基于大数据的网站日志分析系统
本文没有任何代码,只有各个模块工作的大体机制和整体流程。算是一个科普文吧,我也对原理一知半解。
基于大数据的网站日志分析系统
- 1. 日志数据格式
- 1.1 访问日志
- 1.1.1 log_format
- 1.1.2 access_log
- 1.2 错误日志
- 2. 数据采集模块
- 2.1 Flume的运行机制
- 3. 数据存储模块
- 3.1 采集到HDFS
- 3.2 数据清洗
- 4. 数据分析模块
- 4.1 数据存入到Hive
- 4.2 使用HQL统计关键指标
- 4.3 使用Sqoop将数据导入数据库
- 5. 数据可视化模块
- 6. 总结
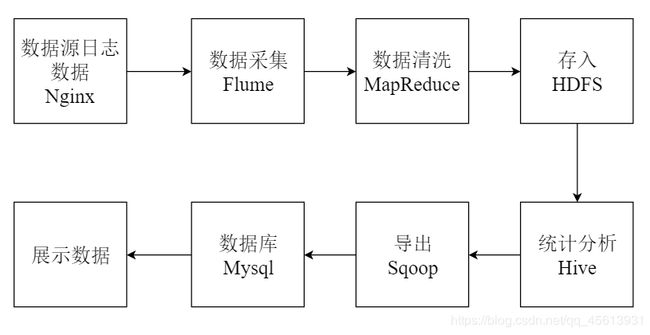
在本文中,基于大数据的网站日志分析系统的整个流程将大致分为五个部分进行介绍。第一部分介绍日志数据格式。第二部分介绍负责采集日志记录的数据采集模块。第三部分介绍负责存储日志同时对数据进行清理的数据存储模块。第四部分介绍负责解决日志数据的统计以及分析问题的数据分析模块。第五部分介绍负责将处理结果显示在界面上的数据可视化模块。
大致流程框图如下:

1. 日志数据格式
Nginx日志主要分为两种:访问日志和错误日志。日志开关可以在Nginx的配置文件中设置,两种日志都可以选择性关闭,默认都是打开的。
1.1 访问日志
访问日志主要记录客户端访问Nginx的每一个请求,格式可以自定义。通过访问日志就可以得到用户地域来源、跳转来源、使用终端、某个URL访问量等相关信息。
Nginx服务器日志相关指令主要有两条,一条是log_format,另外一条是access_log。一般在nginx的配置文件中日记配置。
1.1.1 log_format
log_format用来设置日志格式,也就是日志文件中每条日志的格式,具体如:log_format name(格式名称) type(格式样式)
想要记录更详细的信息需要自己设置log_format,具体可设置的参数格式及相关说明,如下:

1.1.2 access_log
access_log指令用来指定日志文件的存放路径(包含日志文件名)、格式和缓存大小。
需要注意的是:Nginx进程设置的用户和组必须对日志路径有创建文件的权限,否则会报错。
Nginx支持为每个location指定强大的日志记录。同样的连接可以在同一时间输出到不止一个的日志中。
1.2 错误日志
错误日志主要记录客户端访问Nginx出错时的日志,格式不支持自定义。通过错误日志,可以得到系统某个服务或server的性能瓶颈等。
2. 数据采集模块
Flume是一种分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据。它具有基于数据流的简单灵活的架构,具有可靠性机制和许多故障转移和恢复机制,具有强大的容错能力。它使用简单的可扩展数据模型,允许在线分析应用程序。它还是一个成熟的开源日志采集系统,且本身就是Hadoop生态体系中的一员,与Hadoop体系中的各种框架组件具有天生的亲和力,可扩展性强。因此,使用通用的Flume日志采集框架完全可以满足需求。
2.1 Flume的运行机制
Flume使用了一个简单灵活的架构:流数据模型。这是一个可靠、有容错的服务。
Flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,Flume在删除自己缓存的数据。Flume分布式系统中核心的角色是agent,agent本身是一个Java进程,一般运行在日志收集节点。
Flume采集系统就是由这么一个个agent所连接起来形成。
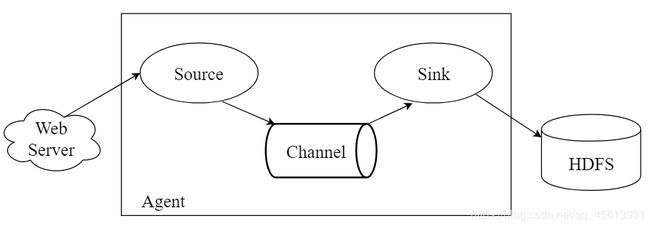
每个agent都必须具有三个元素,source、channel、sink。
source:采集源,用于跟数据源对接,以获取数据;
channel:agent内部的数据传输通道,用于从source将数据传递到sink;
sink: 下沉地,用于往下一级agent传递数据或者往最终存储系统传递数据;
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本单元。event将传输的数据进行封装。event从source,流向channel,再到sink,本身是一个字节数组,并可携带headers信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。一个完整的event包括:event headers、event body、event信息,其中event信息就是Flume收集到的日记记录。
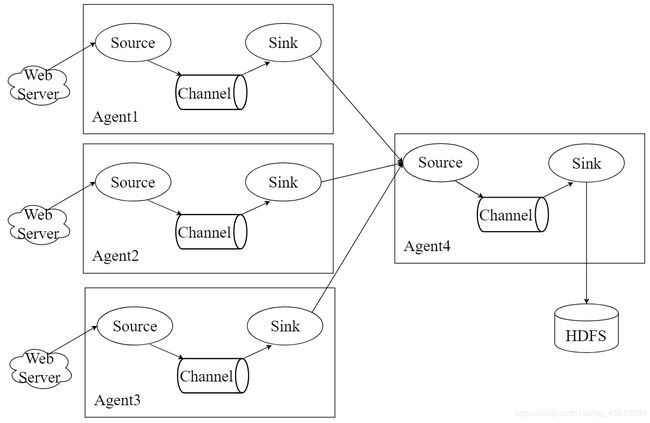
注:source可以指定为上一节点的sink,sink可以指定为下一节点的source。如下图:
3. 数据存储模块
理解了采集模块之后,就可以把日志数据信息想办法采集到一个可以用来存储的工具。这个工具就是Hadoop分布式文件系统:HDFS。HDFS是一个有高度容错性的系统,它能提供高吞吐量的数据访问,非常适合在大规模数据集上应用。
3.1 采集到HDFS
Nginx服务器所生成的流量日志,会存放在各台Nginx服务器上。由于Nginx没有自动分开文件存储日志的机制,不会自动地进行切割,都是写在一个文件 access.log当中的,所以如果访问量很大的话,将导致日志文件容量非常大,不便于管理。因此需要手动地对这个文件进行切割。
切割需要使用date命令以获得昨天的日期、使用kill命令向Nginx进程发送重新打开日志文件的信号,以及crontab设置执行任务周期。
Flume采集系统的搭建相对简单:
1、在服务器上部署agent节点,修改配置文件。
2、启动agent节点,将采集到的数据汇聚到指定的HDFS目录中。
针对上述的Nginx日志生成场景,它需要在Flume1.7版本上进行,因为在这个版本中,提供了一个非常好用的TaildirSource,使用这个source,可以监控一个目录,并且可以使用正则表达式匹配该目录中的文件名以便进行实时收集。
3.2 数据清洗
刚刚采集到HDFS中的原生数据,也称为不规整数据。因为从目前来看,该数据的格式还无法满足对数据处理的基本要求。这就需要通过MapReduce程序对采集到的这些日志数据信息进行预处理。通过数据预处理工作,就可以使残缺的数据变得完整,并将错误的数据纠正,将多余的数据去除,进而将所需的数据挑选出来。数据预处理的常见方法有数据清洗、数据集成与数据变换。

数据清洗的过程主要是编写MapReduce程序,而MapReduce程序的编写又分为写Mapper、Reducer、Job三个基本的过程。但是在网络日志分析系统中,要达到数据清洗的目的,只需要Mapper就可以达到要求了。因为Mapper负责的就是对数据进行处理,系统只需要预处理数据,其输出的数据并不需要进一步经过Redcuer来进行汇总处理。
4. 数据分析模块
经过数据预处理和采集存储部分,HDFS中已经存储了满足要求的日志数据信息,现在要做的就是对日志数据信息进行统计分析,选出系统所想要展示的信息。这里采用Hive+HDFS+Sqoop方案进行日志统计分析。
4.1 数据存入到Hive
要将数据存入到Hive里,那么Hive里得有存放数据表的位置,因此:
第一步,是在Hive里建立分区表,用来存储来自HDFS的数据。这里有两个注意:1、新建的表应该跟HDFS里面数据表一致,指定列名;2、创建表格式应一致。
第二步,将HDFS数据写入准备好的Hive表里。要写数据首先得知道数据存放的路径,记下数据存放路径,再将数据写入Hive。
经过以上操作之后,在Hive中就得到了我们做数据的分析统计所需要的比较规整的数据,下面就可以进行数据的统计分析。
4.2 使用HQL统计关键指标
实际上使用Hive,从导入到分析、排序、去重、结果输出等一系列操作都可以运用HQL语句来解决。HQL是Hibernate Query Language(Hibernate查询语言)的缩写,它提供更加丰富灵活、更为强大的查询能力。而且HQL更接近于SQL语句查询语法,但不是去对表和列进行操作,而是面向对象和它们的属性。 通过HQL,一条语句经过处理可以被解析成几个任务来运行,即使是关键词访问量增量,这种需要同时访问多天数据的较为复杂的需求也能通过表关联这样的语句自动完成,节省了大量工作量。
1、关键指标之一:PV量
页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1次。这里,我们只需要统计日志中的记录个数即可。省略HQL代码。
2、关键指标之二:注册用户数
假设某论坛的用户注册页面为member.php,当用户点击注册时请求的又是 member.php?mod=register的url。因此,这里我们只需要统计出日志中访问的URL是member.php?mod=register的即可。省略HQL代码。
3、关键指标之三:独立IP数
独立IP数记录的是:一天之内,访问网站的不同的独立IP个数之和。也就是说同一IP无论访问了多少个页面,独立IP数均只记为1。在HQL中我们可以利用DISTINCT关键字。省略HQL代码。
4、关键指标之四:跳出用户数
跳出用户数是指只浏览了一个页面便不再访问的用户的数量。这里可以通过用户的IP进行分组,如果分组后的记录数只有一条,那么这个就为跳出用户。将这些用户的数量相加,就得出了跳出用户数。省略HQL代码。
综上所述,Hive是一个可扩展性极强的数据仓库工具,借助于Hadoop分布式存储计算平台和Hive对SQL语句的理解能力,在Hive上要做的大部分工作就只是输入和输出数据的适配。恰恰这两部分IO格式是千变万化的,所以这就意味着需要定制符合要求的输入输出适配器。之后Hive将会透明化存储并处理这些数据,简化了很多繁琐的工作。
4.3 使用Sqoop将数据导入数据库
Sqoop是一款开源的工具,主要用于在Hive与传统的数据库mysql间进行数据的传递。它可以将一个关系型数据库中的数据导进到HDFS中,也可以将HDFS的数据导进到关系型数据库中。具体步骤如下:
(1)列出mysql数据库中的所有数据库命令:
(2)连接mysql并列出数据库中的表命令:
(3)将关系型数据的表结构复制到Hive中:
(4)从关系数据库导入文件到Hive中:
(5)将Hive中的表数据导入到mysql中:
5. 数据可视化模块
数据展现:将分析所得数据进行数据可视化,一般通过图表进行展示,以便运营决策人员能更方便地获取数据,更快更简单地理解数据。
比如可以如下这样设计:


6. 总结
大体上整个流程通过不断的学习,能够实现基于大数据技术的网站日志分析系统,能够解决现有的工具逐渐无法有效的处理海量数据的问题。在本文中提到的工具如下:设置日志数据格式的Nginx、可以采集、聚合、传输日志数据信息的Flume 、可以存储日志数据信息的Hadoop分布式文件系统HDFS、可以对日志数据信息进行清理的MapReduce、可以对日志数据信息存储、查询和分析的Hadoop数据仓库工具Hive、用于在Hive与传统数据库间进行数据传递的Sqoop。该系统应该能够实现基于大数据的网站日志分析系统。只要能够实现,企业网站的优化、维护信息安全以及网站的维护应该就有了比以前更好的保障。
模块间的大致联系总结如下: