自动驾驶-利用卷积神经网络和对交通标志分类
#利用卷积神经网络对交通标志分类
上一章总结了神经网络算法的基本概念,本章在此基础上介绍在图像分类任务中使用的神经网络算法:卷积神经网络(CNN), 然后介绍tensorflow的基本用法,最后会给出在tensorflow上使用卷积神经网络算法对交通标志进行分类的步骤和部分源码。
##卷积神经网络
神经网络每一层生成的新的神经节点作为新的特征输入下一层,从而能够处理较复杂的任务,但是处理图像分类的任务时,一副图像的每一个像素点都是输入层的一个特征,都需要一个独立的权重,如果使用多层的神经网络,由于权重过多,不仅训练花费时间极高,而且对内存一会产生加大的消耗。
生物学家通过对动物大脑的研究发现动物识别物体时会从简单的线条开始逐步抽象出更高层次的物体,受此启发,计算机科学家发明了一种卷积神经网络的算法,对图像从最简单的线条开始识别,逐步识别出更复杂的目标物体。例如要识别下图中的金毛,在眼睛鼻子首位先提取出一些曲线最为第一层的输出,第二层组合这些曲线继续提取特征,根据一条曲线和两个鼻孔提取出鼻子的特征输出到下一层,继续组合和提取特征,在最后一层组合眼睛,鼻子等特征识别出金毛。
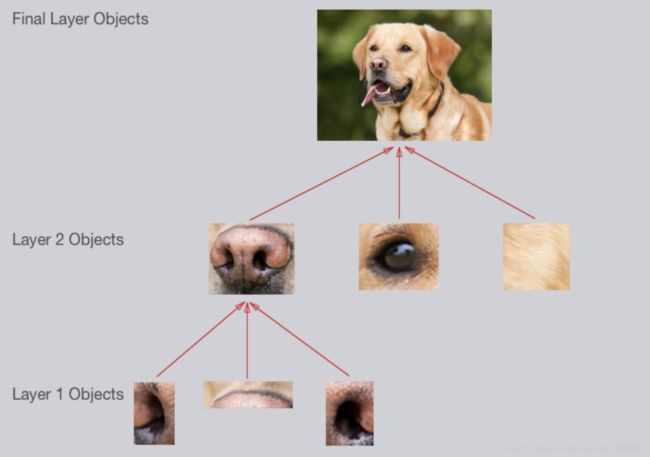
卷积将相邻的像素当作一个集合进行处理,这就是卷积和非卷积神经网络的区别,卷积神经网络使用滤波器提取图像的局部特征,这更复合人们的认知,因为一副图像的局部像素的相关性更加紧密,例如上图提取鼻子的特征时,只需要整幅图像的中间的一部分像素,而其他像素都为干扰项,非卷积网络的每一层特征都会影响下一层特征的提取,于是增加了很多干扰项,降低了特征提取的准确度。
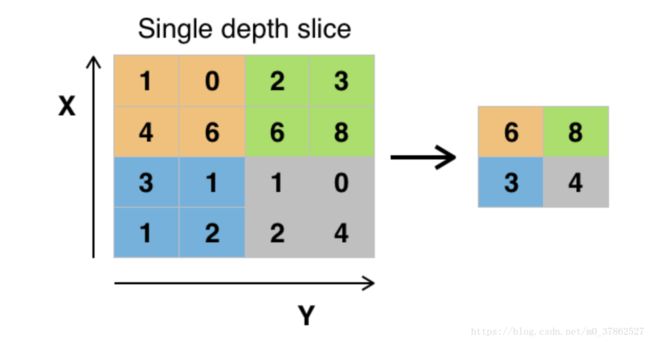
使用卷积神经网络一般分为两步,第一步先定义一组相同大小的滤波器,然后使用滤波器滑过图像,做卷积运算。使用多个滤波器是为了提取多个特征,例如下图提取嘴部特征时,可以提取的特征包括牙,舌头,嘴唇等;第二步对输出做池化(pooling)处理,池化是指对一定范围内的像素做处理,提取一个特征来取代范围内的其他特征,可以进一步较少减少神经元的个数,防止过拟合,本章使用最大值池化方法。最大值池化(maxpooling)是指在一定范围内提取值最大的特征值代替这一范围内的其他特征,平均值池化(averagepooling)是指去一定范围内的均值最为这个范围的新的特征。下图所示为一个maxpooling的例子。
一般构建卷积神经网络模型时,每一个卷积层需要定义的参数有patch,stride,padding,
其中patch定义了滤波器的大小和深度,深度表示每一个卷积层滤波器的个数,stride表示滤波器每次卷积滑过图像的像素数,padding有valid padding和same padding两种,valid padding是指滤波器只在图像内滑动,所以输出会比原始图像尺寸小,samepadding会对图像进行扩充,这样在新的输出保持和当前输入相同的规模。
以下是使用卷积神经网络训练图像对每一卷积层提取特征可视化的结果。
从图一可以看出,第一层识提取了 4 5 ∘ 45^{\circ} 45∘的直线,第二层提取了稍复杂的曲线,最后一层提取了目标目标物的基本轮廓。

dropout
dropout是一种为防止过拟合采用的办法,dropout在输入层和隐藏层使用掩码屏蔽一部分输入对输出的影响,最简单的一种dropout方法是使非输出层的输出单元乘0,从而从神经网络中删除该节点。如下图所示,第一层第2,3个节点乘0,则下一层生成的节点便不再受这两个节点的影响。

总结: 卷积神经网络使用和神经网络相同的优化参数的算法,区别是使用过滤器提取图像局部特征。由于图像的局部范围像素间相关性大,可以是特征提取更加准确;另外,使用过滤器可以是每一层权重共享,减少了需要训练的参数,降低了训练时间和内存占用。池化进一步减少了特征数量,并降低了干扰项对特征的影响,提高了算法的鲁棒性。
tensorflow介绍
关于tensorflow的背景知识网上已经有很多的介绍,这里不再赘述,本节是为下一节使用tensorflow构建卷积神经网络完成图像分类任务做铺垫,所以只对下一节需要通道的tensorflow的相关函数功能做简要说明。关于函数更详细用法可以参考这里
##关键函数含义说明
#变量定义
import tensorflow as tf #导入tensorflow
constant = tf.constant('Hello world') #定义常量
variable = tf.Variable() #定义变量, 例如权重,截距
x = tf.placeholder() #定义占位符,在程序运行时赋值,一般表示数据集的特征和标签
y = tf.placeholder()
tf.truncated_normal() #按一定分布随机赋值,一般用于权重初始化
y_one_hot = tf.one_hot(y,n_class) #将分类的标签转换为独热码形式
#基本操作
tf.add(x,y),tf.sub(x,y),tf.mutiple(x,y),tf.divid(x,y) #加减乘除操作
tf.matmul(X,W) #矩阵相乘
#卷积神经网络基本操作
tf.nn.conv2d(x,w,strde=None,padding='VALID') #卷积操作
tf.nn.relu() #激活函数
tf.nn.dropout() #dropout操作,一般用来防止过拟合
tf.nn.maxpooling() #pooling操作
tf.contrib.layers.flatten() #将多维矩阵转换为1维向量,一般用于卷积层导权连接层的转换
#定义优化器
#卷积神经网络模型
logits = LeNet(x)
#使用交叉熵定义代价函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits, one_hot_y)
#对代价函数求平均
loss_operation = tf.reduce_mean(cross_entropy)
#定义优化器
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
#执行
with tf.Session() as sess: #定义一个sess对象,程序执行完毕可以自动关闭
sess.run(training_operation, feed_dist={x:x_trian,y:y_train}) #导如dataset并开始训练
##lenet5模型
def LeNet(x):
# Hyperparameters
mu = 0
sigma = 0.1
# SOLUTION: Layer 1: Convolutional. Input = 32x32x3. Output = 28x28x6.
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 1, 6), mean = mu, stddev = sigma)) #a little change
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
# SOLUTION: Activation.
conv1 = tf.nn.relu(conv1)
#Add Dropout Layer
conv1 = tf.nn.dropout(conv1, keep_prob)
# SOLUTION: Pooling. Input = 28x28x6. Output = 14x14x6.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Layer 2: Convolutional. Output = 10x10x16.
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
# SOLUTION: Activation.
conv2 = tf.nn.relu(conv2)
#Add Dropout Layer
conv2 = tf.nn.dropout(conv2,keep_prob)
# SOLUTION: Pooling. Input = 10x10x16. Output = 5x5x16.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Flatten. Input = 5x5x16. Output = 400.
fc0 = flatten(conv2)
# SOLUTION: Layer 3: Fully Connected. Input = 400. Output = 120.
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# SOLUTION: Activation.
fc1 = tf.nn.relu(fc1)
# SOLUTION: Layer 4: Fully Connected. Input = 120. Output = 84.
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 84), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(84))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# SOLUTION: Activation.
fc2 = tf.nn.relu(fc2)
# SOLUTION: Layer 5: Fully Connected. Input = 84. Output = 43.
fc3_W = tf.Variable(tf.truncated_normal(shape=(84, 43), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(43))
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
##训练步骤
- 数据分组,这一步要将数据集中的数据范围三组,第一组为训练集,第二组为验证集,第三组为测试集。一般的机器学习任务是使用训练集训练模型,然后使用测试集测试模型准确率,为什么要用三组数据集呢?这是由于在训练时需要使用训练集和验证机的准确率来判断模型是过拟合还是欠拟合,一边调整模型的结构,最终训练的模型一定在训练集和验证集上表现良好,这是由于我们在选择模型是偏好使用能够在两种数据集上表现好的模型,所以还需要测试集来评估训练模型的泛化能力;
training_file = "traffic-signs-data/train.p"
valid_file = "traffic-signs-data/valid.p"
testing_file = "traffic-signs-data/test.p"
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
with open(valid_file,mode='rb') as f:
valid = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_validation,y_validation =valid['features'],valid['labels']
X_test, y_test = test['features'], test['labels']
- 数据预处理,由于数据集的特征的数量级可能差异较大,在训练模型时,数量级大的特征会在模型产生较大的影响,并使学习速度变慢,所以在训练模型前要对数据进行归一化处理,使所有特征值在0~1之间。
def CovToGray(data):
for index in range(0,data.shape[0]):
for channel in range(0,2):
data[index,:,:,channel]= cv2.cvtColor(data[index], cv2.COLOR_BGR2GRAY)
return data[:,:,:,0:1]
X_train = X_train.astype('float32')
X_validation = X_validation.astype('float32')
X_test = X_test.astype('float32')
X_train = X_train / 255 - 0.5
X_validation = X_validation / 255 - 0.5
X_test = X_test / 255 - 0.5
X_train = CovToGray(X_train)
X_validation = CovToGray(X_validation)
X_test = CovToGray(X_test)
- 构造和训练模型,本文采用lenet模型训练数据集,lenet模型前一节已给给出,滤波器的规模略有调整。训练集共有35000例样本,内存放不了这种规模的数据量,所以将训练集分为若干子集,分批进行训练。
EPOCHS = 50
BATCH_SIZE = 64
X_train, y_train = shuffle(X_train, y_train)
X_validation,y_validation = shuffle(X_validation,y_validation)
X_test, y_test = shuffle(X_test, y_test)
x = tf.placeholder(tf.float32, (None, 32, 32, 1))
y = tf.placeholder(tf.int32, (None))
one_hot_y = tf.one_hot(y, 43)
keep_prob = tf.placeholder(tf.float32)
#TRAINING
rate = 0.001
logits = LeNet(x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits, one_hot_y)
loss_operation = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
#MODEL EVALUATION
X_train, y_train = shuffle(X_train, y_train)
X_validation,y_validation = shuffle(X_validation,y_validation)
X_test, y_test = shuffle(X_test, y_test)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(one_hot_y, 1))
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
#sess = tf.get_default_session()
#with tf.Session() as sess:
for offset in range(0, num_examples, BATCH_SIZE):
batch_x, batch_y = X_data[offset:offset+BATCH_SIZE], y_data[offset:offset+BATCH_SIZE]
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 1})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examples
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train)
print("Training...")
print()
for i in range(EPOCHS):
X_train, y_train = shuffle(X_train, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 0.5})
validation_accuracy = evaluate(X_validation, y_validation)
Train_accuracy = evaluate(X_train, y_train)
print("EPOCH {} ...".format(i+1))
print("Validation Accuracy = {:.3f}".format(validation_accuracy))
print("Train Accuracy = {:.3f}".format(Train_accuracy))
print()
saver.save(sess, 'lenet_traffic_sign')
print("Model saved")
- 测试模型,使用测试集测试模型表现,以上模型在数据集上测试结果准确率为93.1%
#EVALUATION
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('.'))
test_accuracy = evaluate(X_test, y_test)
print("Test Accuracy = {:.3f}".format(test_accuracy))
本文只给出了部分代码,完整代码请戳这里。
以上使用机器学习算法对卷积神经网络进行训练项目的一次总结,项目的内容来自udacity的自动驾驶课程,上一章关于神经网络的基础知识来自coursea的机器学习课程。