机器学习-初级入门(回归算法-多种线性回归算法详解)
一、简单线性回归-最小二乘法求解
-
基本公式推导

这里需要满的条件是(XTX)-1存在的情况。在机器学习中,(XTX)-1不可逆的原因通常有两种,一种是自变量间存在高度多重共线性,例如两个变量之间成正比,那么在计算(XTX)-1时,可能得不到结果或者结果无效;另一种则是当特征变量过多,即复杂度过高而训练数据相对较少(m小于等于n)的时候也会导致(XTX)-1不可逆。(XTX)-1不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。 -
根据直接得出的结论求解参数
def split_train_test(filename): """ 划分测试集、训练集 :param filename: 文件路径 :return: """ data = pd.read_csv(filename) data.insert(0, "S", 1) # 因为求逆至少需要两个维度,添加一个维度 train_data = data.sample(frac=0.7, random_state=0, axis=0) test_data = data[~data.index.isin(train_data.index)] return train_data, test_data def load_dataset(data): """ 将数据划分为因变量、自变量 :param data: 数据 :return: """ x_arr = data.iloc[:, :-1].values y_arr = data.iloc[:, -1].values return x_arr, y_arr def stand_regres(X, y): """ 根据公式求出θ :param X: :param y: :return: """ X = np.mat(X) y = np.mat(y).T xTx = X.T * X if np.linalg.det(xTx) == 0.0: print("This matrix is singular, cannot do inverse") return theta = xTx.I * X.T * y return theta def forecast(X, theta): """ 预测数据 :param X: :param theta: :return: """ y_hat = np.mat(X) * theta return y_hat def plot_line(X_test, y_test, y_test_hat, X_train, y_train, y_train_hat, plot_X_test=None, plot_X_train=None): fig = plt.figure(figsize=(8, 4)) # 规定画图域大小,宽4高5 test_ax = fig.add_subplot(1, 2, 1) # 显示2行3列第1个图 train_ax = fig.add_subplot(1, 2, 2) test_ax.scatter(X_test[:, 1], y_test, s=30, alpha=0.5, label="origin data") test_ax.plot(plot_X_test, y_test_hat, linewidth=3, color="r", label="forecast data") test_ax.set_xlabel("YearsExperience") test_ax.set_ylabel("Salary") test_ax.set_title("test-salary-data") test_ax.grid() test_ax.legend(loc="upper right") train_ax.scatter(X_train[:, 1], y_train, s=30, alpha=0.5, label="origin data") train_ax.plot(plot_X_train, y_train_hat, linewidth=3, color="r", label="forecast data") train_ax.set_xlabel("YearsExperience") train_ax.set_ylabel("Salary") train_ax.set_title("train-salary-data") train_ax.grid() train_ax.legend(loc="upper right") plt.show() train_data, test_data = split_train_test("Salary_Data.csv") X_train, y_train = load_dataset(train_data) X_test, y_test = load_dataset(test_data) theta = stand_regres(X_train, y_train) y_test_hat = forecast(X_test, theta) y_train_hat = forecast(X_train, theta) plot_line(X_test, y_test, y_test_hat, X_train, y_train, y_train_hat, plot_X_test=X_test[:, 1], plot_X_train=X_train[:, 1]) print("corrcoef:\n", np.corrcoef(y_test, y_test_hat.T))
二、梯度下降求线性回归参数
-
基本公式

-
根据假设条件推出损失函数
所有样本独立同分布(iid),且误差项服从以下分布:
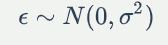
用最小二乘法与以上假设的关系推导如下:

使用MLE(极大似然法)估计参数如下:

-
利用梯度下降求出w,为了方便展示求导过程以简单的二维做展示

代价函数

对代价函数求导:
对θ0求偏导

对θ1求偏导
通过迭代更新θ0,θ1, α为学习率

-
注意事项
在解决实际问题中,往往会出现x里的各个特征变量的取值范围间的差异非常大,如此会导致在梯度下降时,由于这种差异而使得J(θ)收敛变慢,特征缩放便是解决该类问题的方法之一,特征缩放的含义即把各个特征变量缩放在一个相近且较小的取值范围中,例如-1至1,0.5至2等,其中,较简单的方法便是采用均值归一化,也就是标准化处理。
处理代码:def stander(X): """ 标准化数据 :param X: :return: """ x_mean = np.mean(X, 0) x_std = np.std(X, 0) np.seterr(divide="ignore", invalid='ignore') # xVar中存在0元素 # 特征标准化: (特征-均值)/方差 X = (X - x_mean) / x_std return X -
代码实现(批量梯度下降):
def compute_cost(X, y, theta): m, n = X.shape e = X.dot(theta) - y j = 1/(2*m) * e.T.dot(e) return j def gradient_descent(X, y, alpha, theta, num_iters): m, n = X.shape J = np.zeros((num_iters, 1)) y = np.mat(y).T for i in range(num_iters): y_hat = X.dot(theta) - y for j in range(n): theta[j] = theta[j] - alpha / m * y_hat.T.dot(np.mat(X[:, j]).T) J[i] = compute_cost(X, y, theta) return theta, J def gradient_train(X, y, alpha, num_iters): m, n = X.shape theta = np.zeros((n, 1)) theta, J_history = gradient_descent(X, y, alpha, theta, num_iters) return theta, J_history theta, J_history = gradient_train(X_train, y_train, 0.01, 500) y_hat = X_test.dot(theta) plt.scatter(X_test[:, 1], y_test) plt.plot(X_test[:, 1], y_hat) plt.show()随机梯度下降:
def gradient_descent(X, y, alpha, theta, num_iters): m, n = X.shape J = np.zeros((num_iters, 1)) y = np.mat(y).T for i in range(num_iters): # 随机梯度下降 index = np.random.randint(0, m) y_hat = X[index].dot(theta) - y[index] for j in range(n): theta[j] = theta[j] - alpha / m * y_hat * X[index, j] J[i] = compute_cost(X, y, theta) return theta, J
三、局部加权线性回归
-
基本公式推导


-
注意事项
当数据特征比训练集样本点还多时,也就是说不可逆,矩阵求导无计可施。 此时就要用缩减样本来“理解”数据,求得回归系数矩阵。 -
代码实现
def lwlr(testPoint, X, y, k=1.0): """ :param testPoint: 每个特征向量 :param X: 训练集自变量 :param y: 训练集因变量 :param k: 权重系数 :return: 每个标签向量测试结果 """ X = np.mat(X) y = np.mat(y).T m = np.shape(X)[0] weights = np.mat(np.eye(m)) # 创建对角矩阵, 阶数为样本点个数 for i in range(m): diffMat = testPoint - X[i, :] weights[i, i] = np.exp(diffMat * diffMat.T / (-2.0 * k**2)) # 权重大小以指数级别衰减, 矩阵乘矩阵转置等于矩阵模 xTx = X.T * (weights * X) if np.linalg.det(xTx) == 0.0: print("This matrix is singular, cannot do inverse") return theta = xTx.I * (X.T * (weights * y)) return testPoint * theta def lwlr_forecast(testArr, X, y, k=1.0): """ 预测测试集数据 :param testArr: 测试数据 :param X: 训练集自变量 :param y: 训练集因变量 :param k: 权重系数 :return: 测试结果 """ m = np.shape(testArr)[0] y_hat = np.zeros(m) for i in range(m): y_hat[i] = lwlr(testArr[i], X, y, k) return y_hat def rssError(yArr,yHatArr): # yArr and yHatArr both need to be arrays ''' :param yArr: 真实数据 :param yHatArr: 预测数据 :return: 误差大小 ''' return ((yArr-yHatArr)**2).sum() # 误差平方和 y_train_hat = lwlr_forecast(X_train, X_train, y_train, k=1.0) y_test_hat = lwlr_forecast(X_test, X_train, y_train, k=1.0) X_test_min, X_test_max, X_train_min, X_train_max = X_test[:, 1].min(), X_test[:, 1].max(), X_train[:, 1].min(), X_train[:, 1].max() N = 100 k_list = [0.5, 1, 10] plot_X_test = np.array([[1.0] * N, list(np.linspace(X_test_min, X_test_max, N))]).T plot_X_train = np.array([[1.0] * N, list(np.linspace(X_train_min, X_train_max, N))]).T for k in k_list: plot_y_train_hat = lwlr_forecast(plot_X_train, X_train, y_train, k=k) plot_y_test_hat = lwlr_forecast(plot_X_test, X_train, y_train, k=k) plot_line(X_test, y_test, plot_y_test_hat, X_train, y_train, plot_y_train_hat, plot_X_train=plot_X_train[:, 1], plot_X_test=plot_X_test[:, 1]) print("corrcoef:\n", np.corrcoef(y_train[srtInd_train], y_train_hat.T))
四、岭回归(ridge)
-
基本公式推导

-
代码实现
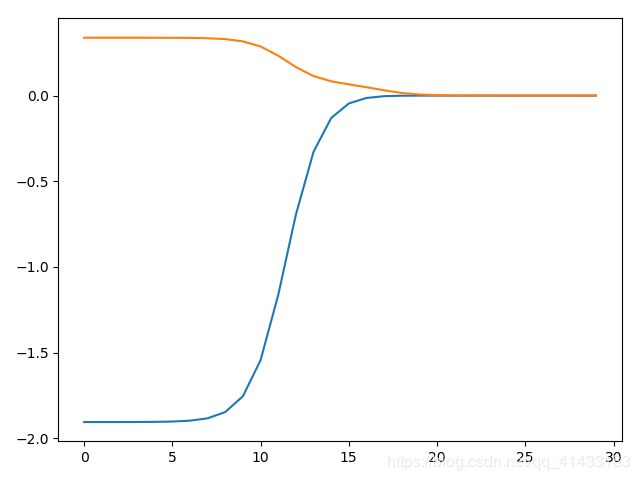
def ridge_regres(X, y, lamda=0.2): """ 计算不同惩罚因子计算的权重值 :param X: 自变量 :param y: 因变量 :param lamda: 惩罚因子 :return: 不同惩罚得出的权重 """ xTx = X.T * X denmo = xTx + np.eye(np.shape(X)[1]) * lamda if np.linalg.det(denmo) == 0.0: print("This matrix is singular, cannot do inverse") return theta = denmo.I * (X.T * y) return theta def stander(X): """ 标准化数据 :param X: :return: """ x_mean = np.mean(X, 0) x_std = np.std(X, 0) np.seterr(divide="ignore", invalid='ignore') # xVar中存在0元素 # 特征标准化: (特征-均值)/方差 X = (X - x_mean) / x_std return X def ridge_test(X, y): """ 利用梯度下降优化θ :param X: 训练集自变量 :param y: 训练集因变量 :return: 训练后的θ向量变化 """ X = np.mat(X) y = np.mat(y).T number_test_pts = 30 # 迭代次数 w = np.zeros((number_test_pts, np.shape(X)[1])) for i in range(number_test_pts): lamda = np.exp(i - 10) # 手动给定λ theta = ridge_regres(X, y, lamda=lamda) w[i, :] = theta.T return w def ridge_forecast(X, theta): """ 预测测试集数据 :param X: 测试集自变量 :param theta: 训练的θ向量 :return: 预测结果 """ return np.mat(X) * theta y_train = stander(y_train) y_test = stander(y_test) w = ridge_test(X_train, y_train) plt.plot(w) plt.show() # 选出最好的lamda值 theta = ridge_regres(np.mat(X_train), np.mat(y_train).T, lamda=np.exp(-2.5)) y_test_hat = ridge_forecast(X_test, theta) y_train_hat = ridge_forecast(X_train, theta)w的输出图:
五、lasso回归
-
基本公式推导

Lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。
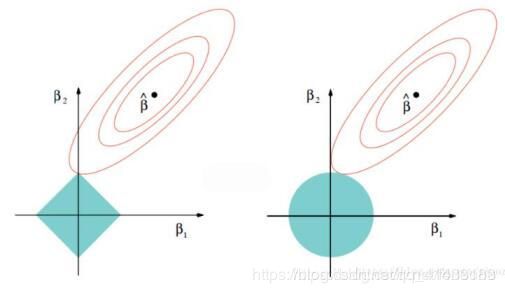
左图对应于Lasso方法,右图对应于Ridge方法
等高线和约束域的切点就是目标函数的最优解,Ridge方法对应的约束域是圆,其切点只会存在于圆周上,不会与坐标轴相切,则在任一维度上的取值都不为0,因此没有稀疏;对于Lasso方法,其约束域是正方形,会存在与坐标轴的切点,使得部分维度特征权重为0,因此很容易产生稀疏的结果。所以,Lasso方法可以达到变量选择的效果,将不显著的变量系数压缩至0,而Ridge方法虽然也对原本的系数进行了一定程度的压缩,但是任一系数都不会压缩至0,最终模型保留了所有的变量。
以二维空间为例,约束域在L1中,为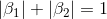 ,对应左图蓝色。
,对应左图蓝色。
约束域在L2中,为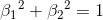 ,对应右图蓝色。
,对应右图蓝色。 -
代码实现(逐步向前法,主要用于降维)
def stageWise(X, y, eps=0.01, numIt=250): """ 利用梯度下降优化权重 :param X: 自变量 :param y: 因变量 :param eps: 学习率 :param numIt: 迭代次数 :return: 权值变化向量 """ X = np.mat(X) y = np.mat(y).T m, n = np.shape(X) # 将每次迭代中得到的回归系数存入矩阵 returnMat = np.zeros((numIt, n)) # testing code remove ws = np.zeros((n, 1)) # 初始化所有权重都是1, ws_max = ws.copy() # wsMax = ws.copy() for i in range(numIt): # 迭代次数 # 初始化最小误差为正无穷 lowestError = np.inf for j in range(n): # 遍历每个特征 for sign in [-1, 1]: # 对每个特征的系数增加和减少eps*sign操作 ********* # 改变系数 ws_test = ws.copy() ws_test[j] += eps * sign y_test = X * ws_test # 预测值 # 新的误差 rssE = rssError(y.A, y_test.A) # 与所有误差比较后,取得最小误差 if rssE < lowestError: lowestError = rssE ws_max = ws_test ws = ws_max.copy() returnMat[i, :] = ws.T return returnMat w = stageWise(X_train, y_train) plt.plot(w) plt.show()w的输出图:
