Python爬虫-urllib2(2)
Python爬虫-urllib2(2)
@(博客)[python, 爬虫, urllib2, Python, 代理]
- Python爬虫-urllib2(2)
- post请求方式
- 设置代理
- web客户端授权验证
- 处理需要登陆账号的爬虫(Cookie)
- a.直接cookie法实现豆瓣的登录
- b.cookielib之CookieJar实现人人网旧入口登录
- c.cookielib之LWPCookieJar
- 总结:
018.5.19
post请求方式
测试网页:http://fanyi.sogou.com/
打开chrome开发者工具,在搜狗的翻译框输入文字时,能看到浏览器有接受到数据


点开translate文件可以看到数据的请求方式
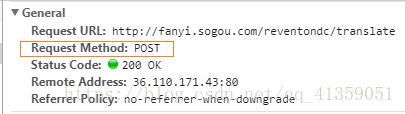
与get请求方式不同,如果是post请求浏览器会向服务器发送一个Form Data,如图:
并且我们需要注意的是,请求url和我们测试的网页地址不同,所以我们在写爬虫程序的时候url地址就不能写http://fanyi.sogou.com/
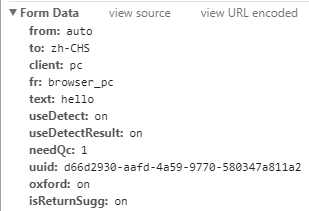
对应的,我们也需要构造一个Form Data,让服务器可以做出我们想要的回应。接下来我们需要对Form Data中的数据进行分析,判断是是否一成不变,如果有发生改变的就找出其中的规律。所以继续在翻译框中输入东西吧!
根据多次验证,发现只有text和uuid发生变化
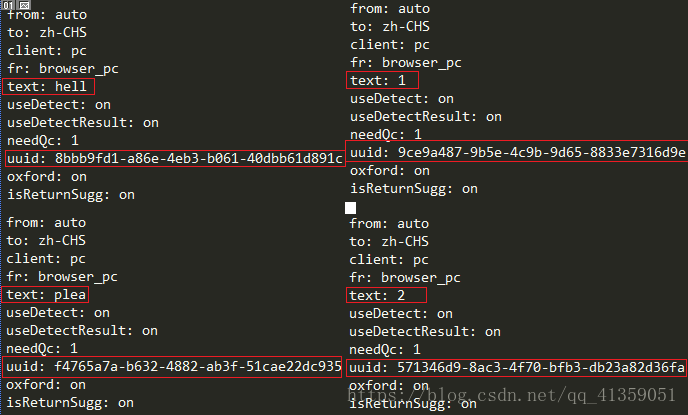
很明显的是text对应的值即是我们键入翻译框的值,即需要翻译的内容;而uuid是什么尚不得知,分析网页源码,也没有form表单(或许是我太菜吧),那我们先复制一个uuid来用一用吧(暴力操作)
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
# 构建头
headers = {
"Accept" : "application/json",
"Accept-Language" : "zh-CN,zh;q=0.9",
"Host" : "fanyi.sogou.com",
"Origin" : "http://fanyi.sogou.com",
"Referer" : "http://fanyi.sogou.com/",
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"X-Requested-With" : "XMLHttpRequest",
}
# 真实访问的url地址
url = "http://fanyi.sogou.com/reventondc/translate"
# form表单数据
data = {
"from": "auto",
"to": "zh-CHS",
"client": "pc",
"fr": "browser_pc",
"text": "please", #这里我们需要翻译的是please
"useDetect": "on",
"useDetectResult": "on",
"needQc": "1",
"uuid": "b0c3fe69-4f83-4b9d-aa5f-9493de6a47da",
"oxford": "on",
"isReturnSugg": "on",
}
# 进行url编码
data = urllib.urlencode(data)
# 构建请求与发送请求
request = urllib2.Request(url=url, data=data, headers=headers)
http_handler = urllib2.HTTPHandler()
opener = urllib2.build_opener(http_handler)
response = opener.open(request)
# 写入本地
with open("translate.json", "w") as ob:
ob.write(response.read())打开translate.json,数据顺利到手,成功
![]()
设置代理
可能有的时候我们不想暴露自己的真实ip地址,也可能是之前的暴力操作导致ip关进小黑屋,这个时候我们就需要设置代理。
用法:
proxy_handler = urllib2.ProxyHandler({"http":"ip:port"}) 参数是字典类型
opener = urllib.build_opener(proxy_handler)
推荐一个免费代理ip的网址:http://www.xicidaili.com/nn/,当然免费的代理ip极不稳定,在这里我们只是测试,所以无所谓了。
利用上一小节python快速搭建网页的技巧,搭建一个简易的网页。

我们可以看到,如果访问成功,会返回响应状态码200,并且最左有ip地址,上述方法是否真能代理ip尚不可知,毕竟实践出真知嘛,所以试一试。
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
url = "http://118.**.***.25:8000/"
# 代理ip:port
proxy = {
"http":"171.37.166.0:8123"
}
# 由于访问的是自己搭建的网页,所以连报文头的构建也省了
request = urllib2.Request(url)
proxy_handler = urllib2.ProxyHandler(proxy)
opener = urllib2.build_opener(proxy_handler)
response = opener.open(request)
# 输出状态码
print response.getcode()
结果:
![]()
返回响应状态码200,表示访问成功
查看我们搭建网页的终端,访问的ip地址是不是就是我们的代理ip,说明代理成功。
![]()
如果是私密代理,构建方式为:id:password@ip:port
web客户端授权验证
区别于一般网页的会员登陆,而是呈现出这样

处理方法:
wdmgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
wdmgr.add_password(None, webserver, user, password) webserver可以简单的看做url地址
http_auth_handler = urllib2.HTTPBasicAuthHandler(wdmgr)
后面的方法就大同小异了,构建一个opener等等不累述,也不做测试(感觉不常遇到)
处理需要登陆账号的爬虫(Cookie)
查看我们的求情报文头,一般都是有cookie值的。在我们访问某个网站,会员登陆之后,cookie值负责记录了我们的登陆信息,让我们可以在这个网站的各个子网页中来回切换而不再需要输入账号和密码。
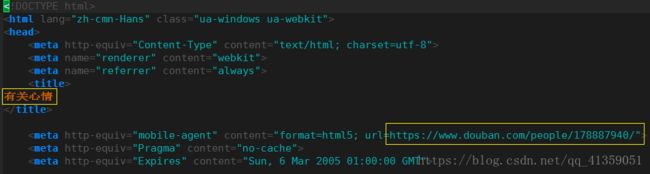
a.直接cookie法实现豆瓣的登录
在我们登录网站后,浏览器中的cookie值就包含了我们的登陆信息,这个时候我们可以直接使用,也正是这个原因,我们登录之后的cookie值最好不要公布网络上
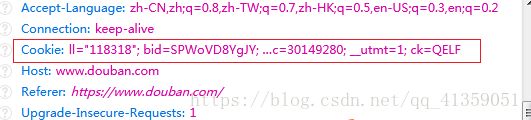
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
import cookielib
# 人人网主页url地址
urlMain = "https://www.douban.com/people/178887940/"
# 报文头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
'Cookie': 'll="118318"; bid=SPWoVD8YgJY; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1526824349%2C%22https%3A%2F%2Fwww.baidu__utmz=30149280.1526824350.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="178887940:iNBoqHbREwg"; push_doumail_num=0;_pk_ses.100001.8cb4=*; __utmb=30149280.4.10.1526824350; __utmc=30149280; __utmt=1; ck=QELF',
#原cookie很长,我随意删除了部分
}
httpHandler = urllib2.HTTPHandler()
opener = urllib2.build_opener(httpHandler)
requestMain = urllib2.Request(url=urlMain, headers=headers)
response = opener.open(requestMain)
# 输出状态码和真实访问地址
print response.geturl()
print response.getcode()
# 写入本地
with open("douban.html", "w") as ob:
ob.write(response.read())运行后

打开douban.html可知,实验成功
b.cookielib之CookieJar实现人人网旧入口登录
需要引入的库是:cookielib
常用库中的对象(这里只介绍两个):CookieJar(),LWPCookieJar(),需要实现与本地的交互就用后者
用法:
cookie = cookielib.CookieJar()
http_handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(http_handler)
这里我们利用人人网的旧入口做个实验吧
首先我们需要知道form表单的相关内容,所以这里需要一些前端知识(为了不使篇幅累赘冗长,所以不做知识的扩充):

根据这个图我们能知道form表单post的内容是email,password,目标url地址是是:http://www.renren.com/PLogin.do
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
import cookielib
# 人人网的旧入口
url = "http://www.renren.com/PLogin.do"
# 构造报文头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
# 实例化一个CookieJar的对象,并且放入cookie处理器中,构建一个opener对象
cookie = cookielib.CookieJar()
httpCookieHandler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(httpCookieHandler)
# post请求方式,构造form表单,传输给后台
data = {
"email":"184*****795",
"password":"151*********guan",
}
# 使用之前需要url编码
postData = urllib.urlencode(data)
request = urllib2.Request(url=url, headers=headers, data=postData)
response = opener.open(request)
print response.geturl()
with open("renren.html", "w") as ob:
ob.write(response.read())打开renren.html查看
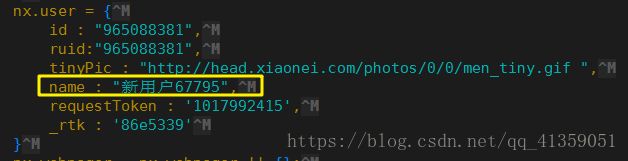
实验成功
c.cookielib之LWPCookieJar
可以实现与本地交互的还有MozillaCookieJar,之所以不使用,是因为MozillaCookieJar保存本地的cookie不易人眼识别,而LWP的可观行很强

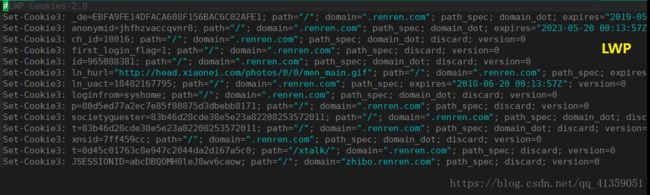
当然,一切看个人喜好,除了类的实例化时使用的类不同,其他使用方式一样。先下先说LWPCookieJar
用法:
filename = "cookie" 设置需要保存的本地文件,不需要手动创建,赋名就好
lwpCookie = cookielib.LWPCookieJar() 实例化LWPCookieJar
httpCookieHandler = urllib2.HTTPCookieProcessor(lwpCookie) 这之后与CookieJar一样
......
lwpCookie.save(filename, True, True) 保存cookie值到本地
lwpCookie.load(filename, True, True) 加载本地文件中的cookie值
上一个完整的代码事例
文件A,负责模拟登陆,并且将登陆之后的cookie写入本地
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
import cookielib
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
url = "http://www.renren.com/PLogin.do"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
# 如果用mozilla,实例化就mozillaCookie = cookielib.MozillaCookieJar(),此时需要设置的文件命名最好填上“.txt”后缀
lwpCookie = cookielib.LWPCookieJar()
httpCookieHandler = urllib2.HTTPCookieProcessor(lwpCookie)
opener = urllib2.build_opener(httpCookieHandler)
data = {
"email":"184*****795",
"password":"151********guan",
}
postData = urllib.urlencode(data)
request = urllib2.Request(url=url, headers=headers, data=postData)
response = opener.open(request)
# cookie值写入本地
lwpCookie.save("cookie", True, True)
print response.geturl()
print response.getcode()文件B,负责读取本地的cookie,并且去访问需要登陆之后才能看到的页面
#!/usr/bin/env python
# coding=utf-8
import urllib2
import cookielib
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# 访问主页的url地址
url = "http://www.renren.com/965088381/profile"
lwpCookie = cookielib.LWPCookieJar()
# 加载本地的cookie值
lwpCookie.load("cookie", True, True)
httpCookieHandler = urllib2.HTTPCookieProcessor(lwpCookie)
opener = urllib2.build_opener(httpCookieHandler)
# 加载头文件,第一小节有提到过
opener.addheaders = [('User-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36')]
response = opener.open(url)
print response.geturl()
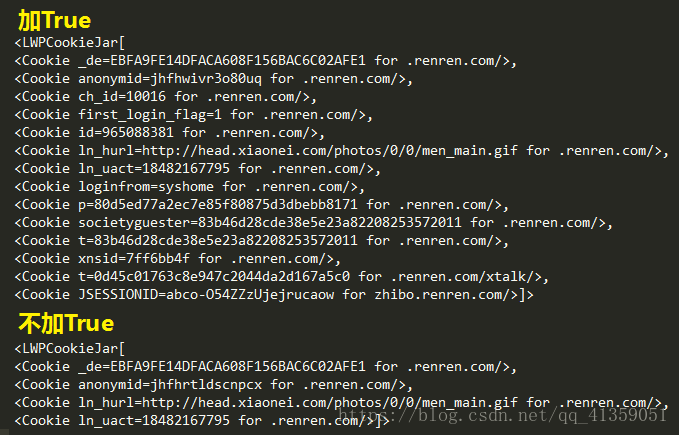
print response.getcode()需要说明的是:网上有许多教程在保存cookie值时,都是直接使用的lwpCookie.save(),即没有参数,而文件路径写在了对象实例化处,如:lwpCookie = cookielib.LWPCookieJar(filename),也是可以的;但不同的是,在save()的时候仍需要加形参两个True,帮助文档如下:
![]()
初学时仿照网上,我也没有加,cookie值出现了缺失,造成B文件怎么都不能正确访问主页,我也不知道网上写教程的人是如何可以成功使用的,还是说一味的照抄不求甚解呢?如果各友知其详情,勿忘赐教
总结:
构建opener的方法urllib2.build_opener()需要传参,参数常用以下几个类的实例化:
HTTPHandler()直接使用
ProxyHandler()需要构建代理ip,参数为字典形式
HTTPCookieProcessor()需要导入cookielib,并实例化相关对象(CookieJar,LWPCookieJar)