稳定匹配问题(FROM Gale-Shapley TO 匈牙利算法)
稳定匹配问题(FROM Gale-Shapley TO 匈牙利算法)
匈牙利算法可以參考本片博客:(https://www.jianshu.com/p/cb685445e8b1)
盖尔沙普利算法原理:
初始化所有 m ∈ M , w ∈ W , m \in M,w \in W, m∈M,w∈W,所有的m和w都是自由状态;
while(存在男人是自由的,并且他还没有对每个女人都求过婚)
{
选择一个这样的男人m;
w = m的优先选择表中还没有求过婚的排名最高的女人;
if(w 是自由状态)
{
将 (m,w) 的状态设置为约会状态;
}
else /* w 已经和其他男人约会了*/
{
m’ = w 当前约会的男人;
if(w 更喜爱 m’ 而不是 m)
{
m 保持单身状态(w 不更换约会对象);
}
else /* w 更喜爱 m 而不是 m’*/
{
将 (m,w) 的状态设置为约会状态;
将 m’ 设置为自由状态;
}
}
}
输出已经匹配的集合S
盖尔沙普利算法原型就是解决婚姻匹配的问题,以上便是其精髓。能够轻松正确的
理解了上面的算法,你才有可能理解下面介绍的匈牙利算法(针对作者本人而言 ^ _ ^ )
匈牙利算法:
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。(以上来自百度)废话不多说,直入主题。
先来看几个概念:
1、二部图: 二部图是这样一个图,它的顶点集合V可以划分为X和Y两个集合,它的边集合E中的每条边都有一个端点在X集合,另一个端点在Y集合。如下图:
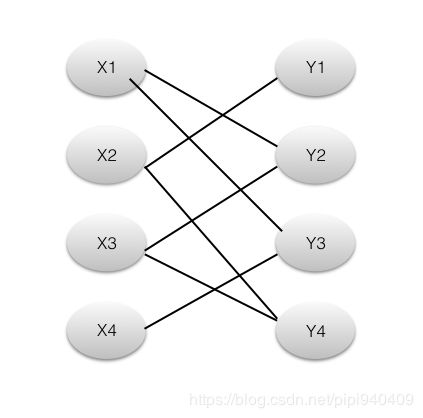
2、匹配: 在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。
3、最大匹配: 一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。如下图:
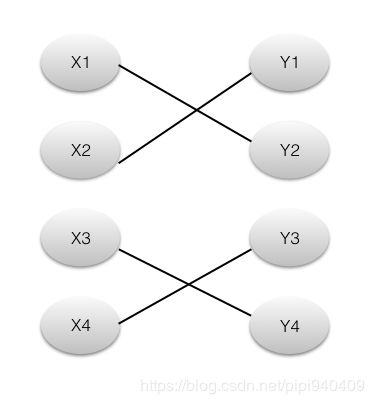
4、完美匹配: 当M是二部图的最大匹配且没有未覆盖点的时候,则这个集合M就是二部图的完美匹配。上图中的匹配就是完美匹配。
最后一个最关键的概念:增广路径 ;
5、增广路径: 具有如下特点:
1-P的路径长度必定为奇数。
2-起点在左,终点在右。
3-路径中的点左右交替出现。
4-只有起点和终点是未覆盖点,其他点都配对。
5 -对增广路径编号,所有奇数的边都不在M中,偶数边在M中。
6 -对增广路径取反得到的匹配比原来匹配多一个。
来个实例,寻找下图的最大匹配:
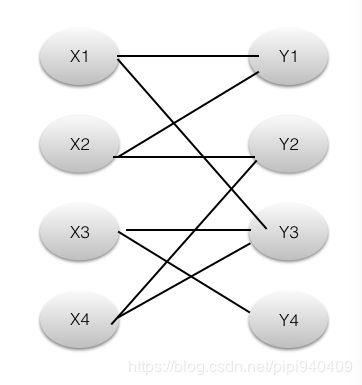
首先M集合为空(即没有边在里面),然后开始从X1寻找增广路,遵循2的原则我们只能在Yi中找,找到Y1,(X1,Y1 )这条路径,满足1-5的条件,取反,将(X1,Y1 )这条路径加入到M中。
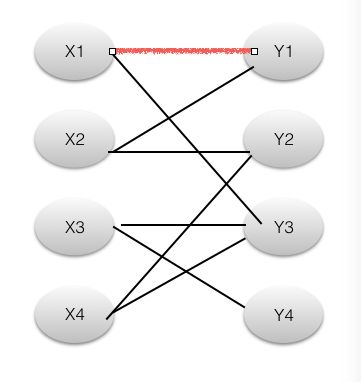
接着,我们找到X2点,遵循原则,找到Y1。但是Y1不是未覆盖点,所以(X2,Y1)不是增广路,但是Y1连着X1,X1又和Y3相连,我们考虑( X2,Y1,X1,Y3 )。这条路径,奇数?左右交替?起终点未覆盖?奇路径不属于M偶路径属于?满足所有增广路条件,所以这是一条增广路径,然后取反,得到如下图。
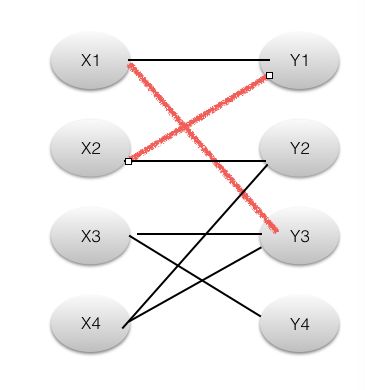
增广路径是匈牙利算法的核心,每找到一条增广路径,意味这M集合中边的数量就会增加1,当找不到增广路径的时候,这个时候M中边的数量就是我们二部图的最大匹配数量。
当我们从X2开始寻找时,我们找到了Y1。但Y1不是未覆盖点,则我们考虑Y1原有的匹配点X1。从X1我们开始找增广路,找到了Y3,当X1有增广路的时候,加上(X1,Y1)原来X1的增广路,再加上(X2,Y1) 现X2的增广路,依然满足增广路条件。形成了(X2,Y1)—(Y1,X1)—(X1,Y3)新的增广路,伪代码如下:
while(找到Xi的关联顶点Yj)
{
if(顶点Yj不在增广路径上)
{
将Yj加入增广路
if(Yj是未覆盖点或者Yj的原匹配点Xk能找到增广路径)
{ //扩充集合M
将Yj的匹配点改为Xi;
返回true
}
}
返回false
}
这里时C代码实现:
typedef struct tagMaxMatch{
int edge[COUNT][COUNT]; //顶点与边的关系表,用来表示二部图。
bool on_path[COUNT]; //表示顶点Yj是否已经在当前搜索过程中形成增广路径上了
int path[COUNT]; //当前找到的增广路径
int max_match; //当前增广路径中边的条数
}GRAPH_MATCH;
void outputRes(int *path){
for (int i = 0 ; ion_path[j] = false;
}
}
//dfs算法
bool FindAugPath(GRAPH_MATCH *match , int xi){
for (int yj = 0 ; yj < COUNT; yj++) {
if ( match->edge[xi][yj] == 1 && !match->on_path[yj]) { //如果yi和xi相连且yi没有在已经存在的增广路经上
match->on_path[yj] = true;
if (match->path[yj] == -1 || FindAugPath(match,match->path[yj])) { // 如果是yi是一个未覆盖点或者和yi相连的xk点能找到增广路经,
match->path[yj] = xi; //yj点加入路径;
return true;
}
}
}
return false;
}
void Hungary_match(GRAPH_MATCH *match){
for (int xi = 0; xipath);
}
int main() {
GRAPH_MATCH *graph = (GRAPH_MATCH *)malloc(sizeof(GRAPH_MATCH));
for (int i = 0 ; i < COUNT ; i++) {
for (int j = 0 ; j < COUNT ; j++) {
graph->edge[i][j] = 0;
}
}
graph->edge[0][1] = 1;
graph->edge[0][0] = 1;
graph->edge[1][1] = 1;
graph->edge[1][2] = 1;
graph->edge[2][1] = 1;
graph->edge[2][0] = 1;
graph->edge[3][2] = 1;
for (int j = 0 ; j < COUNT ; j++) {
graph->path[j] = -1;
graph->on_path[j] = false;
}
Hungary_match(graph);
}
至此,匹配相关的问题就介绍完了,希望上面的内容对大家有帮助。
原文链接: 原文参考