基于stacking骨龄分类
个人主页
代码结构
GitHub地址

文件主入口为 classifier_collection.py。以下出现的代码片断若无说明都来自该程序。
序言
深度学习或机器学习一般处理步骤:
- 探索数据可视化(Exploratory Visulization)
- 数据清洗(Data Cleaning)
- 特征工程(Feature Engineering)
- 基本建模&评估(Basic Modeling & Evaluation)
- 参数调整(Hyperameters Turning)
- 集成方法(Ensemble Methods)
本实验图像分类由以下几个过程组成:
- 数据抽取
- 数据扩充
- 数据处理
- k-fold划分训练集
- 数据格式转换
- 训练模型, 预测剩余fold并保存预测值
- 训练融合模型
- 使用训练好的神经网络模型对测试集进行预测
- 使用7得到的融合模型对8步中得到的预测值进行预测得到最终图像分类
1. 数据抽取
1.1 数据分析
数据分析代码在 tool/analyze.py 里
模块导入:
# coding:UTF-8
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="white", color_codes=True)
数据读取,打印前五行
bone = pd.read_csv(r'C:\Users\Yauno\Downloads\rsna-bone-age\boneage-training-dataset.csv')
bone.head()
print(bone.head()) # 打印前5排数据
输出结果:
id boneage male
0 1377 180 False
1 1378 12 False
2 1379 94 False
3 1380 120 True
4 1381 82 False
查看男女各年龄分布:
# 男女各年龄分布图
csv_data = pd.DataFrame(bone)
bone_x, bone_male_y_dict, bone_female_y_dict = [], {}, {}
for i in range(len(csv_data)):
bone_age = csv_data['boneage'][i]
is_male = csv_data['male'][i]
# print(is_male)
if bone_age not in bone_x:
bone_x.append(bone_age)
if is_male == True:
bone_male_y_dict[bone_age] = bone_male_y_dict.get(bone_age, 0) + 1
else:
bone_female_y_dict[bone_age] = bone_female_y_dict.get(bone_age, 0) + 1
# print(bone_male_y_dict)
# print(bone_female_y_dict)
bone_x.sort()
bone_male_y, bone_female_y = [], []
# print(bone_x)
for i in bone_x:
bone_male_y.append(bone_male_y_dict.get(i, 0))
bone_female_y.append(bone_female_y_dict.get(i, 0))
# print(len(bone_x) == len(bone_male_y))
fig, (axs1, axs2) = plt.subplots(1, 2, figsize=(15,15))
axs1.scatter(bone_x, bone_male_y, color="k")
axs1.set_title('male')
axs1.set_xlabel('bone_age')
axs1.set_ylabel('total')
axs2.scatter(bone_x, bone_female_y, color="red")
axs2.set_title('female')
axs2.set_xlabel('bone_age')
axs2.set_ylabel('total')
plt.show()

由上图可以看到大部分年龄段图片数量很少,不仅会降低精确度,还会影响后面k-flod划分训练集。至于为什么会影响,后面说。
箱线图
# 箱图+数据分布散点图
ax = sns.boxplot(x="male", y="boneage", data=bone)
ax = sns.stripplot(x="male", y="boneage", data=bone, jitter=True, edgecolor="gray")
plt.show()
显示结果

1.2 训练集与验证集划分
由上面分析结果可以看出各年龄段数据分布严重不均衡,所以在划分训练集的时候要考虑到训练集必须包括所有年龄段。
代码及参数说明
数据抽取的原接口程序为 tool/get_data.py
代码

返回的数据类型看原接口,每个训练集与验证集文件夹下都对应着标签标签名为 labels.txt。由于数据中的分类不是从0开始,所以在数据抽取过程中对分类进行重新编号,最后得到的分类编号在 input_para['lables_output'] 下面。
参数

这里的几个输入输出路径不用讲,要讲的为:
- threshed :k-fold参数,在这里的意思为划分k-fold的时候要保证一个年龄段的图片数量要大于等于k-fold,只有这样才能让每fold里都有图片,即使只有一张也可以,因为可以通过后面数据扩充来保证训练集数量
- train_size : 训练集与验证集划分比例 0.9 表示训练集与验证集比例为 9:1
- is_write=False : 因为后面需要对训练集进行数据扩充所以被划分的训练集图片暂时以列表保存并返回, 而不实际保存到指定路径,这样可以缓解存储压力而且加快数据抽取速度。
结果

2. 数据扩充
原接口程序 tool/pic_data_augmentation.py

参数讲解:
- input_file_list : 需要数据扩充的图片路径列表,此处由数据抽取返回的结果处理获得
- output-path, lable_output_path : 自定义输出
- labels_dic t: 需要扩充图片对应的标签,标签结构为字典
{pic_name:class}, 标签名对应着分类 - threshed : 每个年龄段图片数量小于等于该阈值时,程序会将该年龄段的图片数量扩充到阈值
- max_gen : 如果
ignore参数为True时,则程序会忽略threshed参数,每张图片将会被固定扩充max_gen张 - batch_size : 不作修改
3. 数据处理
这里数据处理使用 \unet文件下的程序进行处理
在一般机器学习或深度学习中数据处理又称数据清洗,主要是对数据进行检查偏差并处理缺失值与噪音。在本次分类处理中,即对数据进行去噪处理。去噪处理可以简单使用低通滤波进行去噪,但更为实际的是提取感兴趣区域:分割。
主要用法见unet分割代码。
4. k-fold划分训练集
k-fold:将数据划分为k份, 每次训练k-1份数据,用训练好的模型对剩下1份数据进行验证,也称交叉验证。在一般使用单个模型训练时可以通过这种方法找到更好地模型及参数。在本次分类中用于对集成学习中基础学习器的训练。
集成学习主要有三种:bagging, boosting, stacking。
- bagging,是使用不同模型对同一训练集进行训练,最后将各个模型预测的结果进行相加求平均。
- boosting, 各个模型之间相互关联如Adaboost, GBDT, XGBDT
- stacking,放一张图片

如图,将划分为5折的数据按1-4组合,共有5总组合方式(有啥疑问的联系我),如图中trainingdata的五列。假设我们有5个不同的神经网络模型,首先用一个神经网络模型如图中的Model1, 对5组数训练数据进行训练,每个组训练数据又分为5份(这是由于每组训练数据是由5折数据组合的),每组数据4分作为训练集,用模型Model1训练4分数据然后对剩下一分进行预测,依次这样经过五次训练后就能得到同一个神经网络模型的5个不同训练结果,并且所有数据都被预测了一次(黄色)。这里的绿色表示对待测试数据集(testdata)进行预测,每一个网络模型的5个不同结果都对同一testdata进行预测,最后加权求平均获得一个新的待预测数据。5个不同的神经网络模型对每一个训练数据都会进行预测,所以每个训练集(trainingdata)可以得到5个不同的预测结果(train_prediction, 每个图片可以得到5个不同的预测分类结果,这里的分类并咩有经过argmax,而是一个一维数组),而待预测的数据也会有5个不同的预测结果(test_prediction)。通过模型融合将训练数据预测结果train_prediction作为新的训练数据,可以训练出新的模型,这样就可以对待预测数据test_prediction进行最终的预测。

原接口 tool/disposal_data.py , 最后生成k-fold个文件,每个文件下又分为train和test,对应上图中的蓝色数据集与黄色数据集。每次训练时对train文件夹的数据进行训练,对test文件下的数据进行预测。对待预测数据(testdata)的预测放到后面。
结果展示:
共分为5组数据

每个组合文件夹分为train和test
train文件夹下内容展示
每个文件夹表示一个年龄分类
5. 数据格式转换
函数参数说明:

- train_data: 上一步划分数据输出路径
- male_tfrecord_output: 数据转换保存路径
输入参数说明:

- male_tfrecord_output: 输出路径
- female_tfrecord_output:输出路径
- train_split_name: 保存训练数据的文件夹名称,用于划分训练集与测试集[不用修改]
- tf_num_shards: 将数据由该值划分进行分块保存[不用修改]
- tf_num_threads: 线程数[不用修改]
- test_split_name: 保存测试数据的文件名[不用修改]
- dataset_name:指定解压数据的函数[不用修改]
- tf_class_label_base: 标签偏移[不用修改]
6.训练模型, 预测剩余fold并保存预测值
训练参数:

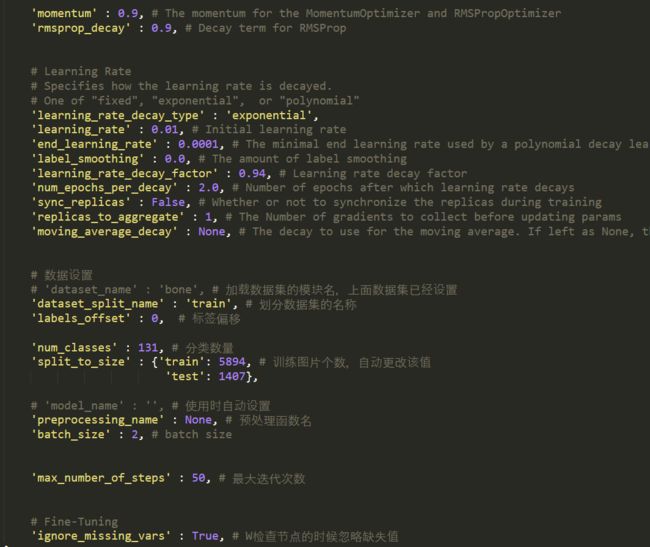
- train_dir: 训练节点存放路径
- clone_on_cpu: False,部署在GPU上;True,部署在CPU上
- num_readers: TF格式数据读取线程数
- num_preprocessing_threads: 训练线程数
- log_every_n_steps: 保存日志步长
- save_summaries_secs: 保存可视化数据参数
- save_interval_secs: 训练结果保存间隔时间
- dataset_split_name:划分TF格式数据的标志,与
train_split_name对应 - num_classes:分类数量
- split_to_size:训练数据与验证数据的数量
- model_name: 自动设置[不用修改]
- preprocessing_name: 图像预处理函数名,不填时为默认[不用修改]
- batch_size: batch size
- max_number_of_steps: 训练的最大迭代数
- ignore_missing_vars: 微调模型忽略缺失值
各个模型的参数
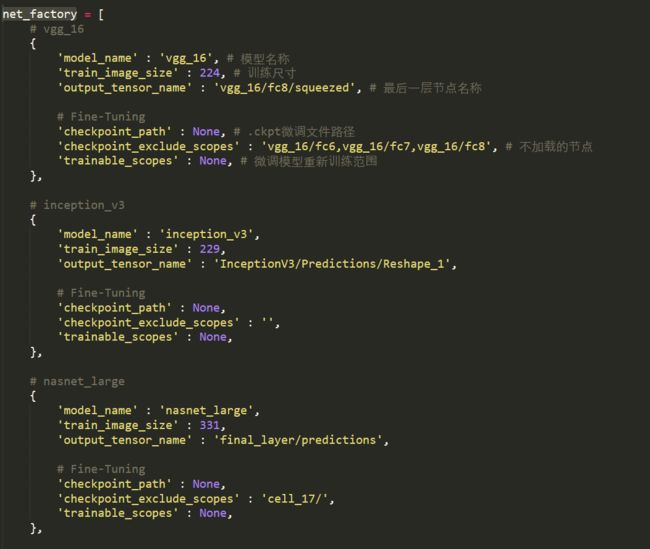
不用修改,若要使用微调则将checkpoint_path参数填为微调模型文件路径
模型转换参数
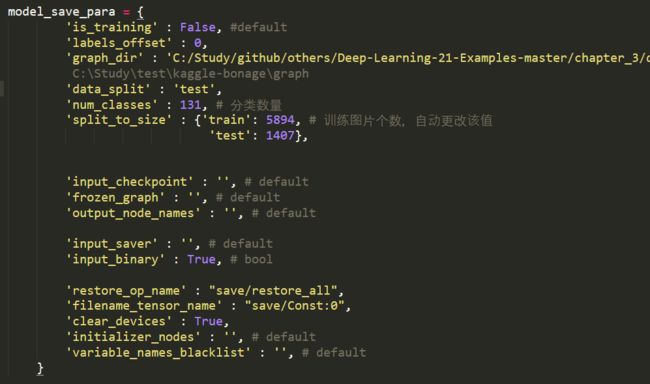
- graph_dir: 训练模型保存路径,每个模型下面对应k_fold数的文件,分别为对各个fold模型训练结果
对剩余fold预测
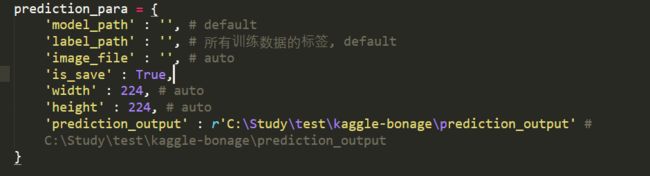
只有输出路径需要设置:
- prediction_output: 预测结果输出路径,每个模型对应一个文件夹,每个文件夹下面对应着k_fold数量文件夹的预测结果
7. 训练融合模型

首先获得各个fold的预测结果,然后使用归回模型进行预测
预测测试集
8,9步合在一起运行,最终获得对测试集的预测结果
注意:
参数选择
模型训练的时候没有进行参数选择,参数选择一般有三种方法:
- 随机选择(经验值)
- 网格:将参数按照一定间隔依次进行训练,选择误差最小的模型所使用的参数
- 贝叶斯网格
几乎所有方法都不能保证达到全局最优,因为深度学习本身就不一定能够达到全局最优
融合模型选择
融合模型选用分类模型,有随机森林,GBDT, XGBDT, ExtraTrees, AdaBoost,BaggingClassifier, LogisticRegression,GaussianNB…