Python爬虫-速度(1)
Python爬虫-速度(1)
文章目录
- Python爬虫-速度(1)
- 前言
- 网页分析
- 接口设计
- 运行效果
018.9.16
Python爬虫-速度(2)
Python爬虫-速度(3)
前言
其实爬虫的整个基本流程已经讲完了。无论是如何发起请求,还是解析文件,再到存储,以及处理需要js渲染的网页。入门需要掌握的,也不过这些而已。只是可能还不够,比方说速度。在我们不想用框架,如scrapy,但仍想为程序提速的时候,应该怎样解决呢?
我认为大概可以从多进程,多线程,协程,以及异步上进行考虑。但我不建议把速度提升到极致,这里有两个理由:第一,同一IP短时间内请求频率过高,会带来封IP的反扒策略,当然,你可以使用海量代理IP;第二,也是我认为更重要的一点,请求频率过高可能会造成网站服务器宕机,对方运维人员日子会不好过的,大家都是混口饭吃,所以何必。
【速度篇】预计分三部分来写吧,第一部分主要写一个普通的爬虫程序,第二部分会是关于什么是多进程线程之类的,第三部分则是前面的结合——用第二部分中的内容来改写第一部分的爬虫程序。最后通过打印程序运行时间,来简单验证速度是否得到提升。
程序是讲究实用性的。老实说,我感觉自己在爬虫里遇到了瓶颈,不但是技术上的,更是使用上的。可以用个类比来解释我现在的困境:因为觉得无处使力,而不知自己力的天花板,所以也无法通过修炼来提升自己的力气。我确实没什么要爬取的数据了,这是早晚的事,毕竟我是出于兴趣而非任务,爬完自己的“兴趣”,便不知路往何方。
但生活总有给你一个“偶尔”使力的机会,只要你能发现。
最近秋招开始,学校的就业信息网陆续更新了一些公司的宣讲会时间,教室,职位要求等。而每次打开浏览器去阅览是有点麻烦的事儿,因为学校的每个网站都不以用户的角度思考。这些不必细说,想你们也是深有体会的。所以今天的爬虫程序就以此为背景,将所有职位爬取下来保存本地。为每个公司创建一个文件夹,里边包含职位详情的txt文件,以及招聘简章的doc文件,具体效果如下:

网页分析
目录页(http://www.swpu.edu.cn/zsjy/info/1056/1922.htm)
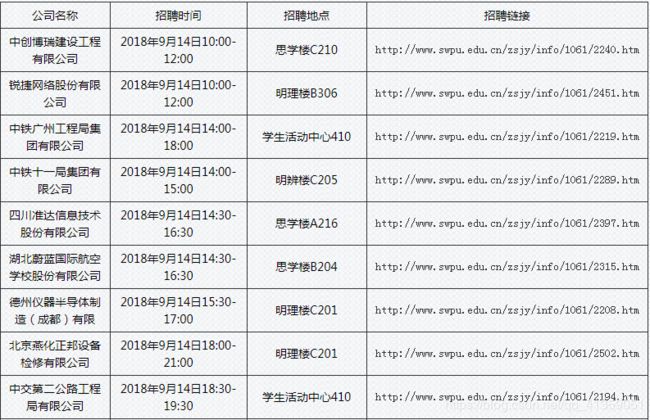
点击职位对应的招聘链接,即进入详情页
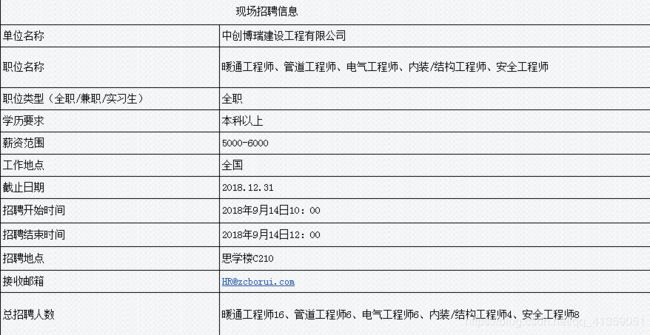
详情页页底,会有招聘简章的链接,一般为docx文件,少部分会是pdf或者excel,或者没有。由于这个爬虫程序主要用来“改写”,所以按“少数服从多数”策略,都以docx文件来处理

接口设计
首先我写了一个函数,用来请求网页
def get_one_html(url, tries=3):
"""获取一个网页"""
try:
response = requests.get(url, headers=HEADERS)
except error.HTTPError:
if tries <= 0:
return None
else:
get_one_html(url, tries-1)
else:
response.encoding = response.apparent_encoding
bag.html = response.text
bag.url = response.url
return bag
该函数返回一个bag包,其实是一种类似tuple的数据结构,创建方式:
bag = namedtuple("html_link", ["html", "url"])
之后解析目录页的数据,主要提取公司名,宣讲会时间,宣讲会地点,详情页链接(其实中间两个并没有用到)
def extract_html(html):
"""提取网页内容"""
selector = etree.HTML(html)
roots = selector.xpath('//div[@id="vsb_content"]//tbody/tr')
for root in roots[1:]:
company = root.xpath("./td[1]/text()")
time = root.xpath("./td[2]/text()")
position = root.xpath("./td[3]/text()")
link = root.xpath("./td[4]/a/@href")
yield {
"company": "".join(company),
"time": "".join(time),
"position": "".join(position),
"link": "".join(link),
}
该函数是yield出去一个字典,实际上使用了协程的思想
既然拿到了详情页链接,自然是要请求这个链接拿到html的,请求网页依然可以让get_one_html()函数来负责;解析则需要另写一个函数
def extract_detail_html(bag):
"""提取详情页内容"""
doc = pq(bag.html)
data = doc("#vsb_content_100 tr").text()
# 文本信息
result = map(lambda x: x.replace("\n", ":"), [item for item in data.split(" ") if item])
# 招聘简章链接
link = doc(".Main tr td span > a").attr("href")
return (result, parse.urljoin(bag.url, link))
这里解析用的是PyQuery库,这是因为它的一个text()方法可以直接拿出某个节点,以及其子节点,孙节点中的文本信息,很是方便。该函数返回文本,以及拼接过的docx文件链接
最后是将数据保存到本地
def save_to_txt(dirname, url, data):
"""将数据保存到txt文件中
目录名,详情页url, 详情页内容"""
with open("data/{}/详情.txt".format(dirname), "w", encoding="utf-8") as file:
for item in chain([url], data):
file.write("{0}\n{1}\n".format(item, "-"*50))
def download_doc(dirname, url, referer):
"""下载对应的doc文档
目录名,doc的url,详情页的url"""
headers = {"Referer": referer}
headers.update(HEADERS)
try:
response = requests.get(url, headers=headers)
except error.HTTPError:
pass
else:
# 二进制文件需要wb
with open("data/{}/招聘简章.doc".format(dirname), "wb") as file:
file.write(response.content)
这里主要需要注意的是【招聘简章】的链接,如果我们直接用这个链接去访问,会跳转到输入验证码的页面,但如果在详情页点击这个链接,就能直接下载。原因是请求头需要加入{“Referer”: referer},这个referer值就是当前详情页的链接
程序完整如下:
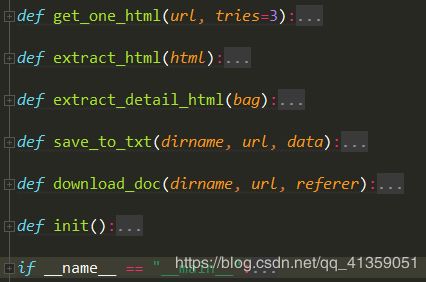
运行效果
运行之后效果如下:
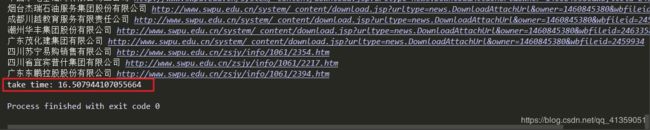
耗时约为16.5秒
此次代码已上传GitHub