知识图谱综述(初步了解后的总结整理)
文章目录
- 一、导读
- 二、知识图谱的概念演化
- 三、 什么是知识图谱
- 四、知识图谱的数据类型和存储方式
- 五、知识图谱的架构
- 六、知识图谱的构建技术
- 七、 知识图谱的应用
- 八、总结
注:首先声明,本篇博客是博主在查询知识图谱的资料的时候,看了数篇知识图谱综述以及阅读了相关资料后的一个总结以及自己的相关理解,仅是为了记录学习的过程。如果有侵权,请第一时间联系博主。博主是一位刚接触知识图谱的小白,初学乍练,希望可以每天进步一点点,同时希望得到众多志同道合的朋友们相互间的交流,和各位大神的指导。可以评论留下联系方式,共同进步。
一、导读
知识图谱的构建技术主要有自顶向下和自底向上两种。其中自顶向下构建是指借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。而自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。
在知识图谱技术发展初期,多数参与企业和科研机构主要采用自顶向下的方式构建基础知识库,如Freebase。随着自动知识抽取与加工技术的不断成熟,当前的知识图谱大多采用自底向上的方式构建,如Google的Knowledge Vault和微软的Satori知识库。
“The world is not made of strings , but is made of things.”
——辛格博士,from Google.
辛格尔博士对知识图谱的介绍很简短:things,not string。这抓住了知识图谱的核心,也点出了知识图谱加入之后搜索发生的变化,以前的搜索,都是将要搜索的内容看作字符串,结果是和字符串进行匹配,将匹配程度高的排在前面,后面按照匹配度依次显示。利用知识图谱之后,将搜索的内容不再看作字符串,而是看作客观世界的事物,也就是一个个的个体。 搜索比尔盖茨的时候,搜索引擎不是搜索“比尔盖茨”这个字符串,而是搜索比尔盖茨这个人,围绕比尔盖茨这个人,展示与他相关的人和事,左侧百科会把比尔盖茨的主要情况列举出来,右侧显示比尔盖茨的微软产品和与他类似的人,主要是一些IT行业的创始人。一个搜索结果页面就把和比尔盖茨的基本情况和他的主要关系都列出来了,搜索的人很容易找到自己感兴趣的结果。
知识图谱基础知识之一——人人都能理解的知识图谱
机器要想具有认知能力,也需要建立一个知识库,然后运用知识库来做一些事,这个知识库就是我们要说的知识图谱。从这个角度说, 知识图谱是人工智能的一个重要分支,也是机器具有认知能力的基石, 在人工智能领域具有非常重要的地位。
知识图谱的背景
计算智能——>感知智能——>认知智能
知识图谱与认知智能
http://www.360doc.com/content/18/0407/07/43535834_743447787.shtml
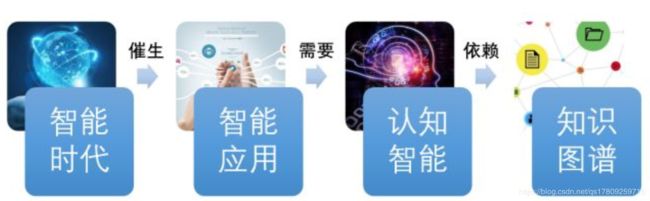
二、知识图谱的概念演化
知识图谱(Knowledge Graph, KG)的概念演化可以用下面这幅图来概括:
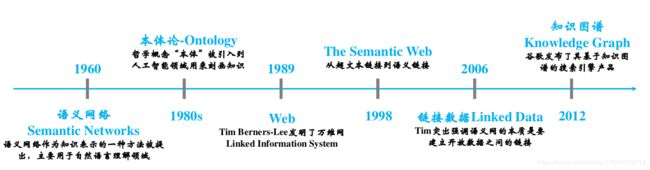
在1960年,语义网络(Semantic Networks)作为知识表示的一种方法被提出,主要用于自然语言理解领域。它是一种用图来表示知识的结构化方式。在一个语义网络中,信息被表达为一组结点,结点通过一组带标记的有向直线彼此相连,用于表示结点间的关系。如下图所示。简而言之,语义网络可以比较容易地让我们理解语义和语义关系。其表达形式简单直白,符合自然。然而,由于缺少标准,其比较难应用于实践。
1980s出现了本体论(Ontology),该本体是由哲学概念引入到人工智能领域的,用来刻画知识。
在1989年Time Berners-Lee发明了万维网,实现了文本间的链接。
1998年语义网(THe Semantic Web)被提出,它从超文本链接到语义链接。语义网是一个更官方的名称,也是该领域学者使用得最多的一个术语,同时,也用于指代其相关的技术标准。在万维网诞生之初,网络上的内容只是人类可读,而计算机无法理解和处理。比如,我们浏览一个网页,我们能够轻松理解网页上面的内容,而计算机只知道这是一个网页。网页里面有图片,有链接,但是计算机并不知道图片是关于什么的,也不清楚链接指向的页面和当前页面有何关系。语义网正是为了使得网络上的数据变得机器可读而提出的一个通用框架。“Semantic”就是用更丰富的方式来表达数据背后的含义,让机器能够理解数据。“Web”则是希望这些数据相互链接,组成一个庞大的信息网络,正如互联网中相互链接的网页,只不过基本单位变为粒度更小的数据,如下图。
2006年Tim突出强调语义网的本质是要建立开放数据之间的链接,即链接数据(LInked Data)。
2012年谷歌发布了其基于知识图谱的搜索引擎产品。可以看出,知识图谱的提出得益于Web的发展和数据层面的丰富,有着来源于知识表示(Knowledge Represention, KR)、自然语言处理(NLP)、Web、AI多个方面的基因。可用于搜索、问答、决策、AI推理等方面。
三、 什么是知识图谱
知识图谱(Knowledge graph)首先是由Google提出来的,大家知道Google是做搜索引擎的,知识图谱出现之前,我们使用google、百度进行搜索的时候,搜索的结果是一堆网页,我们会根据搜索结果的网页题目再点击链接,才能看到具体内容,2012年google提出Google Knowldge Graph之后,利用知识图谱技术改善了搜索引擎核心,表现出来的效果就是我们现在使用搜索引擎进行搜索的时候,搜索结果会以一定的组织结构呈现。
查找关于知识图谱的资料,可以找到不少的相关定义:
引用维基百科的定义:
The Knowledge Graph is a knowledge base used by Google and its
services to enhance its search engine’s results with information
gathered from a variety of sources.
译:知识图谱是谷歌及其提供的服务所使用的知识库,目的是通过从各种来源收集信息来增强其搜索结果的展示。
引用百度百科的定义:
知识图谱(Knowledge
Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
引用学术/学位论文的定义:
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。(刘峤,
李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.)
知识图谱就是展示知识发展过程与属性联系的一系列不同图形,再加以相应的可视化手段把这一系列图形表示的这些知识实体与知识实体或者知识实体与知识属性之间的联系展示出来。知识图谱的本质就是一种网状知识库,它是由一个个知识三元组组成。目前知识三元组的形式有两种,分别是<实体1,关系,实体2>和<实体1,属性1,属性值>。例如在本文所选的铁路领域内,这两种知识三元组分别可以是<中国铁路呼和浩特局集团公司,管辖,集宁机务段>,<东风
4B 型内燃机车,设计时速,120km/h>(客运型)和<东风 4B
型内燃机车,设计时速,100km/h>(货运型)。(学位论文:基于铁路领域的知识图谱研究与实现)
引用著作的定义:
知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。知识图谱由节点和边组成。节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、书名或是实体之间的关系,如朋友、配偶。知识图谱的早期理念来自Semantic
Web(语义网络),其最初理想是把基于文本链接的万维网落转化为基于实体链接的语义网络。(王昊奋,知识图谱 方法、实践与应用)
引用互联网博客的解释:
知识图谱:是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系。链接:通俗易懂解释知识图谱)(
知识图谱本质上是语义网络(Semantic Network)的知识库.。(链接:这是一份通俗易懂的知识图谱技术与应用指南)
知识图谱本质上是一种叫做语义网络(semantic network)的知识库,即具有有向图结构的一个知识库,其中图的结点代表实体(entity)或者概念(concept),而图的边代表实体/概念之间的各种语义关系,比如说两个实体之间的相似关系。
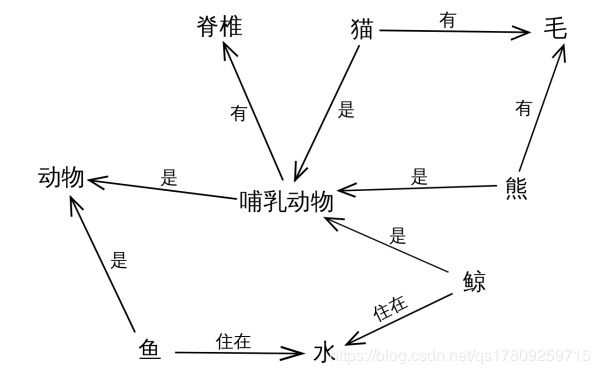
但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
如图所示,你可以看到,如果两个节点之间存在关系,他们就会被一条无向边连接在一起,那么这个节点,我们就称为实体(Entity),它们之间的这条边,我们就称为关系(Relationship)。
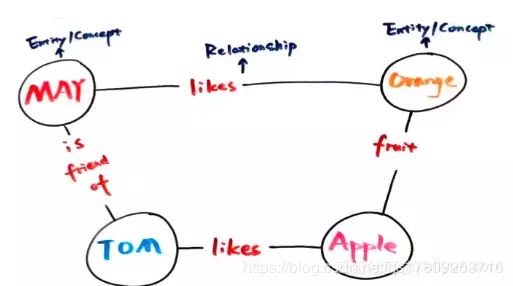
实体指的是现实世界中的事物比如人、地名、概念、药物、公司等, 关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
知识图谱的基本单位,便是“实体(Entity)-关系(Relationship)-实体(Entity)”构成的三元组(主语,谓词,宾语),这也是知识图谱的核心。
四、知识图谱的数据类型和存储方式
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
- 结构化数据(Structed Data),如关系数据库
- 非结构化数据,如图片、音频、视频
- 半结构化数据 如XML、JSON、百科
详细可以参考:
结构化数据和非结构化数据、半结构化数据的区别

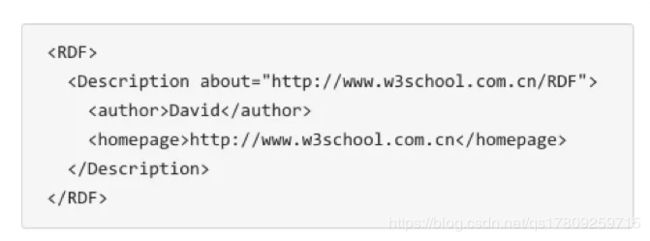
如何存储上面这三类数据类型呢?一般有两种选择,一个是通过**RDF(资源描述框架)**这样的规范存储格式来进行存储,比较常用的有Jena等。RDF的初步了解
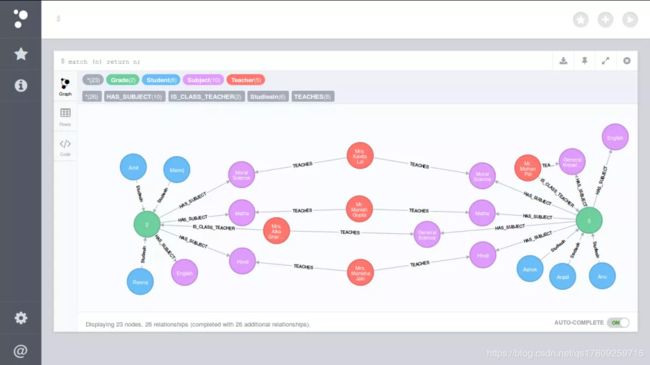
还有一种方法,就是使用图数据库来进行存储,常用的有Neo4j等。初识图数据与图数据库
那你可能会问我了,你不就是一大堆的三元组吗,用关系数据库来存储不也一样嘛。
是的,用关系数据库来存储,尤其是存储简单的知识图谱,从技术上来说是完全没问题的。
但需要注意的是,一旦知识图谱变复杂,图数据库在关联查询的效率上会比传统的关系数据存储方式有显著的提高。当我们涉及到2,3度的关联查询,基于知识图谱的查询效率会高出几千倍甚至几百万倍。
除此之外,基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。
因此如果你的数据量较大,还是建议直接用图数据库来进行存储的。
五、知识图谱的架构
1.知识图谱的架构主要可以被分为:
- 逻辑架构
- 技术架构
2.逻辑架构
在逻辑上,我们通常将知识图谱划分为两个层次:数据层和模式层。
- 模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识,通常通过本体库来管理这一层这一层(本体库可以理解为面向对象里的“类”这样一个概念,本体库就储存着知识图谱的类)。
- 数据层:存储真实的数据。
如果还是有点模糊,可以看看这个例子:
- 模式层:实体-关系-实体,实体-属性-性值
- 数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
3.技术架构
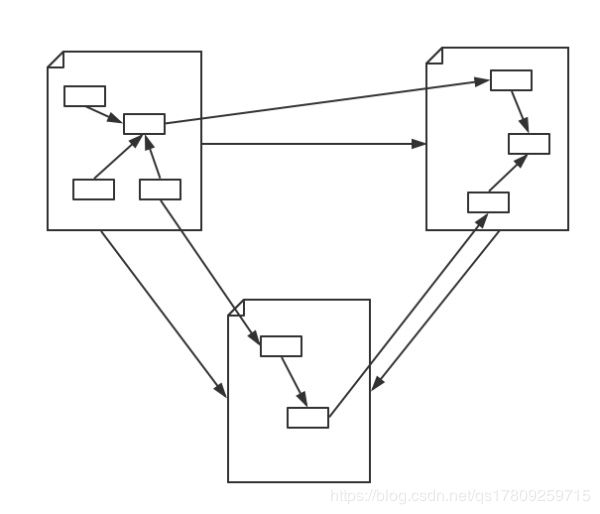
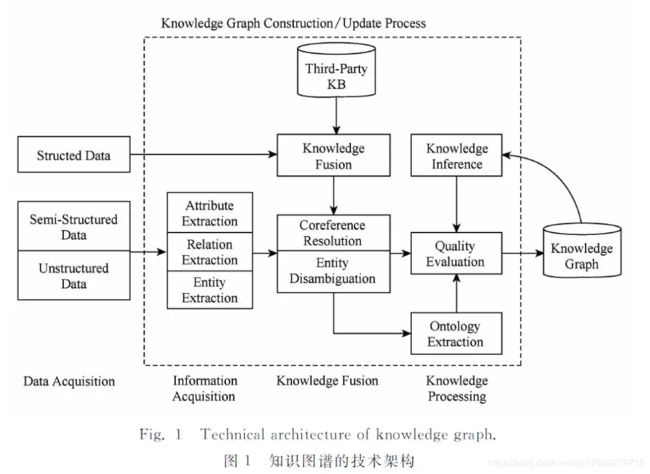
知识图谱的技术架构图
知识图谱的整体架构,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。
自底向上的构建方法流程如下图所示,从开放链接的数据源中提取实体、属性和关系,加入到知识图谱的数据层;然后将这些知识要素进行归纳组织,逐步往上抽象为概念,最后形成模式层。自顶而下的方法正好相反。
下面附一张中文版的
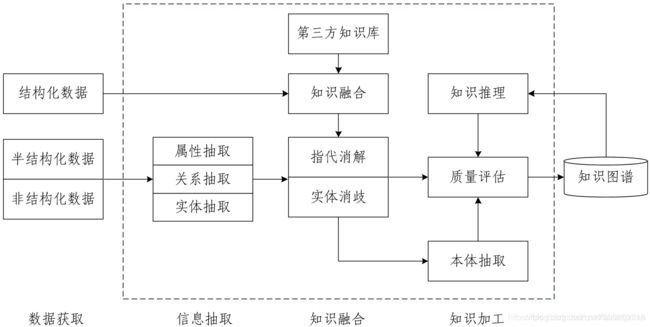
别紧张,让我们顺着这张图来理一下思路。首先我们有一大堆的数据,这些数据可能是结构化的、非结构化的以及半结构化的,然后我们基于这些数据来构建知识图谱,这一步主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。
构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
信息抽取: 从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
知识融合: 在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
知识加工: 对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
六、知识图谱的构建技术
网上很多资料都已经详细介绍,这里只是简单的介绍下知识图谱的构建技术,详细的可以参考下,以下推荐的两篇文章。
知识图谱构建技术一览
一文揭秘!自底向上构建知识图谱全过程
1.数据获取(Data Acquisition)
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
2.信息抽取(Information Extraction)
(1)实体抽取(Entity Extraction)/命名实体识别(Name Entity Recognition)
(2)关系抽取(Relation Extraction)
(3)属性抽取(Attribute Extraction)
3.知识融合(Knowledge Fusion)
(1)指代消解(Coreference Resolution)
(2)实体消歧(Entity Disambiguation)
(3)实体链接(Entity Linking)
(4)知识合并
4.知识加工(Knowledge Processing)
(1)本体(Ontology)
- 本体的概念
- 本体 VS 知识图谱 VS 知识地图
(2)本体构建(Ontology Extraction)
(3)知识推理(Knowledge Inference)
(4)质量评估(Quality Evaluation)
七、 知识图谱的应用
可以参考:
知识图谱的应用
八、总结
知识图谱是知识工程的一个分支,以知识工程中语义网络作为理论基础,并且结合了机器学习,自然语言处理和知识表示和推理的最新成果,在大数据的推动下受到了业界和学术界的广泛关注。知识图谱对于解决大数据中文本分析和图像理解问题发挥重要作用。目前,知识图谱研究已经取得了很多成果,形成了一些开放的知识图谱。但是,知识图谱的发展还存在以下障碍。首先,虽然大数据时代已经产生了海量的数据,但是数据发布缺乏规范,而且数据质量不高,从这些数据中挖掘高质量的知识需要处理数据噪音问题。其次,垂直领域的知识图谱构建缺乏自然语言处理方面的资源,特别是词典的匮乏使得垂直领域知识图谱构建代价很大。最后,知识图谱构建缺乏开源的工具,目前很多研究工作都不具备实用性,而且很少有工具发布。通用的知识图谱构建平台还很难实现。
参考:
[1] 刘峤,李杨,段宏,刘瑶,秦志光.知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600.
[2] 知识图谱的技术与应用
[3] 知识图谱初探
[4] 最全知识图谱介绍:关键技术、开放数据集、应用案例汇总
[5] 你不得不看的六篇知识图谱落地好文
[6] 知识图谱入门 (一)
[7] 知识图谱入门系列(重点)
[8] 突破!AI由“感知智能”成长为“认知智能”
最后附上,王昊奋老师的知识图谱课程的PPT,有需要的自取:
链接:https://pan.baidu.com/s/1dneC6PgNzegPCEeJj8Bu2g
提取码:n8sm
以及东南大学汪鹏老师的知识图谱课程的github地址https://github.com/npubird/KnowledgeGraphCourse