平方损失函数
![]()
- 绝对损失函数
![]()
- 对数损失函数
![]()
输入输出遵循联合概率分布P(X,Y),模型的期望损失如下:
![]()
模型f(X)在训练集上的平均损失称为经验风险如下:
![]()
当样本容量足够大,经验风险最小化能保证很好的学习效果,在现实生活中被广泛采用。
当损失函数为对数损失函数时,经验风险函数就是极大似然函数。
按照经验风险最小化求解的模型如下:
![]()
![]()
为了防止过拟合,在经验风险上加上表示模型复杂度的正则化项,称为结构风险。
正则化项能控制模型的复杂度,结构风险最小化需要经验风险和模型的复杂度同时小。
贝叶斯估计中的最大后验概率估计(MAP)就是结构风险最小化的例子。
按照结构风险最小化求解的模型如下:
![]()
![]()
算法
线性模型存在解析解
梯度下降算法
模型评估
模型在训练集上的误差称为训练误差,在新样本上的误差称为泛化误差。
学习算法的能力,数据的充分性和学习任务本身的难度共同决定了模型的泛化性。
模型的性能度量
性能度量是衡量模型泛化能力的评价标准。
回归任务中最常用的性能度量是均方误差。
![]() 判别模型的均方误差如下:
判别模型的均方误差如下:

概率模型的均方误差如下:
![]()
分类任务中常用的性能度量有:错误率E、精确率acc、混淆矩阵、查准率P、查全率(召回率)R、P-R曲线、F1度量、Fbeta度量、ROC曲线、代价曲线。
错误率:
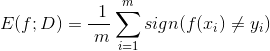
![]()
混淆矩阵:
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率:
![]()
查全率:
![]()
PR曲线:

F1和Fbeta:
![]()
![]()
![]()
ROC曲线:
根据模型预测的结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,得到真正率TPR和假正率FPR,以TPR和FPR作为横、纵坐标表进行作图,得到ROC曲线。
![]()
![]()

在P-R曲线和ROC曲线中,若一个模型的曲线将另一个模型的曲线完全包住,则可以断言前一个模型优于被包住的模型。
查得又准又全的模型才是好模型。
统计假设检验对模型的泛化性能比较提供了重要的依据。基于假设检验的结果,我们可以推断出,若在测试集上观察到模型模型A优于模型B,则A的泛化性能是否在统计意义上优于B,以及这个结论的把握有多大。
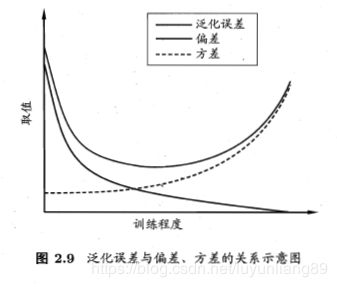
模型的期望泛化误差可以分解成偏差、方差和噪声之和。
![]()
偏差方差窘境
训练/验证/测试集划分方法
训练(S)/测试(T)集的划分要尽可能保持数据分布的一致性,常用的训练集和测试集划分方法如下:
- 留出法
采用分层采样的方法按一定比例(7:3)划分S和T,例如数据集D包含500个正例和300个反例,则分层采样得到的S应包括350个正例和210个反例,T应包括150个正例和90个反例,且采样时要保证样本的随机性。
- 交叉验证法
将D划分为K个大小相似的互斥子集,即![]() ,然后每次用k-1个子集的并集作为训练集,将余下的那个子集作为测试集,最终返回的是这K个测试结果的均值。常用的K值取10,即10折交叉验证。
,然后每次用k-1个子集的并集作为训练集,将余下的那个子集作为测试集,最终返回的是这K个测试结果的均值。常用的K值取10,即10折交叉验证。
- 自助法
有放回抽样得到S,T = D\S作为测试集,这样的测试结果,也称为包外估计。自助法在数据集较小,难以有效划分训练/测试集时很有用,但是有放回抽样改变了初始数据集的分布,会引入估计偏差,因此该方法不常用。·
验证集
在研究对比不同算法的泛化性能时,用测试集上的判别效果来估计模型在实际使用时的泛化能力。
在面对算法的超参数选择时,将原训练集划分为新的训练集和验证集,基于验证集上的性能进行模型的选择和调参。
最终模型
在模型选择完成后,学习算法和参数配置已选定,此时应该用全体数据集D重新训练模型。
参考书籍:
《机器学习》 周志华
《统计机器学习》 周航