爬虫常用模块:requests ,cookie处理,xlwt(写入excel), lxml
1. requests
import requests
url = 'http://www.baidu.com'
response =requests.get(url)
print(response) # 请求成功
print(response.text) # 返回网页的文本内容
print(response.reason) # reason 原因 对请求状态的解释
print(response.links) # link 跳转的地址
print(response.history) # 请求历史
print(response.apparent_encoding # 获取网页的编码
response.encoding = response.apparent_encoding) # 设置响应的编码格式为网页的编码格式
print(response.content) # 获取网页内容(bytes 二进制 形式的)
print(response.cookies) # 获取网页cookies
# 2.0 ip代理
from urllib.request import urlopen, Request, build_opener, ProxyHandler
import random
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
# 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0'
]
headers ={
'User-Agent': 'random.choice(user_agent_list)'
}
ip_list = [
'124.193.85.88:8080',
'122.114.31.177:808',
'111.155.124.84:8123',
'111.155.116.207:8123',
'122.72.18.34:80',
'61.135.217.7:80',
'111.155.116.234:8123'
]
proxies = {
'http': random.choice(ip_list)
}
requsest = Request('http:www.baidu.com', headers=headers)
proxy_handler = ProxyHandler(proxies)
opener = build_opener(proxy_handler)
response = opener.open(requsest)
print(response.read().decode())2. cookie 的处理
简介:由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容
所需的模块:
from http.cookiejar import CookieJar,LWPCookieJar
from urllib.request import urlopen, HTTPCookieProcessor, build_opener, Request
from urllib.parse import urlencode
import ssl(1)获取cookie
# 生成一个管理cookie的对象
cookie_obj = CookieJar()
# 创建一个支持cookie 对象,对象属于 HTTPCookieProcessor
cookie_handler = HTTPCookieProcessor(cookie_obj) #quote(url, safe=string.printable)
# build_opener()的内部实现就是urlopen
# urlopen() 只能进行简单的请求,不支持在线验证,cookie,代理IP等复杂操作
opener = build_opener(cookie_handler) #相当于 urlopen()
# 走到下面这一步的时候,cookie_obj 就接受到了baidu的 cookie
response = opener.open('http://www.neihanshequ.com')
print(response)
for cookie in cookie_obj:
print('key:', cookie.name)
print('value:', cookie.value)
(2) 保存cookie
filename = 'neihan.txt'
# 设置cookie保存的文件
cookie_obj = LWPCookieJar(filename=filename)
cookie_handler = HTTPCookieProcessor(cookie_obj)
opener = build_opener(cookie_handler)
response = opener.open('http://www.neihanshequ.com')
# 保存cookie到指定的文件当中去
# ignore:忽略,discard:丢弃,抛弃,expires:到期,有效期
# ignore_expires=True, 即便目标cookie已经在文件中存在,仍然对其写入
# ignore_discard=True, 即便cookie已经/将要过期, 仍然将其写入
cookie_obj.save(ignore_expires=True, ignore_discard=True)(3)使用本地cookie进行登录
cookie = LWPCookieJar()
cookie.load('neihan.txt')
request = Request('http://www.neihanshequ.com')
cookie_handler = HTTPCookieProcessor(cookie)
opener = build_opener(cookie_handler)
response = opener.open(request)
# print(response.read().decode())3 lxml 简介
from lxml import etree
url = 'https://www.qiushibaike.com/hot/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url, headers=headers)
# print(response.content)
# 将字符串转化成html 代码
root = etree.HTML(response.content)
# element 元素, 节点, 标签
# // 从根标签开始找,找到类名为author clearfix的标签
# / 找到某一个标签下面的 a 标签
# text() 获取标签的文本
name_list = root.xpath('//div[@class="author clearfix"]/a/h2/text()')
print(name_list)
content_list = root.xpath('//div[@class="content"]/span/text()')
print(content_list)4 数据写入excel
import xlwt
def open_excel_file():
workBook = xlwt.Workbook(encoding='utf8')
sheet = workBook.add_sheet('这里sheet 表的名字')
# 值1: 行,索引从0开始
# 值2: 列, 索引从0开始
# 值3: 里面写的内容
sheet.write(0, 0, '职位名称')
sheet.write(0, 1, '薪资')
sheet.write(1, 2, '地点')
workBook.save('练习表1.xls')
open_excel_file()5 charles 简介
Charles 是常用的网络封包截取工具,在做 移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析
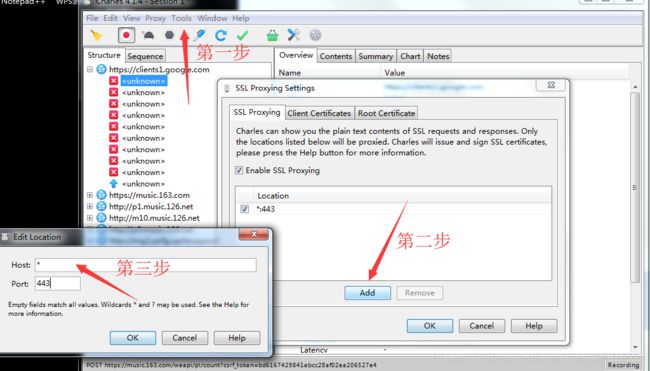

在浏览器中,每点击一次,它就会抓包
6 简单的模拟美食杰网站登录
cookie = LWPCookieJar(filename='美食杰__练习2.txt')
cookie_handler = HTTPCookieProcessor(cookie)
opener = build_opener(cookie_handler)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
post_url = 'https://i.meishi.cc/login.php?redirect=https%3A%2F%2Fwww.meishij.net%2F'
post_data = urlencode({
'username': '[email protected]',
'password': 'qwertyuiop'
})
request = Request(post_url, bytes(post_data, encoding='utf-8'))
ssl._create_default_https_context = ssl._create_unverified_context
response3 = opener.open(request)
cookie.save(ignore_discard=True, ignore_expires=True)
# 上面所有的内容是获得cookie,并保存到文件里,
# 就是你把账号密码输入后, 再取cookie,
# 下面的内容是用你上面获得的cookie再传入到request里,
# 获得网页的源码
cookie = LWPCookieJar()
cookie.load('美食杰__练习.txt', ignore_discard=True, ignore_expires=True)
opener = build_opener(HTTPCookieProcessor(cookie))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
request = Request('https://www.meishij.net/')
response4 = opener.open(request)
print(response4.read().decode())