faster r-cnn论文综述
faster r-cnn论文综述
摘要:本文提出了rpn网络用于提取预选框,可与检测网络共享图片的卷积特征,而且几乎无额外开销。rpn网络能够同时预测每个位置的目标边界和目标得分。
注:这种先生成预选区后对预选区进行检测分类的网络就叫做注意力机制的神经网络(neural networks with “attention” mechanisms)。可做到5fps。
1、 引言
r-cnn和sppnet中的selective search生成预选区很耗时(2s),edgebox也很耗时(0.2s),因为这种方法都是在cpu上运行的,一种思路是把这种方法在GPU上复现,但是在gpu上复现就忽略了下游的检测网络,就错过了共享计算的机会,(主要是值rpn能在gpu上做,且能共享卷积计算。),于是引出了rpn网络。
为把rpn网络和检测网络整合到一块,提出了一种轮流训练rpn网络和检测网络的方法。
2 相关工作
预选区:引出一些用组合超像素提取预选区的方法,如Selective Search,CPMC,MCG,还有基于滑动窗口的方法,如objectness in windows, EdgeBoxes。
为了目标检测的深度网络:r-cnn主要作为分类器,如果用作目标检测还要专门训练一个检测框回归器,检测准确度依赖于预选区框的对不对。
3 faster r-cnn
faster r-cnn由两个模块组成,第一个是全卷积神经网络用于提取预选区,第二个是对预选区做检测的Fast r-cnn检测器。
3.1 rpn网络
rpn网络是一个全卷积网络,以一张任意大小的图片作为输入,输出是一系列带有得分(是对象或背景)的检测框,这些检测框是卷积层最后一层输出的fm上的检测框。
为了生成fm上的region,需要用一个小网络在卷积层上取一个(或k个)预定的窗口,这个窗口在fm上的每个像素点上滑动,用这个窗口在每个像素点位置提取目标得分并回归框在最初的fm上的位置,这个窗口就是anchor。
这个rpn中的小网络架构:1*卷积层+relu+2个同级的全连接层。
第一个卷积层用于把输入的固定大小anchor从高维映射到低维(若ZF映射到256维,若VGG映射到512维),2个同级全连接层一个用来做回归一个用来做分类(是否是目标或背景)。
注:因为每个像素点输入的anchor都是固定大小的(即使有多个Size的anchor也是固定大小的),所以全连接层都能用。
3.1.1 anchors
每个像素点设置了3种大小3种高宽比共计9种anchor。所以一个WH的fm上就会一共有WH*9个anchor。
anchor平移不变性:废话,都anchor固定大小了,而且fm的每个位置都过一遍,肯定目标在图像的哪个位置都一样了。
多尺度的Anchors:有两种思路做多尺度预测,一个是图像金字塔,在DPM, sppnet和fast r-cnn中用的就是这种思路,这种方法很耗时。还有一个方法就是就是使用多尺度(多种高宽比)滑动窗口,这种方法可以成为“滤波器金字塔”(yolo中好像用的是这种?)。这两种方法一般是结合着用的。
本文用的是anchor金字塔(实际就是滤波器金字塔)。
3.1.2 损失函数
为了训练rpn网络,每个anchor都要预测一个二分类值(0代表背景即negative,1代表目标即positive)。
anchor的标签值如何打?
两种确定正例的方法(同时使用):(1)anchor映射到原图上与真实标签iou最大的算是正例,这是为了保证每个真实标签都至少有一个对应的anchor为正例,训练时此anchor对应的分类标签值就是1。(2)每个Anchor,如果与任意一个真实物体的标签框的
iou值>0.7就认为是正例,这样就有可能某个物体对应着多个正例anchor。
确定负例的方法:不满足为正例的任意一个条件,且与任意真实物体标签框的iou值小于<0.3时的anchor都是负例,训练时此anchor对应的分类标签值为0。
对于iou介于0.3和0.7之间的anchor,不用,即在损失函数中完全不表现出来。
损失函数与Fast r-cnn中用的一样:
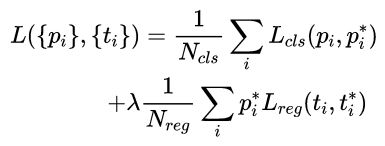
分类损失Lcls: 真实分类标签值*log(预测分类标签值),累加后除以(256)(mini-batch=256)。
回归损失Lreg: 跟fast r-cnn中Lloc损失函数差不多就是Smooth L1损失函数前面乘上真实分类标签值,这样做是为了去除负样本的定位损失,累加后除以2400(Nreg=2400, 2400个像素点),前面还要乘上权重lamda=10。这样分类损失和回归损失前面的系数大致是相等的1/256和1/2400。

注:fast r-cnn中的定位和分类损失都没有取均值。
如何保证回归框出来的值是相对真实标签框值的偏移而不是就是标签框的值呢?

下标是a的代表anchor,上标是的代表真实标签值,上下标都不带的是预测值。
所以预测值是(tx,ty,tw,th),标签值是(tx,ty*,tw*,th*),这样就能保证bb回归的是anchor回归到近乎真实的标签框。
在fast r-cnn和sppnet中是基于roi方法的检测框回归,就一个回归器供所有类别共享,因为他们通过roi(或空间金字塔池化)得到的是一个固定大小的feature,一个回归器就够了。在本文faster r-cnn中针对有很多尺度的anchor(9种),设计了9个回归器,这些回归器不共享参数各自独立。
3.1.3训练rpn网络
随机梯度下降法优化,每个图片中都包含很多根据与真实标签框的iou值大小确定的为正例或负例的anchor,不能对所有的为正例或负例的anchor都计算损失,因为这些anchor中负例占主导地位,所以采用随机采样256个anchor,这256个anchor中正例与负例的比例大概为1:1,如果正例数不足128个,就用负例来补充,使得总数为256个。
高斯分布初始化rpn的卷积层,偏差为0.01,卷积层都要在imagenet上做分类预训练,然后在目标训练集上微调,学习率最初060k为0.001,60k80k为0.0001,动量0.9,动量权重衰减0.0005。
3.2 rpn与fast r-cnn共享特征
rpn和fast r-cnn是训练的时候是独立的。
3中训练方法:
(1) 交替训练rpn和fast r-cnn,两个网络,这两个网络前面的卷积层结构是一样的(权重不一样。)
(2) 近似同时训练rpn和fast r-cnn,即把rpn的损失和Fast r-cnn的损失加到一块作为最终的损失。这种方法很容易实现,但是有个问题,rpn网络回归的预选框位置和bb回归的偏移值都应该作为fast r-cnn中的roi的输入,理论上有效的后向传播求解器也应考虑这个bb回归的偏移值,但是没有考虑,而是直接只给roi输入了预选框圈定的fm,所以求解的值是近似的。但是即使是近似值也能差不多达到考虑这个微分的效果,而且减少了25%~50%的训练时间。
(3) 完成准确地同时训练rpn和fast r-cnn。即在(2)中把忽略的rpn输出的bb回归的偏移值重新加上,重新设计一个roi(ROI warping)。这个问题很麻烦,不在本文考虑之内。

4步交替训练法:
(1) 训练rpn。用imageNet预训练好的model(以下简称model)初始化rpn网络,然后微调rpn网络。
(2) 训练fast r-cnn。用model初始化一个单独的fast r-cnn的卷积层部分,用(1)rpn网络生成的预选区训练这个Fast r-cnn网络。此时rpn网络和fast r-cnn网络并不共享参数,因为他们的cnn部分虽然结构一样,但是参数不一样。
(3) 再次训练rpn。把(2)中训练好的fast r-cnn的与rpn结构一样的cnn部分的权重拿过来初始化rpn网络中的这一部分,然后训练rpn,此时训练时只更新rpn网络中独有的部分,即全连接层+分类预测层和预选框回归器,而固定rpn网络中的cnn部分。
(4) 再次训练fast r-cnn。此时固定fast r-cnn中与rpn中一样(结构和权重都一样)的cnn部分,只更新fast r-cnn中独有的部分。
这样两个网络就可以共享卷积层(因为结构和权重都一样),组成了一个统一的网络。这样的4步训练可以迭代很多次,但是后面没什么用了,一次就够了。
3.3 实现细节
rpn和fast r-cnn这两个网络都用单尺度的输入图片训练了,对于输入图片缩放(高宽比不变)到短边是600像素值。
对于anchor,我们用3种大小(在原图上的scale,但是高宽比可能不一样)的框,1282,2562,5122,三种高宽比1:2,2:1:1,1:1。
![]()
我们注意到即使anchor在原图上的感知域不那么大,但是也可以回归出一个更大的框,这是因为可以通过目标中心部分大概估计这个目标的边界。(值得挖掘的一个创新点,即想办法让他实际的感知域不受限制anchor大小的限制)
对于映射到原图上已经跨越图像边界的anchor box,需要忽略,否则会造成训练无法收敛。对于一个1000600的图片大概有20000(6040*9)个anchors,忽略跨越边界的anchor box实际大约有6000个anchors。
rpn预测出的预选区有很多是重合度很高的,此时根据分类得分采用NMS,把nms的阈值设为0.7,最终留下大约2000个预选区,最后就用这2000个预选区训练fast r-cnn。
但是在评估时用更少的预选区来评估。
4 实验
4.1 在voc上的实验
共享cnn网络用了两种作对比,ZFnet的‘fast’版本(5个卷积层+3个全连接层)和VGG-16(13个卷积层+3个全连接层)。检测精度的评估标准是最后检测的map,而不是预选区的map。
上图红框中,主干cnn用的都是是ZFnet,分别对比三种预选区生成方法(selective search,edgeBox,rpn)的结过,推断时2rpn只需生成300个预选区就超越了ss,eb的效果,而且速度更快。
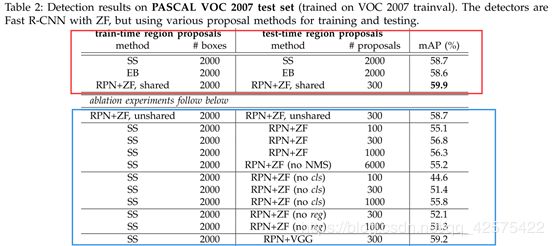
rpn上的消融实验:
如果fast r-cnn和rpn共享卷积层的参数,则mAP=59.9%,大于不共享参数map=58.7%(不共享即rpn的cnn部分和fast r-cnn的cnn部分用的是各自训练出来的权重)。
直接摆结论:
rpn生成的预选框NMS不损害最终的检测精度。
rpn网络即时不共享参数也比ss生成的预选区好。
检测时去掉rpn的bb回归,即直接用anchor box输入roi,mAP下降,显示出rpn网络的bb回归能生成更好的预选区,而直接用anchor box作为roi输入,不行。
VGG-16做主干网络比ZFnet做主干网络好。
rpn+vgg网络推断时间5fps,ss+vgg推断时间0.5fps.
每个像素点设置3*3=9种anchor,对mAP提升有3~4%。
rpn的定位损失前的系数lamda对mAP影响不大,可取范围很大。
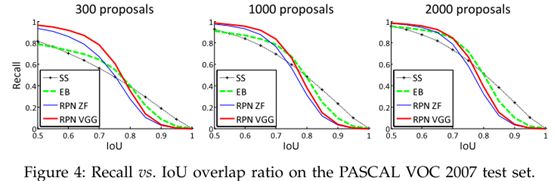
rpn生成的预选区数目为300和2000时的召回率变化不大,主要是由于根据分类得分用了nms的结果,因为nms后保留了得分高的预选区,所以基本需要召回的都召回了。
单步(overFeat)多步对比,单步还没多步慢,因为每个anchor都要处理。






4.2在coco上的实验
4.3 从coco到voc
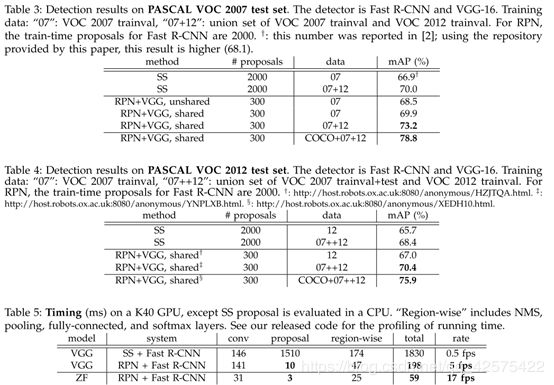
voc(20类)中的所有类别在coco(80类)中都有,所以可用coco上训练好的模型去检测voc2007数据集,mAP是76.1%,这个结果比只在voc07+12上训练的还好。
如果在coco上训练又在voc上微调,在voc 测试集的mAP结果是78.8%。
5 结论
提出了rpn用于生成比ss、edgebox质量更高的预选区,rpn的cnn部分与fast r-cnn共享参数,减少了计算量,提高了计算速度,组成一个统一的网络。主干网络用vgg-16,接近实时的检测速度(5fps)。