int8量化学习
int8、float32

量化原理介绍:
https://zhuanlan.zhihu.com/p/58182172
https://zhuanlan.zhihu.com/p/58208691
量化小实验:
https://github.com/Ewenwan/MVision/tree/master/CNN/Deep_Compression/quantization
tensorRT量化
1.无需retain,retrain的要求就是,你的权值、激活值(实测对最终精度的影响不是很大)都必须是分布比较均匀的,也就是方差不要太大。
2.量化原理


FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t) + FP32_bias (b):T=sf*t
论文首先提出了一个对称量化和非对称量化的概念,即在公式中的bias,在nvidia的文章中,bias=0(在他的文章中提到并不需要偏置)就是对称量化的概念,0量化后还是0; bias不等于0的情况就是非对称量化,但是这其中需要注意的是bias的需要是整型,因为在深度学习的模型中,有太多的0-padding存在了,若是bias非整型,那么在量化过程中会有大量的数值0的精度收到损失。
第二个提出了逐层量化和逐通道量化的概念,从字面非常容易理解两个量化的区别,我们也看到在nvidia的方法中使用了逐层量化的方法,每一层采用同一个阈值来进行量化。逐通道量化就是对每一层每个通道都有各自的阈值,对精度有一个很好的提升。
3.KL散度:相对熵,因为相对熵表述的就是两个分布的差异程度,放到我们的情境里面来就是量化前后两个分布的差异程度,差异最小就是最好的了~因此问题转换为求相对熵的最小值!
信息熵:
![]()
交叉熵:
![]()
相对熵=交叉熵-信息熵:
![]()
4.校准算法:
首先准备一个校准数据集,然后对每一层:
收集激活值的直方图;
基于不同的阈值产生不同的量化分布;
然后计算每个分布与原分布的相对熵,然后选择熵最少的一个,也就是跟原分布最像的一个。
此时阀值就选出来啦,对应的scale值也就出来了。

输入为[0, 2048] bins,然后想办法把这么大的分布给找到一个合理的阀值T然后把阀值内的bins映射到int8的128个bins里面来,最终而且信息熵损失是最少的。
具体流程:
首先不断地截断参考样本P,长度从128开始到2048,为什么从128开始呢?因为截断的长度为128的话,那么我们直接一一对应就好了,完全不用衰减因子了;
将截断区外的值全部求和;
截断区外的值加到截断样本P的最后一个值之上;(截断区之外的值为什么要加到截断区内最后一个值呢?我个人理解就是有两个原因,其一是求P的概率分布时,需要总的P总值,其二将截断区之外的加到截断P的最后,这样是尽可能地将截断后的信息给加进来。)
求得样本P的概率分布;
创建样本Q,其元素的值为截断样本P的int8量化值;
将Q样本长度拓展到 i ,使得和原样本P具有相同长度;
求得Q的概率分布;
然后就求P、Q的KL散度值就好啦~
上面就是一个循环,不断地构造P和Q,并计算相对熵,然后找到最小(截断长度为m)的相对熵,此时表示Q能极好地拟合P分布了。
tensorflow-lite量化

1.权重量化
2.权重+激活量化
3.量化训练


NCNN量化
quantize,dequantize
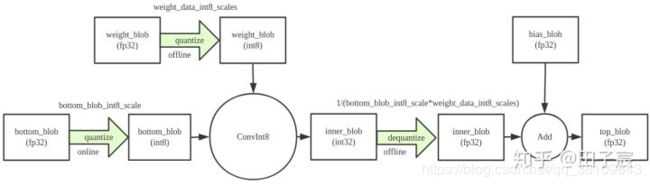
requantize,中间不会输出fp32的blob,节省一次内存读写

使用情况:
(1) Conv1 -> ReLU -> Conv2,且Conv1和Conv2都用int8
(2) Conv1 -> ReLU -> Split -> Conv2_1
-> Conv2_2
…
-> Conv2_x,且这些Conv都用int8
MNN量化
1.离线量化
2.训练量化Quantization-aware Training(QAT)


对于权值和特征的fake-quant基本都和上图一致,不一样的是对于特征由于其范围是随输入动态变化的,而最终int8模型中必须固定一个对于输入特征的scale值,所以,我们对每一此前向计算出来的scale进行了累积更新,例如使用滑动平均,或者直接取每一次的最大值。对于权值的scale,则没有进行平均,因为每一次更新之后的权值都是学习之后的较好的结果,没有状态保留。
此外,对于特征和权值,均提供了分通道(PerChannel)或者不分通道(PerTensor)的scale统计方法,可根据效果选择使用。
3.特征量化方法:
“KL”: 使用KL散度进行特征量化系数的校正,一般需要100 ~ 1000张图片(若发现精度损失严重,可以适当增减样本数量,特别是检测/对齐等回归任务模型,样本建议适当减少)
“ADMM”: 使用ADMM(Alternating Direction Method of Multipliers)方法进行特征量化系数的校正,一般需要一个batch的数据
4.权重量化方法:
“MAX_ABS”: 使用权值的绝对值的最大值进行对称量化
“ADMM”: 使用ADMM方法进行权值量化
关于量化方法的数学解释:
https://zhuanlan.zhihu.com/p/81243626?from_voters_page=true
MNN量化源码解析:https://zhuanlan.zhihu.com/p/153562409?from_voters_page=true
格灵深瞳EasyQuant:
https://zhuanlan.zhihu.com/p/151383244
https://github.com/deepglint/EasyQuant.