利用MapReduce实现好友推荐
MapReduce的好友推荐案列:
推荐好友的好友
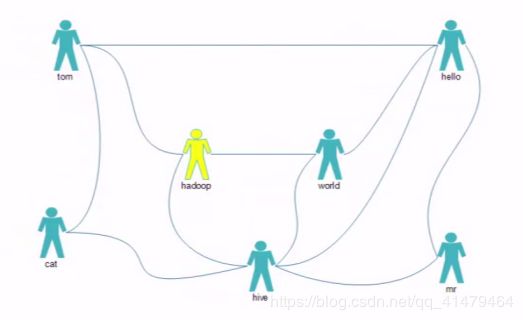
是简单的好友列表的差集吗?
最应该推荐的好友TopN,如何排名?
简单数据集:
tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr
思路:
分析:第一个为直接好友,也就是说,Tom 和hello 和hadoop 和cat是直接好友关系,而他们之间是 间接好友关系,但是间接好友 关系不一定就不是直接 好友关系,而我们要找的就是间接好友的关系,
推荐者与被推荐者一定有一个或多个相同的好友
全局去寻找好友列表中两两关系
去除直接好友
统计两两关系出现次数
API:
map:按好友列表输出两俩关系
reduce:sum两两关系
再设计一个MR
生成详细报表
生成表的结果:

运行:

代码如下:
第一部分:主函数:
MyFOF:
package sxt_TopN;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyFOF {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,MyFOF.class.getSimpleName());
job.setJarByClass(MyFOF.class);
//map
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
//reduce
job.setReducerClass(FReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//submit
job.waitForCompletion(true);
}
}
Map阶段:
package sxt_TopN;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FMapper extends Mapper
Text mkey = new Text();
IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper
throws IOException, InterruptedException {
String line = value.toString();
//按空格进行分割
String splits[] = line.split(" ");
//tom hello hadoop cat
//world hadoop hello hive
/**
* 直接好友关系值为0
* 间接好友关系值为1
*
*/
for (int i = 0; i < splits.length; i++) {
mkey.set(getF(splits[0],splits[i]));
mval.set(0);
context.write(mkey, mval);
for (int j = i+1; j <splits.length ; j++) {
mkey.set(getF(splits[i],splits[j]));
mval.set(1);
context.write(mkey, mval);
}
}
}
public String getF(String s1,String s2){
if(s1.compareTo(s2)<0){
return s1+":"+s2;
}
else {
return s2+":"+s1;
}
}
}
Reduce阶段:
package sxt_TopN;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FReduce extends Reducer
@Override
protected void reduce(Text key, Iterable
Reducer
/**可能有间接关系也可能有直接关系
* hadoop hello 0
* hadoop hello 1
* cat hadoop 1
* cat hadoop 0
* cat hadoop 1
*
* 拿到了所有的间接关系,次数来进行累加,最后就知道共同可以推荐的好友有多少个了
*
*
*
*/
int flg = 0;
int sum = 0;
for (IntWritable val : values) {
if(val.get()==0){
flg=1;
}
//如果一直为1n那就是间接关系然后就累加几次
sum +=val.get();
}
if(flg==0){
context.write(key, new IntWritable(sum));
}
}
}