Pointnet++如何运行
对与Pointnet++这个网络是一个基于和扩展Pointnet网络,pointnet网络(V1模型)可以独立的转换各个点的特征,也可以处理整个点集的全局特征,然而在多数情况下,存在明确定义的距离度量,例如,由3D传感器手机的3D电云的欧几里得距离或者注入等距形状表面的流形的测地距离。在pointnet++中,网络对点集的空间局部特征进行了处理。
本博文主要记录跑pointnet++时候遇到的几个问题,以及如何解决的。
pointnet++官网的运行环境是:在 Unbuntu14.04系统下,Python版本2.7,Tensorflow-GPU版本 1.2.0
本博文的运行的环境是:在Ubuntu18.04.1系统下, Python版本 3.6.2, Tensorflow-GPU版本 1.8.0
问题1:python版本不一致的问题
官网的代码运行的Python版本是2.7,本博文的Python版本是3.6.2,所以需要将所有的代码中出现 xrange 更改为range
所有需要print的部分都需要使用括号括起来。
问题2:缺少一些必要的库的问题
如果代码中缺少必须要是用的库,那么你需要安装相应的库。一些库可以使用pip命令进行安装,而有的一些自己编写的函数需要导入的则需要将它的路径添加到python的libary path中即可。
对于可以使用pip命令安装的库可以使则需要使用下面命令进行缺少库的安装。
pip3 install 库的名称
#例如,缺少numpy
pip3 install numpy
对于一些自己编写的需要导入,像这个里面的 modelnet_dataset.py 、modelnet_h5_dataset.py 等 就不能使用pip命令进行安装,这时就在终端中输入以下命令新建一个pth格式文件,(针对在pycharm中进运行代码的)
echo > pointnet++.pth使用右键点击 Open With Text Editor 打开文件后,在里面添加 需要导入自己编的函数的路径然后保存。

把保存后的文件复制到你的python的site-packages文件夹中,我的是在路径:/home/hui/anaconda3/lib/python3.6/site-packages中。这时候重新打开pycharm就会发现,找不到自己编写的库的问题已经解决。

问题3:如何进行编译tf_ops文件夹下的文件并得到 *so 和 *o 格式的文件
在tf_ops的文件夹下,有 3d_interpolation、grouping、sampling 三个文件夹,每一个文件夹中的文件都需要进行编译才能运行
1.如果你的环境配置和官方的环境配置一样,进入到sampling文件夹中(以这个编译为例,其他两个和这个一模一样),右击打开终端,输入下面命令就可以编译成功。
sh tf_sampling_compile.sh
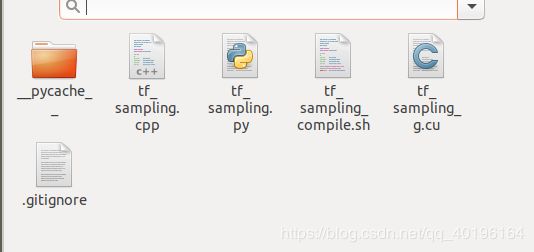
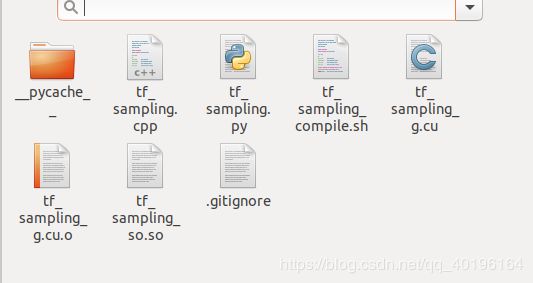
编译前: 编译成功后:
2.如果和官方的环境不一样(其实可以不用管tensorflow的版本,版本高的都用TF1.4 并将TF1.2下面的命令注释掉就行;低于1.4的你就用TF1.2下面的命令,将TF1.4注释掉),则需要修改 tf_sampling_compile.sh 文件中的内容。
修改前的内容,如下图所示。
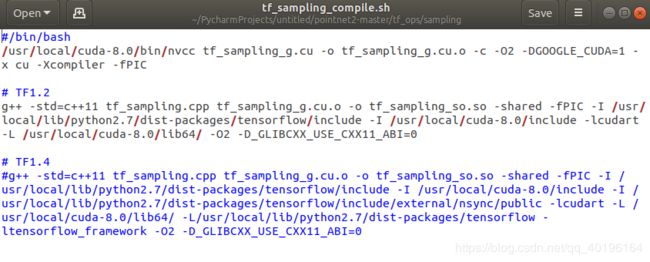
修改后的内容,如下图所示。
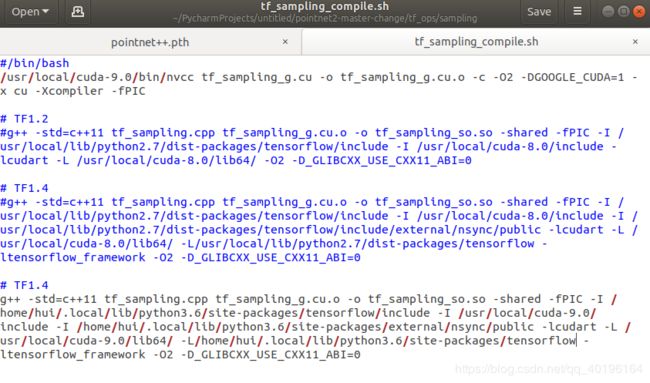
下面是对上面为什么这样修改的解释说明:
对于 /bin/bash 下面的修改,你需要找到你电脑中安装nvidia的cuda的位置,如果是默认安装位置一般情况下是在路径: /usr/local/cuda-9.0/bin/nvcc 下,如果记不清楚在哪里,直接文件夹的搜索,找到nvcc路径,并将 /usr/local/cuda-8.0/bin/nvcc l路径替换掉即可。
该前:

改后:

对于# TF1.4 下面的修改,需要替换掉5个路径
①路径:/usr/local/lib/python2.7/dist-packages/tensorflow/include 的替换。
你需要找到你自己的python下的tensorflow的安装包在哪里,我的使用的anaconda下的环境,路径在 /home/hui/.local/lib/python3.6/site-packages/tensorflow/include (如果你找不到,直接使用‘tensorflow’关键词进行搜索) ,然后替换掉原始文件中的路径 /usr/local/lib/python2.7/dist-packages/tensorflow/include 就行。
②路径: /usr/local/cuda-8.0/include 的替换
对于 /usr/local/cuda-8.0/include 命令,找到你的电脑中安装的cuda下的include路径即可(找不到,直接使用关键词‘cuda’ 进行搜索)。(我的是:/usr/local/cuda-9.0/include 替换掉 /usr/local/cuda-8.0/include)。
③路径: /usr/local/lib/python2.7/dist-packages/tensorflow/include/external/nsync/public 的替换。
这个是你所安装的tensorflow库文件夹下的public文件夹(不一定在tensorflow文件夹下,找不到直接用关键词‘external’搜索文件夹,找到后替换)。
我的路径是:/home/hui/.local/lib/python3.6/site-packages/external/nsync/public 替换掉 /usr/local/lib/python2.7/dist-packages/tensorflow/include/external/nsync/public
④路径: /usr/local/cuda-8.0/lib64/ 的替换。
跟②一样的方法,只要找到②,这个就一定能找到。我的路径:/usr/local/cuda-9.0/lib64/ 替换掉 /usr/local/cuda-8.0/lib64/
⑤路径: /usr/local/lib/python2.7/dist-packages/tensorflow 的替换。
跟①一样的方法,只要找到①,这个也一定能找到。我的路径:/home/hui/.local/lib/python3.6/site-packages/tensorflow 替换掉 /usr/local/lib/python2.7/dist-packages/tensorflow
替换掉上面路径后然后保存。
替换前:

替换后:

然后使用下面命令进行编译,得到 *o 和 *so 文件就说明编译成功。
sh tf_sampling_compile.sh编译成功后如下图所示:

tf_ops 文件夹下的 3d_interpolation 和 grouping 文件夹的编译方式和上面一样。
如果你使用单GPU进行训练到这里代码基本没有什么问题,可以正常训练。如果是多个GPU进行训练还需要解决下面的问题四。
问题4:tensorflow版本不同带来的问题
由于我这里是tensorflow1.8.0版本,官网是1.4版本,有些代码是不一样的,这里进行修改(很小的修改,大部分还是不需要改的)。
train_multi_gpu.py文件的186 和 188 行会报出下图的错误:

错误的代码 :
##train_multi_gpu.py文件中的186行和188行
pc_batch = tf.slice(pointclouds_pl,
[i*DEVICE_BATCH_SIZE,0,0], [DEVICE_BATCH_SIZE,-1,-1])
label_batch = tf.slice(labels_pl,
[i*DEVICE_BATCH_SIZE], [DEVICE_BATCH_SIZE])改正后的代码:
pc_batch = tf.slice(pointclouds_pl,
[int(i*DEVICE_BATCH_SIZE),0,0], [int(DEVICE_BATCH_SIZE),-1,-1])
label_batch = tf.slice(labels_pl,
[int(i*DEVICE_BATCH_SIZE)], [int(DEVICE_BATCH_SIZE)])到这里我碰到所有的问题已经解决,可以正常运行,下面是运行的结果。
运行结果
1.运行下面命令,在tensorboard中可视化。
tensorboard --logdir=log 

2.CPU的使用情况
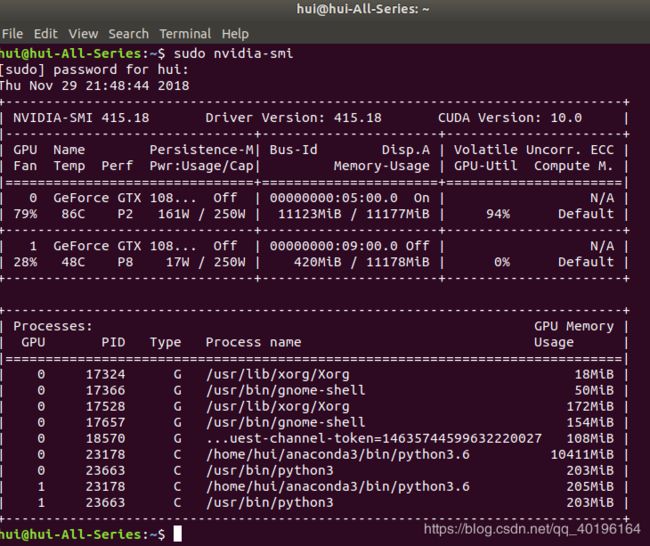
3. GPU的使用情况
4.使用 utils 文件夹下的 show3d_balls.py 文件可视化出来的结果。
