北大pkuseg分词 和 jieba 分词对比测试,结果出乎意料...


本文授权转载自Python编程与实战
禁止二次转载
大家好,我是老表
阅读文本大概需要 7 分钟
上篇文章说了jieba分词入门使用指南,大家都说北大有个分词很厉害,于是,有了这篇文章分享,用完北大分词,嗯,还是jieba香。
有做过搜索的朋友知道,分词的好坏直接影响我们最终的搜索结果。
在分词的领域,英文分词要简单很多,因为英文语句中都是通过一个个空格来划分的,而我们的中文博大精深,同样的词在不同的语境中所代表的含义千差万别,有时候必须联系上下文才能知道它准确的表达意思,因此中文分词一直是分词领域的一大挑战。
之前介绍过一款北大新开源的分词器,根据作者的测试结果,这是一个准确率和速度都超过 jieba 等其他分词的分词器。
所以我就想来做个简单的测试!于是我想用《三国演义》来做一个测试,提取其中著名人名出现的频率。
首先搜索下三国中的人物名单,

得到人名之后,做成一个人名的列表,之前设置成一个以人物名为键,值为 0 的字典。我只取了曹魏和蜀汉的部分人名,代码如下:
wei = ["许褚","荀攸","贾诩","郭嘉","程昱","戏志","刘晔","蒋济","陈群","华歆","钟繇","满宠","董昭","王朗","崔琰","邓艾","杜畿","田畴","王修","杨修","辛毗",
"杨阜",
"田豫","王粲","蒯越","张继","于禁","枣祗","曹操","孟德","任峻","陈矫","郗虑","桓玠","丁仪","丁廙","司马朗","韩暨","韦康","邴原","赵俨","娄圭","贾逵",
"陈琳",
"司马懿","张辽","徐晃","夏侯惇","夏侯渊","庞德","张郃","李典","乐进","典韦","曹洪","曹仁","曹彰"]
wei_dict = dict.fromkeys(wei, 0)
shu_dict = dict.fromkeys(shu, 0)
接着去网上下载一部三国的电子书,并读取返回
def read_txt():
with open("三国.txt", encoding="utf-8") as f:
content = f.read()
return content
pkuseg 测试结果
pkuseg 的用法很简单,首先实例化 pkuseg 的对象,获取人物名称数量的思路是这样的:循环我们分词后的列表,如果检测到有人物名称字典中的人物名,就将该数据加 1,代码如下:
def extract_pkuseg(content):
start = time.time()
seg = pkuseg.pkuseg()
text = seg.cut(content)
for name in text:
if name in wei:
wei_dict[name] = wei_dict.get(name) + 1
elif name in shu:
shu_dict[name] = shu_dict.get(name) + 1
print(f"pkuseg 用时:{time.time() - start}")
print(f"pkuseg 读取人名总数:{sum(wei_dict.values()) + sum(shu_dict.values())}")
执行结果如下:
 pkuseg 测试结果
pkuseg 测试结果
jieba 测试结果
代码基本差不多,只是分词器的用法有些不同。
def extract_jieba(content):
start = time.time()
seg_list = jieba.cut(content)
for name in seg_list:
if name in wei:
wei_dict[name] = wei_dict.get(name) + 1
elif name in shu:
shu_dict[name] = shu_dict.get(name) + 1
print(f"jieba 用时:{time.time() - start}")
print(f"jieba 读取人名总数:{sum(wei_dict.values()) + sum(shu_dict.values())}")
执行结果如下:
 jieba 测试结果
jieba 测试结果
emmm 测试结果好像好像有点出乎意料,说好的 pkuseg 准确率更高呢???

pkuseg 用时将近 jieba 的三倍,而且提取效果也没有 jieba 分词好!于是我就去逼乎搜了一下 pkuseg ,结果是这样的….

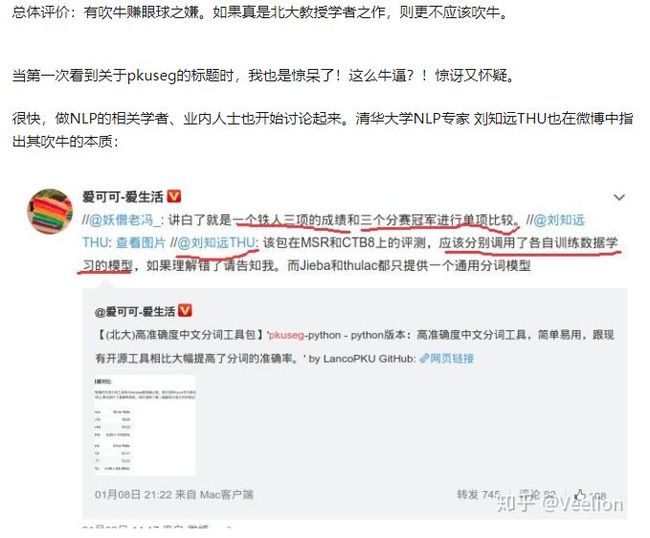
总体而言 pkuseg 吹的有点过了,并没有作者说的那么神奇,有点博眼球的成分,也许它更是一款更注重细分领域的分词器!
大家好,我是老表
觉得本文不错的话,转发、留言、点赞,是对我最大的支持。
留言赠书
《Python网络爬虫开发》
从入门到精通
(1)没有高深的理论,每一章都是以实例为主,读者参考源码,修改实例,就能得到自己想要的结果。目的是让读者看得懂、学得会、做得出。
(2)实训与问答,10多章章节实训与问答,目的是让读者看完之后,能做到举一反三,学以致用。
(3)内容系统,实战性强。本书从零开始讲解,然后逐步深入相关爬虫技能,从而达到从入门到精通的学习效果。
(4)配套资源丰富。案例源码,Python 常见面试题精选(50 道),“微信高手技巧随身查”“QQ 高手技巧随身查”“手机办公 10 招就够”3 本电子书,“5 分钟学会番茄工作法”视频教程““10 招精通超级时间整理术”视频教程。

每日留言
说说你读完本文感受?
或者一句激励自己的话?
(字数不少于15字)
怎么加入刻意学习队伍
点我,看文末彩蛋
留言有啥福利
点我就知道了
想进学习交流群
加微信:jjxksa888
备注:简说Python
2小时快速掌握Python基础知识要点。
完整Python基础知识要点
Python小知识 | 这些技能你不会?(一)
Python小知识 | 这些技能你不会?(二)
Python小知识 | 这些技能你不会?(三)
Python小知识 | 这些技能你不会?(四)
近期推荐阅读:
【1】整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
【2】【终篇】Pandas中文官方文档:基础用法6(含1-5)
觉得不错就点一下“在看”吧
