python抓取并分析日志样本
背景
最近需要帮我哥做个python小功能,功能的目的就是分析现有的一堆access日志文件(不包含实时增量分析,仅针对固定样本日志,约400mb),从中查找出包含某一关键字的日志,并提取ip出来,统计同一ip出现的次数。
功能分析
遍历日志文件逐行加载日志- 分析每行中是否包含
关键字 - 包含关键字的日志行用
正则表达式提取ip 统计ip出现的次数- print
输出结果到txt文件 excel>数据>从文本/csv导入,导入并分析
目录结构
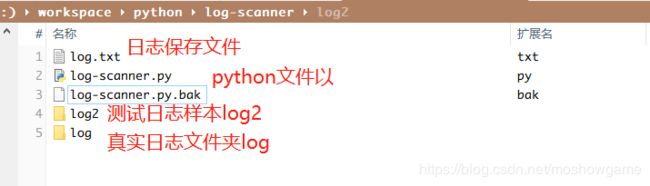
- 新建一个
log.txt文件用于保存记录 - 新建一个
log-scanner.py用于编写代码 - 新建
log2仅保存1个日志样本 - 新建
log文件夹保存所有待分析日志
代码Show
以下代码做了保密处理,待查找的字符串已经替换为zhengkai.blog.csdn.net,具体业务场景具体实现,这里也可能是做其他的一些分析场景,且分析的日志也不一定是accesslog,也可以是控制台输出等等,总之,demo要易懂,思路要活跃。
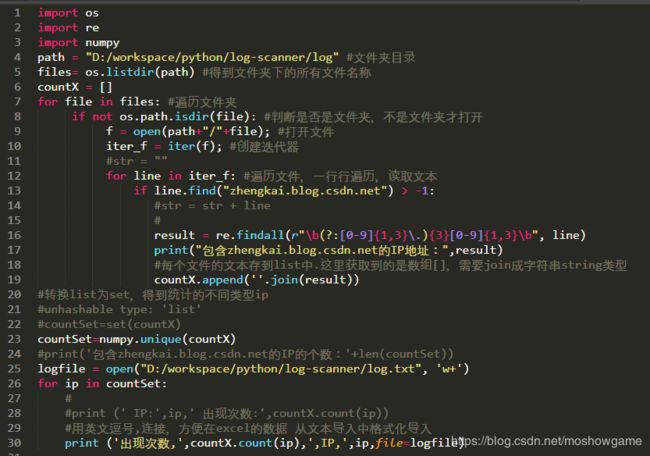
import os
import re
import numpy
path = "D:/workspace/python/log-scanner/log" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
countX = []
for file in files: #遍历文件夹
if not os.path.isdir(file): #判断是否是文件夹,不是文件夹才打开
f = open(path+"/"+file); #打开文件
iter_f = iter(f); #创建迭代器
#str = ""
for line in iter_f: #遍历文件,一行行遍历,读取文本
if line.find("zhengkai.blog.csdn.net") > -1:
#str = str + line
#
result = re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b", line)
print("包含zhengkai.blog.csdn.net的IP地址:",result)
#每个文件的文本存到list中.这里获取到的是数组[],需要join成字符串string类型
countX.append(''.join(result))
#转换list为set,得到统计的不同类型ip
#unhashable type: 'list'
#countSet=set(countX)
countSet=numpy.unique(countX)
#print('包含zhengkai.blog.csdn.net的IP的个数:'+len(countSet))
logfile = open("D:/workspace/python/log-scanner/log.txt", 'w+')
for ip in countSet:
#
#print (' IP:',ip,' 出现次数:',countX.count(ip))
#用英文逗号,连接,方便在excel的数据 从文本导入中格式化导入
print ('出现次数,',countX.count(ip),',IP,',ip,file=logfile)
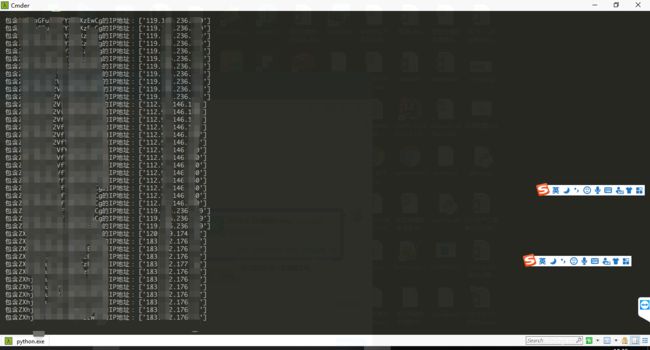
输出情况
可以看到控制台输出以下内容
接着,在excel中进行导入,找到数据栏目,选择从txt/csv导入,确认分隔符等信息。
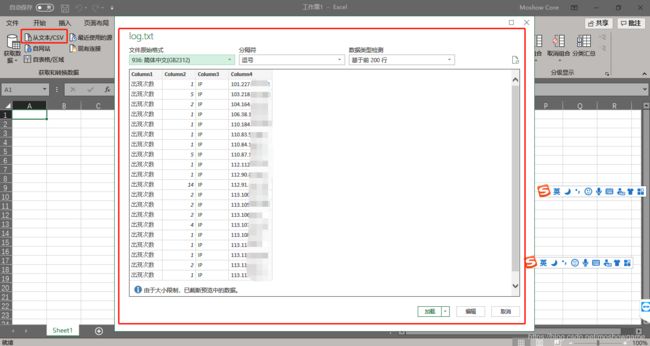
查看分析结果
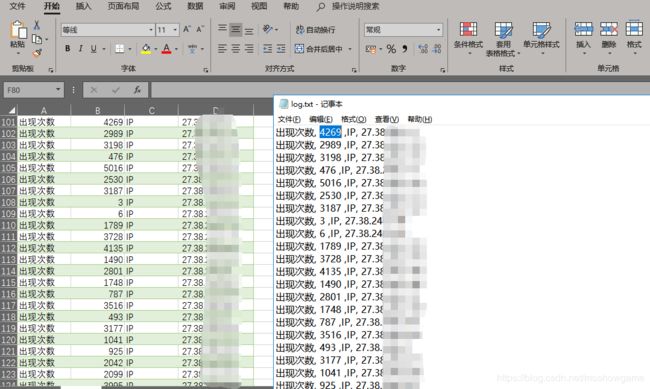
后言
其实很多地方还可以改进的,例如末尾加多一个print(‘日志分析完成’),添加日志分析进度条等。或者用python库直接输出到excel表也是ok的,这个等有空再深入研究,谢谢大家的查看。