Android基于Jsoup的网络爬虫
一、浅谈网络爬虫
随着网络的迅速发展,互联网成为大量信息的载体,如何有效的利用这些信息成为巨大的挑战。区别于搜索引擎,定向抓取相关网页资源的网络爬虫应用而生,可以根据既定的抓取目标有效的选择网络上需要的网页资源和信息。如用户想获得知乎豆瓣等网站上的主要数据进行分析,如用户想获得某个论坛贴吧内的所有图片等,把这项工作交给网络爬虫,可以大大提高人们的效率。
二、Jsoup简介
Jsoup是一个 Java 的开源HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常方便的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup主要有以下功能:
- 从一个字符串、文件或者一个 URL 中解析HTML
- 提供一系列方法对HTML进行数据抽取
- 对HTML元素、属性、文本进行操作
- 消除不受信任的HTML (来防止XSS攻击)
简言之,安卓跟web爬虫基本上没什么区别,都是通过请求获得响应。Android返回的是json格式的字符串,web返回的是页面,通过Jsoup我们可以方便的对网页的数据进行操作。
三、Jsoup的配置
首先在Jsoup官网 https://jsoup.org/download 下载对应的jar包
并将下载的jar包导入项目的依赖库中
implementation ‘org.jsoup:jsoup:1.12.1’
然后在gradle中添加以下依赖
compile 'org.jsoup:jsoup:1.12.1'
由于jsoup需要获取网络数据,所以需要添加网络权限
四、Jsoup的使用
1.从一个字符串、文件或者一个 URL 中解析HTML
String html = "First parse "
+ "Parsed HTML into a doc.
";
Document doc = Jsoup.parse(html);
当对象是URL时,使用 Jsoup.connect(String url)方法:
Document doc = Jsoup.connect("http://example.com/").get();
String title = doc.title();
当URL请求为post方式而不是get方式时
Document doc = Jsoup.connect("http://example.com")
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.post();
2.提供一系列方法对HTML进行数据抽取
Jsoup将HTML解析成Document后,可以使用一系列DOM方法:
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
Elements这个对象提供了一系列类似于DOM的方法来查找元素,抽取并处理其中的数据。具体如下:
查找元素
getElementById(String id)
getElementsByTag(String tag)
getElementsByClass(String className)
getElementsByAttribute(String key) (and related methods)
Element siblings: siblingElements(), firstElementSibling(), lastElementSibling(); nextElementSibling(), previousElementSibling()
Graph: parent(), children(), child(int index)
操作HTML和文本
append(String html), prepend(String html)
appendText(String text), prependText(String text)
appendElement(String tagName), prependElement(String tagName)
html(String value)
3.对HTML元素、属性、文本进行操作
在你解析一个Document之后可能想修改其中的某些属性值,然后再保存到磁盘或都输出到前台页面。
可以利用Jsoup进行如下操作:
Element div = doc.select("div").first(); //
div.html("lorem ipsum
"); // lorem ipsum
div.prepend("First
");//在div前添加html内容
div.append("Last
");//在div之后添加html内容
// 添完后的结果: First
lorem ipsum
Last
Element span = doc.select("span").first(); // One
span.wrap("One
这是对一个HTML中内容元素的设置
关于Jsoup的更多使用细节可以参考中文文档:https://www.open-open.com/jsoup/
五、爬取数据的思路
1.根据想要获取的资源,利用浏览器自带的审查元素功能(F12)获得想要的资源
以知乎为例如下可见网页的各个元素的名称:
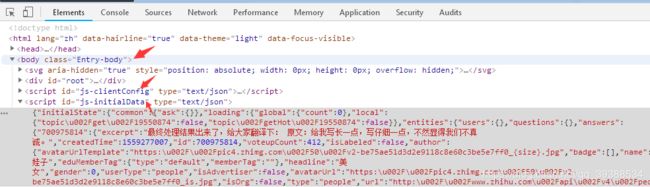
2.利用Jsoup进行解析:
这里主要的分析网站是https://www.zhihu.com/topic/19550874/hot
因为Android的网络操作需要在不能在主线程运行,可以使用Thread+Handler或者AsyncTask获取数据并在主界面刷新UI。
其次是数据的展示,将数据放在listView中即可,如果要加入下拉刷新或者上滑加载则需要额外的工作。
以下是关键代码:
/private class SearchTask extends AsyncTask
{
Context context;
Map.Entry topicURL;
public SearchTask(Context context,Map.Entry topicURL)
{
this.context = context;
this.topicURL = topicURL;
}
@Override
protected Boolean doInBackground(Void... voids)
{
Connection conn= Jsoup.connect("https://www.zhihu.com/topic/" + topicURL.getValue()+ "/hot");
Document doc;
try
{
doc = conn.get();
Elements answerList = doc.select("div[class=ContentItem AnswerItem]");
for (Element element : answerList)
{
Map map = new HashMap<>();
//作者 标题
JsonParser parser = new JsonParser();
JsonObject data = parser.parse(element.attr("data-zop")).getAsJsonObject();
String authorName = data.get("authorName").getAsString();
String title = data.get("title").getAsString();
map.put("title", title);
//简略内容
Elements spanContent = element.select("span[class=RichText CopyrightRichText-richText]");
String minContent = spanContent.text();
map.put("content", authorName+":"+minContent);
//赞数
Elements likeCountButton = element.select("button[class=Button VoteButton VoteButton--up]");
String likeCount = likeCountButton.text();
map.put("likeCount", likeCount+"点赞");
//回答URL
String url = element.getElementsByAttributeValue("itemprop", "url").get(2).attr("content");
map.put("url", url);
map.put("topic",topicURL.getKey());
answersList.add(map);
}
} catch (IOException e)
{
e.printStackTrace();
}
return true;
}
@Override
protected void onPostExecute(final Boolean success) {
if (success) {
listView_answer.onLoadComplete();
adapter.notifyDataSetChanged();
if(getUserVisibleHint())
Toast.makeText(getActivity(), "加载完成", Toast.LENGTH_SHORT).show();
} else {
if(getUserVisibleHint())
Toast.makeText(getActivity(),"连接服务器出错",Toast.LENGTH_SHORT).show();
}
mAuthTask = null;
}
@Override
protected void onCancelled() {
mAuthTask = null;
}
}
private void setListView(View rootView)
{
listView_answer = (LoadMoreListView) rootView.findViewById(R.id.listView_answer);
listView_answer.setLoadMoreListen(this);
swip = (SwipeRefreshLayout) rootView.findViewById(R.id.swip_index);
swip.setOnRefreshListener(this);
swip.setColorSchemeResources(android.R.color.holo_blue_light, android.R.color.holo_red_light, android.R.color.holo_orange_light,
android.R.color.holo_green_light);
adapter = new SimpleAdapter(getContext(),answersList,R.layout.answer_layout,
new String[]{"title","content","likeCount","topic"},
new int[]{R.id.textView_title,R.id.textView_content,R.id.textView_likeCount,R.id.textView_topic});
listView_answer.setOnItemClickListener(new AdapterView.OnItemClickListener()
{
@Override
public void onItemClick(AdapterView adapterView, View view, int i, long l)
{
Intent intent = new Intent();
intent.setAction(Intent.ACTION_VIEW);
Uri content_url = Uri.parse(answersList.get(i).get("url").toString());
intent.setData(content_url);
startActivity(intent);
}
});
listView_answer.setAdapter(adapter);
}
参考地址:https://blog.csdn.net/chinastraw/article/details/79397892
至此,一个简单的Android网络爬虫就已经实现(layout文件省略)
作者:毛忠钦
原文地址:https://blog.csdn.net/qq_39388534/article/details/90721821