爬虫 - selenium 模块 - 基于浏览器驱动请求数据
目录
一、简单介绍
二、浏览器驱动下载
2-1 有界面浏览器驱动
2-1-1 基于chrome浏览器
2-1-2 基于Firfox浏览器
2-2 无界面浏览器驱动
2-2-1 phantomJS
2-2-2 chromdrive配置无GUI模式
2-3 驱动的基本使用
三、元素查找方法
3-1 find_element_by_
3-2 find_elements_by_
3-3 find_element 和 find_elements
四、Xpath
4-1 Xpath语法
4-1-1 路径表达式
4-1-2 谓语(Predicates)
4-1-3 选取未知节点
4-1-4 选取若干路径
4-2 基于selenium 模块的Xpath匹配
4-2-1 //与/ - 当前节点开始查询、从文档开头开始查询
4-2-2 [] - 获取指定文档指定位置,从1位置开始
4-2-3 按照属性查找 - [] + @ 的综合使用
4-2-4 @ 匹配策略
五、标签属性操作 - webelement
5-1 标签属性操作
5-2 标签方法操作
六、元素加载等待
6-1 隐式等待
6-2 显式等待 - WebDriverWait + ExpectedCondition
七、 网页交互
7-1 实现点击、清空操作 - 基于tag操作
7-2 ActionChains - 动作链,实现持续移动,模拟鼠标拖动
7-2-0 切换焦点
7-2-1 瞬时变化
7-2-2 平滑运动
7-2-3 基于上述测试,部分源码解读
7-3 基于JS代码实现交互 - execute_script('js语法')
7-4 模拟浏览器的前进后退
7-6 选项卡管理
7-7 异常处理
一、简单介绍
官方文档
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
二、浏览器驱动下载
2-1 有界面浏览器驱动
2-1-1 基于chrome浏览器
chromdriver 镜像下载地址
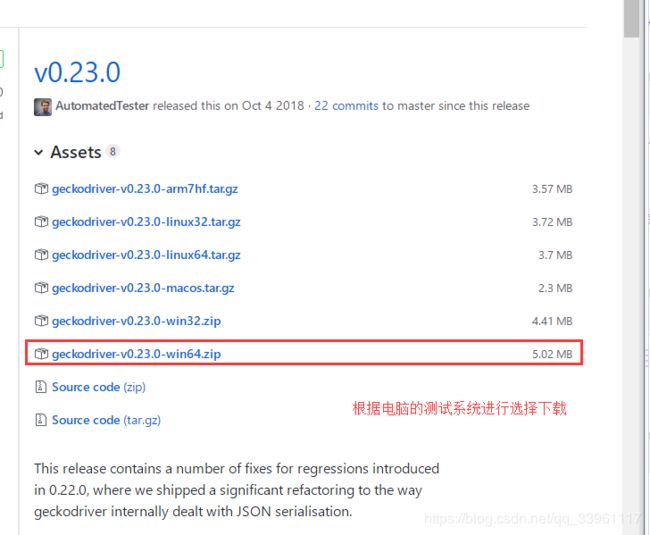
官方最新版下载地址
注意!!:chromdrive版本必须与使用的浏览器版本相匹配。
#### 驱动与浏览器的版本对应关系 ChromeDriver v2.45 (2018-12-10)----------Supports Chrome v70-72 ChromeDriver v2.44 (2018-11-19)----------Supports Chrome v69-71 ChromeDriver v2.43 (2018-10-16)----------Supports Chrome v69-71 ChromeDriver v2.42 (2018-09-13)----------Supports Chrome v68-70 ChromeDriver v2.41 (2018-07-27)----------Supports Chrome v67-69 ChromeDriver v2.40 (2018-06-07)----------Supports Chrome v66-68 ChromeDriver v2.39 (2018-05-30)----------Supports Chrome v66-68 ChromeDriver v2.38 (2018-04-17)----------Supports Chrome v65-67 ChromeDriver v2.37 (2018-03-16)----------Supports Chrome v64-66 ChromeDriver v2.36 (2018-03-02)----------Supports Chrome v63-65 ChromeDriver v2.35 (2018-01-10)----------Supports Chrome v62-64
2-1-2 基于Firfox浏览器
geckodriver 下载地址
2-2 无界面浏览器驱动
如果你的操作系统没有GUI(图形界面),则需要使用无界面的浏览器来搭配selenium使用,有两种方案可选
2-2-1 phantomJS
目前phantomJS已经停止了更新维护,幸好Chrome 出来救场了, 是的selenium再次成为了反爬虫 Team 的噩梦
自Google 发布 chrome 59 / 60 正式版 开始便支持
Headless mode这意味着在无 GUI 环境下, PhantomJS 不再是唯一选择、
#安装:selenium+phantomjs #pip3 install selenium #下载phantomjs,解压后把phantomjs.exe放在项目目录中或是添加到系统环境变量中 #下载链接:http://phantomjs.org/download.html from selenium import webdriver driver=webdriver.PhantomJS() #无界面浏览器 driver.get('https://www.baidu.com') driver.page_source driver.close() #关闭浏览器,回收资源2-2-2 chromdrive配置无GUI模式
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率 chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面 chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 可以提升速度 chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统如果无界面不加这条会启动失败 driver=webdriver.Chrome("驱动绝对路径 如果环境变量中有则可以不写",chrome_options=chrome_options) driver.get('https://www.baidu.com') print('hao123' in driver.page_source) driver.close() #切记关闭浏览器,回收资源 #selenium+谷歌浏览器headless模式注意:firefox配置无GUI模式相同参数
from selenium import webdriver from selenium.webdriver.firefox.options import Options firefox_option = Options() firefox_option.add_argument('window-size=1920x3000') #指定浏览器分辨率 firefox_option.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug firefox_option.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面 firefox_option.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 可以提升速度 firefox_option.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统如果无界面不加这条会启动失败 driver=webdriver.Firefox("驱动绝对路径,同一文件夹下可省略",firefox_options=firefox_option) # driver = webdriver.Firefox(firefox_options=firefox_option) driver.get('https://www.baidu.com') print('hao123' in driver.page_source) driver.close() #切记关闭浏览器,回收资源2-3 驱动的基本使用
初始化驱动对象
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 # browser = webdriver.Firefox() browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') input_tag = browser.find_element_by_id('kw') input_tag.send_keys('柯基') # python2中输入中文错误,字符串前加个u input_tag.send_keys(Keys.ENTER) # 输入回车 wait = WebDriverWait(browser, 10) wait.until(EC.presence_of_element_located((By.ID, 'content_left'))) # 等到id为content_left的元素加载完毕,最多等10秒 print(browser.page_source) print(browser.current_url) print(browser.get_cookies()) finally: pass # browser.close() # 完成上述操作,进行关闭浏览器操作


三、元素查找方法
官方文档查看API
3-1 find_element_by_
Selenium提供了以下方法来定位页面中的元素 - 单个获取
- find_element_by_id - 获取指定id
login_form = driver.find_element_by_id('loginForm')- find_element_by_name - 获取指定name
username = driver.find_element_by_name('username')- find_element_by_xpath - 基于xpath 语法获取符合条件的对象
login_form = driver.find_element_by_xpath("/html/body/form[1]") login_form = driver.find_element_by_xpath("//form[1]") login_form = driver.find_element_by_xpath("//form[@id='loginForm']") Absolute path (would break if the HTML was changed only slightly) First form element in the HTML The form element with attribute named id and the value loginForm- find_element_by_link_text
- 根据链接文本内容,返回标签;如果没有元素具有匹配的链接文本属性,则将引发NoSuchElementException。
- find_element_by_partial_link_text - 根据链接内文本进行模糊查询
Are you sure you want to do this?
Continue Cancel continue_link = driver.find_element_by_link_text('Continue') continue_link = driver.find_element_by_partial_link_text('Conti') #- find_element_by_tag_name - 根据标签名查询对象
Welcome
Site content goes here.
heading1 = driver.find_element_by_tag_name('h1') #- find_element_by_class_name - 根据类名查询对象
Site content goes here.
content = driver.find_element_by_class_name('content')- find_element_by_css_selector - 根据CSS语法选择器进行过滤对象
3-2 find_elements_by_
要查找多个元素(这些方法将返回一个列表) - 查询方法同上
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
3-3 find_element 和 find_elements
除了上面给出的公共方法之外,还有两个私有方法可能对页面对象中的定位器有用。
这是两个私有方法:find_element 和 find_elements。
from selenium.webdriver.common.by import By # 获取单个符合条件的元素 driver.find_element(By.XPATH, '//button[text()="Some text"]') # 获取所有符合条件的元素 driver.find_elements(By.XPATH, '//button') ''' By后可使用的类 ID = "id" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" NAME = "name" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector" '''
四、Xpath
4-1 Xpath语法
W3school 学习链接
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
4-1-1 路径表达式
表达式 描述 nodename 选取此节点的所有子节点。 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性。 在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果 bookstore 选取 bookstore 元素的所有子节点。 /bookstore 选取根元素 bookstore。
注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。 //book 选取所有 book 子元素,而不管它们在文档中的位置。 bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang 选取名为 lang 的所有属性。 4-1-2 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 4-1-3 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述 * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 /bookstore/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。 4-1-4 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 4-2 基于selenium 模块的Xpath匹配
4-2-1 //与/ - 当前节点开始查询、从文档开头开始查询
#//与/ driver.find_element_by_xpath('//body/a') # 开头的//代表从整篇文档中寻找,body之后的/代表body的儿子,这一行找不到就会报错 driver.find_element_by_xpath('//body//a') # 开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙4-2-2 [] - 获取指定文档指定位置,从1位置开始
# 取第n个 res1=driver.find_elements_by_xpath('//body//a[1]') # 取第一个a标签 print(res1[0].text) login_form = driver.find_element_by_xpath("/html/body/form[1]") # 绝对路径(如果HTML仅稍微更改,则会中断) login_form = driver.find_element_by_xpath("//form[1]") # HTML中的第一个表单元素 login_form = driver.find_element_by_xpath("//form[@id='loginForm']") # 表单元素,其属性名为id,值为loginForm4-2-3 按照属性查找 - [] + @ 的综合使用
# 按照属性查找,下述三者查找效果一样 res1=driver.find_element_by_xpath('//a[5]') # 文档第五个a标签对象 res2=driver.find_element_by_xpath('//a[@href="image5.html"]') # a标签内的href为image5.html的对象 res3=driver.find_element_by_xpath('//a[contains(@href,"image5")]') # contains模糊查找 username = driver.find_element_by_xpath("//form[input/@name='username']") # 第一个表单元素,带有一个输入子元素,其属性名为name,值为username username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]") # 表单元素的第一个输入子元素,其属性名为id,值为loginForm username = driver.find_element_by_xpath("//input[@name='username']") # 第一个输入元素,其属性名为“name”,值为username4-2-4 @ 匹配策略
res2=driver.find_element_by_xpath('//a[img/@src="image3_thumb.jpg"]') # 找到子标签img的src属性为image3_thumb.jpg的a标签 res3 = driver.find_element_by_xpath("//input[@name='continue'][@type='button']") # 查看属性name为continue且属性type为button的input标签 res4 = driver.find_element_by_xpath("//*[@name='continue'][@type='button']") # 查看属性name为continue且属性type为button的所有标签 clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]") # 表单元素的第四个输入子元素,其属性名为id,值为loginForm
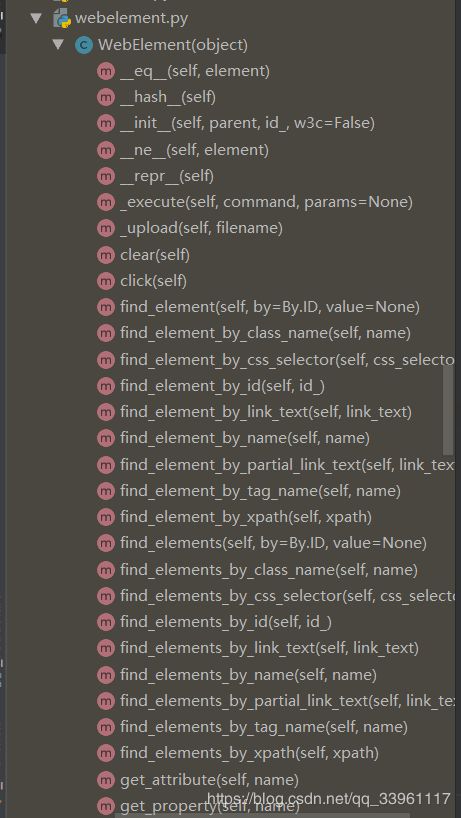
五、标签属性操作 - webelement
5-1 标签属性操作
- tag.id - 获取标签ID
- tag.location - 获取标签位置
- tag.tag_name - 获取标签名称
- tag.size - 获取标签大小
- tag.text - 获取对象的文本内容
- tag.location_once_scrolled_into_view
- 对象属性可能毫无预兆地发生变化。用它来发现一个元素在屏幕上的位置,这样我们就可以点击它。此方法应使元素滚动到视图中。返回屏幕左上角的位置,如果元素不可见,则返回“None”。
- tag.location - 可渲染画布中元素的位置。
- tag.rect - 具有元素的大小和位置的字典。
- tag.screenshot_as_base64 - 获取以base64编码的字符串形式显示的当前元素的屏幕快照。
img_b64 = element.screenshot_as_base64- tag.screenshot_as_png - 以二进制数据的形式获取当前元素的屏幕快照。
element_png = element.screenshot_as_png- tag.parent - 从WebDriver实例的内部引用中找到此元素。
5-2 标签方法操作
- tag.click() - 点击对象元素
- tag.submit() - 提交一个表单
- tag.clear() - 如果是文本输入元素,否则清除文本。 - Element must be user-editable in order to clear it.例如输入框
- tag.get_property(name) - Gets the given property of the element.获取元素的给定属性。name - Name of the property to retrieve.要检索的属性的名称。
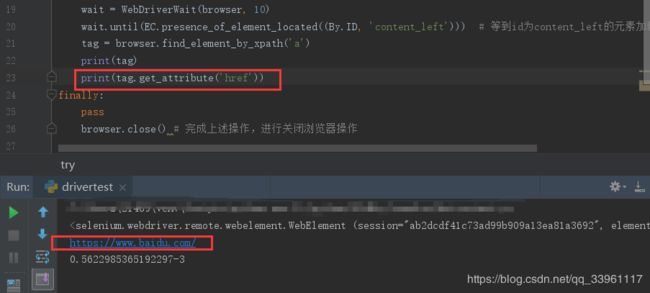
text_length = target_element.get_property("text_length")- tag.get_attribute(name) - Gets the given attribute or property of the element.获取元素的给定属性。name - Name of the attribute/property to retrieve.
# Check if the "active" CSS class is applied to an element. is_active = "active" in target_element.get_attribute("class") # 返回布尔类型 tag.get_attribute('src') # 获取标签属性,必须指定属性。如a标签对象的href属性- !注意!
- property 是DOM中的属性,是JavaScript里的对象;
- attribute 是HTML标签上的特性,它的值只能够是字符串;
- tag.is_selected() - 返回是否选择元素。可用于检查是否选中复选框或单选按钮。
- tag.is_enabled() - 返回是否启用该元素。
- tag.send_key(*value) - value-用于输入或设置表单字段的字符串。对于设置文件输入,这可以是一个本地文件路径。
form_textfield = driver.find_element_by_name('username') form_textfield.send_keys("admin") file_input = driver.find_element_by_name('profilePic') file_input.send_keys("path/to/profilepic.gif") # Generally it's better to wrap the file path in one of the methods # in os.path to return the actual path to support cross OS testing. # file_input.send_keys(os.path.abspath("path/to/profilepic.gif"))- tag.is_displayed() -元素对用户是否可见。
- tag.value_of_css_property(property_name) - 获取CSS属性的值。
- tag.screenshot(filename) - 将当前元素的屏幕快照保存到PNG图像文件中。如果有IOError,则返回False,否则返回True。在文件名中使用完整路径。filename - 保存截图的完整路径。这应该以 ‘.png’结尾的扩展。
element.screenshot('/Screenshots/foo.png')
六、元素加载等待
elenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待
- 两种等待方式
- 隐式等待:在browser.get('xxx')前就设置,针对所有元素有效
- 显式等待:在browser.get('xxx')之后设置,只针对某个元素有效
6-1 隐式等待
隐式等待告诉WebDriver在尝试查找不能立即可用的任何元素(或元素)时轮询DOM一段时间。
默认设置为0.设置后,将为WebDriver对象的生命周期设置隐式等待。
!!注意!!!:隐式等待对于局部ajax操作刷新的数据无效,只能对于全页刷新的数据才有等待效果
from selenium import webdriver from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser=webdriver.Chrome() '''隐式等待:在查找所有元素时,如果尚未被加载,则等10秒''' browser.implicitly_wait(10) # wait=WebDriverWait(browser,10) browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw') input_tag.send_keys('柯基') input_tag.send_keys(Keys.ENTER) contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错 print(contents) browser.close()
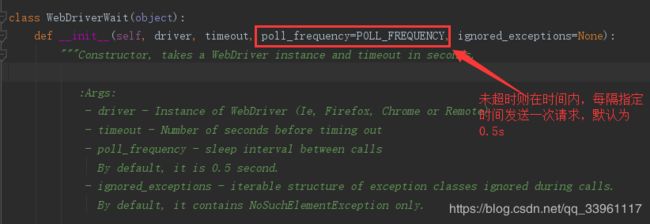
6-2 显式等待 - WebDriverWait + ExpectedCondition
显式等待是您定义的代码,用于在进一步执行代码之前等待某个条件发生。
这种情况的极端情况是time.sleep(),它将条件设置为等待的确切时间段。
提供了一些便捷方法,可帮助您编写仅在需要时等待的代码。
WebDriverWait与ExpectedCondition相结合是一种可以实现的方法。
from selenium import webdriver from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw') input_tag.send_keys('柯基') input_tag.send_keys(Keys.ENTER) '''显式等待:显式地等待某个元素被加载''' wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) ''' element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) 这会在抛出TimeoutException之前等待最多10秒,除非它发现元素在10秒内返回。 WebDriverWait默认情况下每500毫秒调用一次ExpectedCondition,直到它成功返回。 对于所有其他ExpectedCondition类型,ExpectedCondition类型的布尔返回true或非null返回值成功返回。 ''' contents=browser.find_element(By.CSS_SELECTOR,'#content_left') print(contents) browser.close()

七、 网页交互
7-1 实现点击、清空操作 - 基于tag操作
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser = webdriver.Chrome() browser.get('https://www.amazon.cn/') # 隐式等待5秒 wait = WebDriverWait(browser, 5) input_tag = wait.until(EC.presence_of_element_located((By.ID, 'twotabsearchtextbox'))) input_tag.send_keys('iphone') button = browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input') button.click() # import time # time.sleep(3) # 等待模拟浏览 wait = WebDriverWait(browser, 5) input_tag = browser.find_element_by_id('twotabsearchtextbox') input_tag.clear() # 清空输入框 input_tag.send_keys('iphone8') button = browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input') button.click() # browser.close()7-2 ActionChains - 动作链,实现持续移动,模拟鼠标拖动
官方文档API查询
ActionChains是一种自动执行低级别交互的方法,例如鼠标移动,鼠标按钮操作,按键和上下文菜单交互。这对于执行更复杂的操作非常有用,例如悬停和拖放。
7-2-0 切换焦点
由于目标id非页面唯一,所以先切换焦点到祖辈节点下,在基于祖辈节点查询唯一ID
7-2-1 瞬时变化
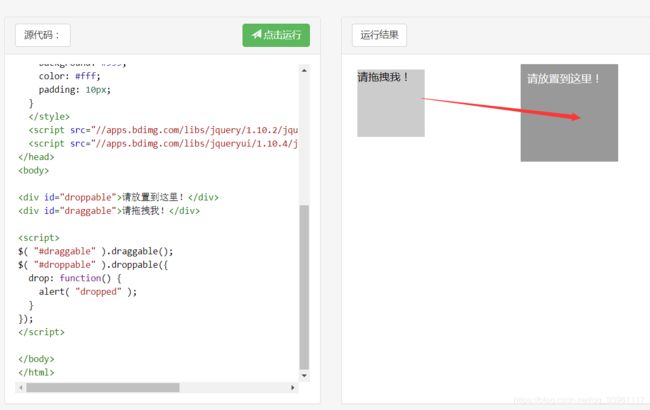
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 import time driver = webdriver.Chrome() driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') # 使用隐式等待 wait = WebDriverWait(driver, 3) # driver.implicitly_wait(3) try: driver.switch_to.frame('iframeResult') # 切换焦点到iframeResult sourse = driver.find_element_by_id('draggable') # 在iframeResult下去查询id target = driver.find_element_by_id('droppable') # 基于同一个动作链串行执行 actions = ActionChains(driver) # 拿到动作链对象 actions.drag_and_drop(sourse, target) # 把动作放到动作链中,准备串行执行 actions.perform() # 执行所有存储的操作 finally: pass # driver.close()
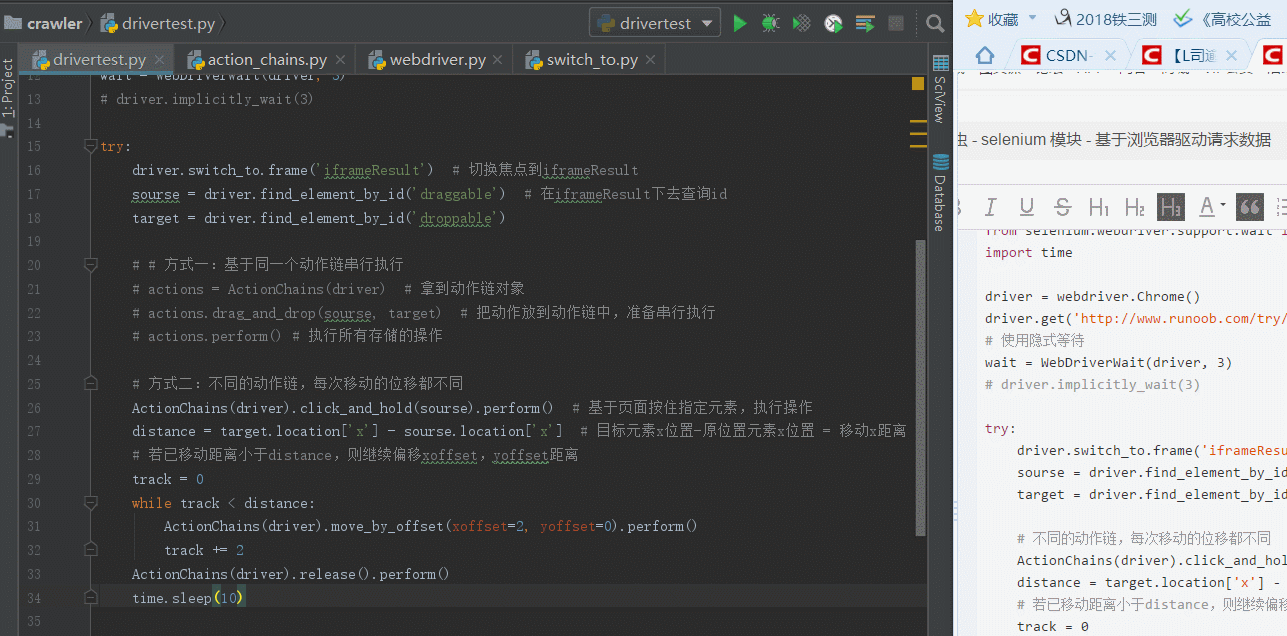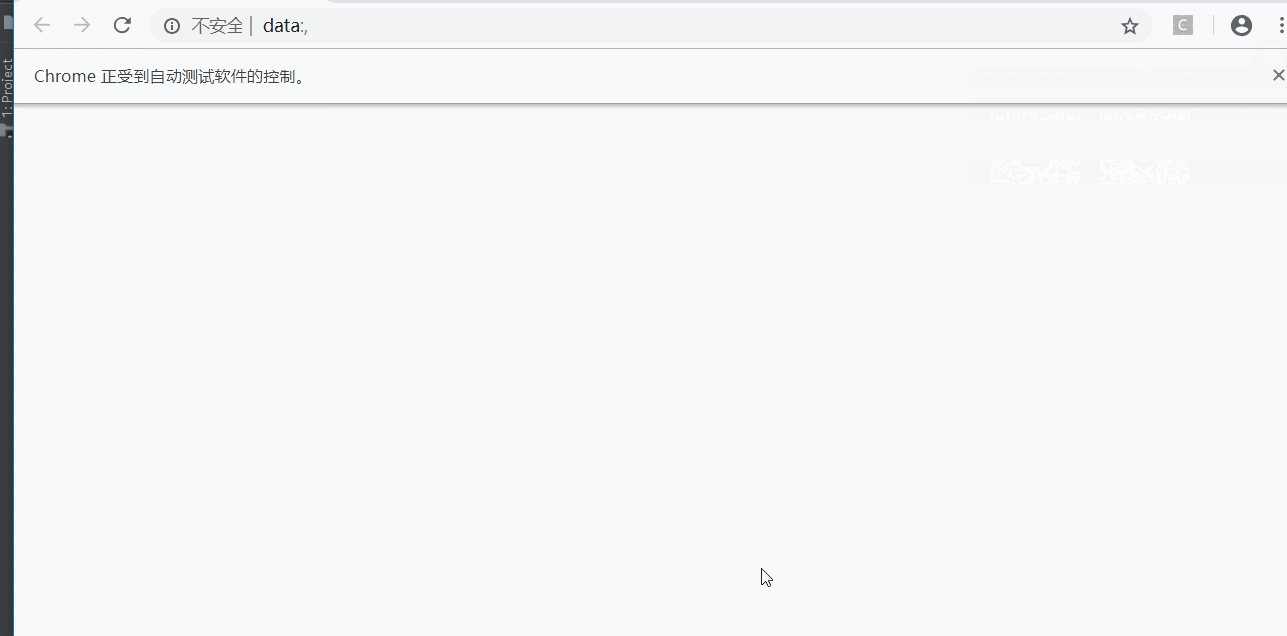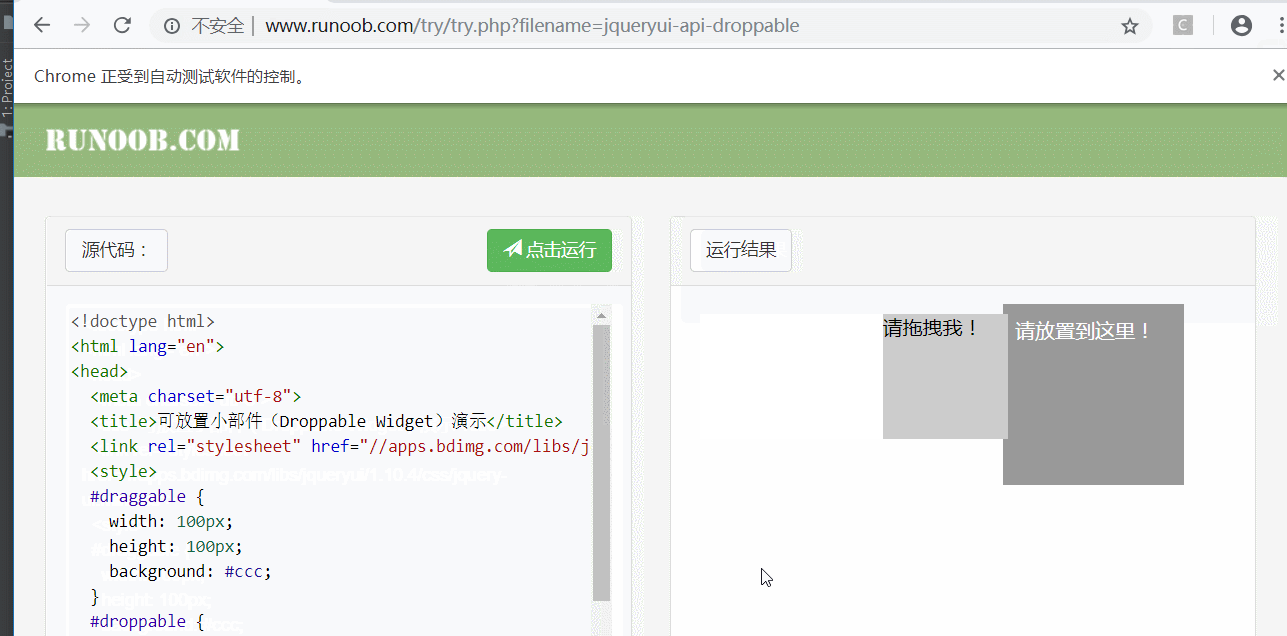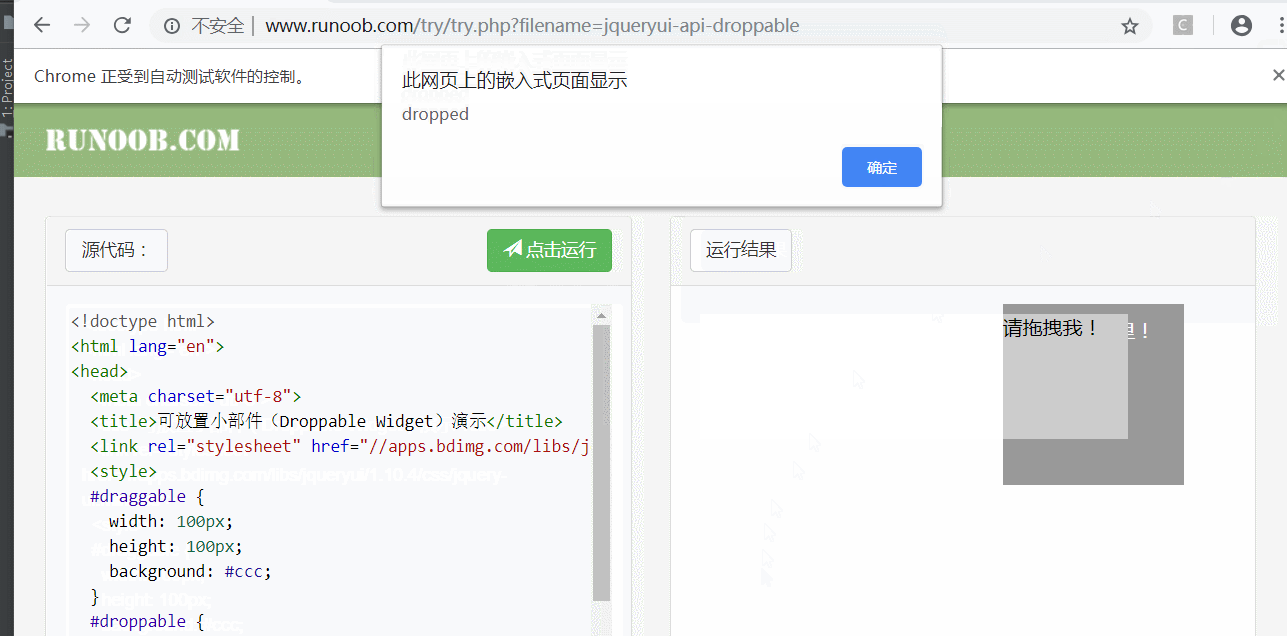
7-2-2 平滑运动
from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 import time driver = webdriver.Chrome() driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') # 使用隐式等待 wait = WebDriverWait(driver, 3) # driver.implicitly_wait(3) try: driver.switch_to.frame('iframeResult') # 切换焦点到iframeResult sourse = driver.find_element_by_id('draggable') # 在iframeResult下去查询id target = driver.find_element_by_id('droppable') # 不同的动作链,每次移动的位移都不同 ActionChains(driver).click_and_hold(sourse).perform() # 基于页面按住指定元素,执行操作 distance = target.location['x'] - sourse.location['x'] # 目标元素x位置-原位置元素x位置 = 移动x距离 # 若已移动距离小于distance,则继续偏移xoffset,yoffset距离 track = 0 while track < distance: ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() track += 2 ActionChains(driver).release().perform() time.sleep(10) finally: pass # driver.close()
7-2-3 基于上述测试,部分源码解读
@property def switch_to(self): """ :Returns: - SwitchTo: an object containing all options to switch focus into class SwitchTo 对象,该对象包含要切换焦点的所有选项 :Usage: element = driver.switch_to.active_element alert = driver.switch_to.alert driver.switch_to.default_content() driver.switch_to.frame('frame_name') driver.switch_to.frame(1) driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0]) driver.switch_to.parent_frame() driver.switch_to.window('main') """ return self._switch_to ------------------------------------------------------------------------------- class SwitchTo: def frame(self, frame_reference): """ Switches focus to the specified frame, by index, name, or webelement. 通过索引、名称或webelement将焦点切换到指定的帧。 :Args: - frame_reference: The name of the window to switch to, an integer representing the index, or a webelement that is an (i)frame to switch to. :Usage: driver.switch_to.frame('frame_name') driver.switch_to.frame(1) driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0]) """ if isinstance(frame_reference, basestring) and self._driver.w3c: try: frame_reference = self._driver.find_element(By.ID, frame_reference) except NoSuchElementException: try: frame_reference = self._driver.find_element(By.NAME, frame_reference) except NoSuchElementException: raise NoSuchFrameException(frame_reference) self._driver.execute(Command.SWITCH_TO_FRAME, {'id': frame_reference})7-3 基于JS代码实现交互 - execute_script('js语法')
from selenium import webdriver browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') browser.execute_script('alert("hello world")') # 打印警告 finally: pass # browser.close()7-4 模拟浏览器的前进后退
import time from selenium import webdriver browser=webdriver.Chrome() browser.get('https://www.baidu.com') browser.get('https://www.taobao.com') browser.get('http://www.sina.com.cn/') # 回退 browser.back() time.sleep(10) # 前进 browser.forward() browser.close()7-5 cookies操作
from selenium import webdriver browser=webdriver.Chrome() browser.get('https://www.zhihu.com/explore') # 获取cookies print(browser.get_cookies()) # 添加cookies browser.add_cookie({'k1':'xxx','k2':'yyy'}) print(browser.get_cookies()) # browser.delete_all_cookies()7-6 选项卡管理
# 选项卡管理:切换选项卡,有js的方式windows.open,有windows快捷键:ctrl+t等,最通用的就是js的方式 import time from selenium import webdriver browser=webdriver.Chrome() browser.get('https://www.baidu.com') browser.execute_script('window.open()') print(browser.window_handles) # 获取所有的选项卡 browser.switch_to_window(browser.window_handles[1]) browser.get('https://www.taobao.com') time.sleep(10) browser.switch_to_window(browser.window_handles[0]) browser.get('https://www.sina.com.cn') browser.close()7-7 异常处理
from selenium import webdriver from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException try: browser=webdriver.Chrome() browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') browser.switch_to.frame('iframssseResult') except TimeoutException as e: print(e) except NoSuchFrameException as e: print(e) finally: browser.close()