python爬虫task-1
一:HTML
1,基本格式:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html><!DOCTYPE html> 声明为 HTML5 文档
<html> 元素是 HTML 页面的根元素
<head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title> 元素描述了文档的标题
<body> 元素包含了可见的页面内容
<h1> 元素定义一个大标题
<div> 是一个块级元素。这意味着它的内容自动地开始一个新行。
上述代码的运行结果为:

可见所有内容都蜷缩在左上角,不是很美观。这个时候我们可以使用CSS来美化。

这时内容就居中显示了。
以上只是HTML的一些简单操作,具体可以到HTML教程了解。
二:爬虫的一般步骤:
1,发起请求
2,获取响应内容
3,解析内容
4,保存数据
爬取豆瓣TOP250
import urllib
import requests
from lxml import etree
import os
# 定义一个空列表用于保存十个页面的地址
url_list = []
def get_url():
# 十个页面的增加规律是每次加25
for i in range(0, 226, 25):
url_root = "https://movie.douban.com/top250?start=%d&filter=" % i
# 将形成的网页地址添加到列表中
url_list.append(url_root)
# 定义两个空列表,一个用于保存名称,另一个用于保存图片地址
title_list = []
image_url_list = []
def get_title(url, headers):
res = requests.get(url=url, headers=headers)
html = etree.HTML(res.text)
# 匹配名称所在的路径
title = html.xpath("//img/@alt")
for i in range(0, len(title) - 1):
# 将提取到的名称保存到名称列表
title_list.append(title[i])
def get_image_url(url, headers):
res = requests.get(url=url, headers=headers)
html = etree.HTML(res.text)
img_url = html.xpath("//img/@src")
for i in range(0, len(img_url) - 1):
image_url_list.append(img_url[i])
def main():
headers = {
"Host": "movie.douban.com",
"Referer": "https://movie.douban.com/top250?start=225&filter=",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
}
# 先获得十个页面的地址
get_url()
# 调用函数得到相应的列表
for url in url_list:
get_title(url, headers)
get_image_url(url, headers)
if os.path.exists("name_pic.txt") == True:
os.remove("name_pic.txt")
f = open("name_pic.txt", "a")
for word in zip(title_list, image_url_list):
f.write(str(word) + "\n")
f.close()
movie_path = "movie_img"
if movie_path not in os.listdir():
os.makedirs(movie_path)
for i in range(0, len(title_list)):
for j in range(0, len(image_url_list)):
if (i == j):
movie_name = title_list[j] + ".jpg"
filename = movie_path + "/" + movie_name
# 将图片下载到本地,并命名
print(movie_name)
urllib.request.urlretrieve(url=image_url_list[i], filename=filename)
if __name__ == '__main__':
main()
三:API
API(Application Programming Interface)即应用程序接口。可以理解成一个地方,那里有整理得非常好的、供人随意调用的资源。
具体说明见爬虫与API(上)
这篇文章将API在爬虫中的应用讲述的很明白。
以百度地图提供的API为例,实现地理编码功能。
import requests
def getUrl(*address):
ak = '' ## 填入你的api key
if len(address) < 1:
return None
else:
for add in address:
url = 'http://api.map.baidu.com/geocoding/v3/?address={0}&output=json&ak={1}'.format(add, ak)
yield url
def getPosition(url):
'''返回经纬度信息'''
res = requests.get(url)
# print(res.text)
json_data = eval(res.text)
if json_data['status'] == 0:
lat = json_data['result']['location']['lat'] # 纬度
lng = json_data['result']['location']['lng'] # 经度
else:
print("Error output!")
return json_data['status']
return lat, lng
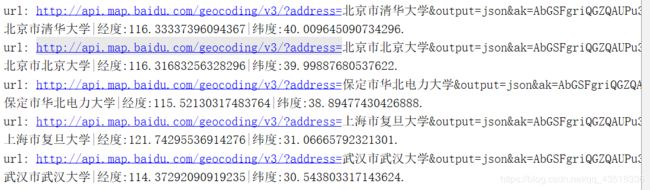
if __name__ == "__main__":
address = ['北京市清华大学', '北京市北京大学', '保定市华北电力大学', '上海市复旦大学', '武汉市武汉大学']
for add in address:
add_url = list(getUrl(add))[0]
print('url:', add_url)
try:
lat, lng = getPosition(add_url)
print("{0}|经度:{1}|纬度:{2}.".format(add, lng, lat))
except Exception as e:
print(e)结果为: