Attention在语音识别中的应用(1)
从2014年Attention mode在机器翻译或起来以后,attention model逐渐在语音识别领域中应用,并大放异彩。因此本篇文章就对Attention进行总结和说明。
首先要确定的是Attention是一种权重向量或矩阵,其往往用在Encoder-Decoder架构中,其权重越大,表示的context对输出越重要。计算方式有很多亚种,但是核心都是通过神经网络学习而得到对应的权重。通常其权重aij和Decoder中的第i-1个隐藏状态,Encoder中的第j个隐藏状态相关[1]。
接下来跟进一篇论文来具体了解Attention的用法和构成。第一篇文章是Jan Chorowski 的《Attention-Based Models for Speech Recognition 》[2].
Encoder端是一个BiRNN结构,第i步的输出Yi和hi和Attention的权重相关,具体架构如下图所示:
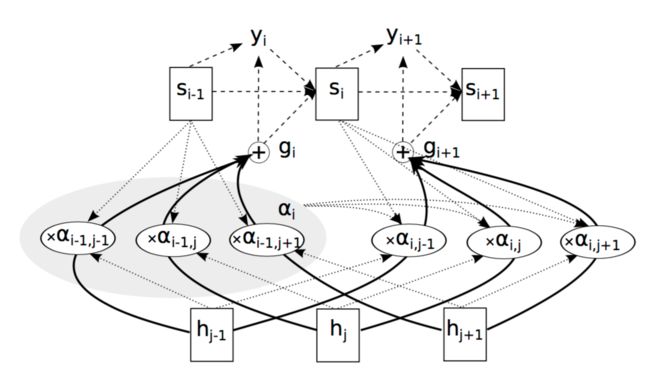
其输出Yi为:

其中,Generate为RNN的Decoder结构,Si-1表示Decoder中的第i-1个状态,gi表示glimpse,即Attention和隐藏层H相乘之后的结果,
glimpse为:

上式中,aij即为Attention的权重,hj为encoder中第j个隐藏状态。
si为Decoder中的因此状态,依赖si-1和gi和yi,如下所示:

以上为Attention的用法,解析来看一下Attention中aij是如何进行得到的。

aij是eij经过softmax的结果,eij计算如下(content-basedAttention ):

即Attention的权重aij是和Decoder中第i-1步骤的隐藏状态si-1相关,和Encoder中的第j步的隐藏状态hj相关;
eij还有第二种计算方式,就是把上一步骤中的ai-1加入到其中(location based Attention)


aij还有其他的实现方式:
sharpen方式:其中β>1

Smooth方式:

以上就介绍完了Attention的用法,下面来对Attention在近期的语音识别和机器翻译中的使用做一个说明。
2016年3月份Dzmitry Bahdanau 在文献[3]中把Attention模型用在了LVCSR中,Bandana在上面的基础之上,进行了改进,
1)对Attention的计算范围进行了2w的加窗,加快训练和解码
2)RNN结构为GRU,对RNN加入了pool,减少长度和计算量
3)加入n-gram,支持WFST解码
其Attention相关的结构如下:下图中的ct等价于上面介绍的glimpse,即gi

最终错误率对比如下所示:
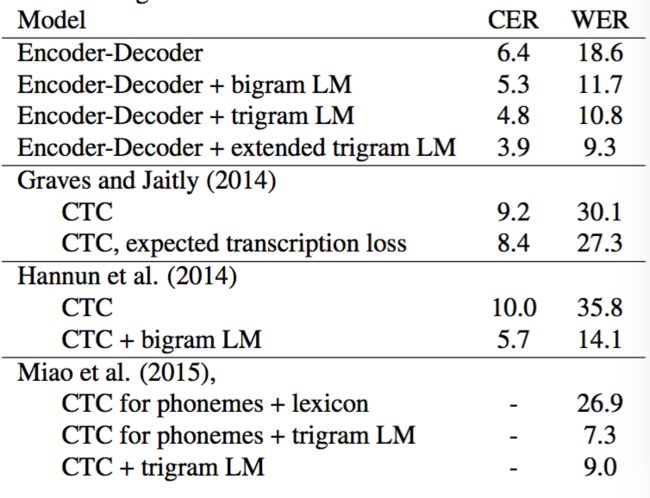
可以看到,其最好WER为9.3%,基本达到了苗亚杰2015年CTC+3-gram的水平。
然而Attention模型虽然好,但是还是有自身的问题[4][5],问题如下:
1)适合短语识别,对长句子识别比较差
2)noisy data的时候训练不稳定
因此比较好的方法是使得Attention与CTC进行结合,
Suyoun Kim等人在2016年9月的文章[5]就对Attention与CTC结合对语音声学模型建模,其结构如下所示:

其共用一个Encoder,Decoder分为2个,一个是CTC,一个是Attention,并通过权重λ来给定不同的权重比,
其损失函数如下:

在Encoder结构为4层BLSTM,每层320个节点,Decoder为单向LSTM,节点也为320个
λ为0.2,0.5,0.8的情况下,模型收敛情况如下所示:

对比蓝色的Attention模型还有红色的CTC模型,Attention+CTC模型更快的收敛了,这得益于初始阶段CTC的阶段对齐更准确,使得Attention模型训练收敛更快。
最终其CER如下所示:
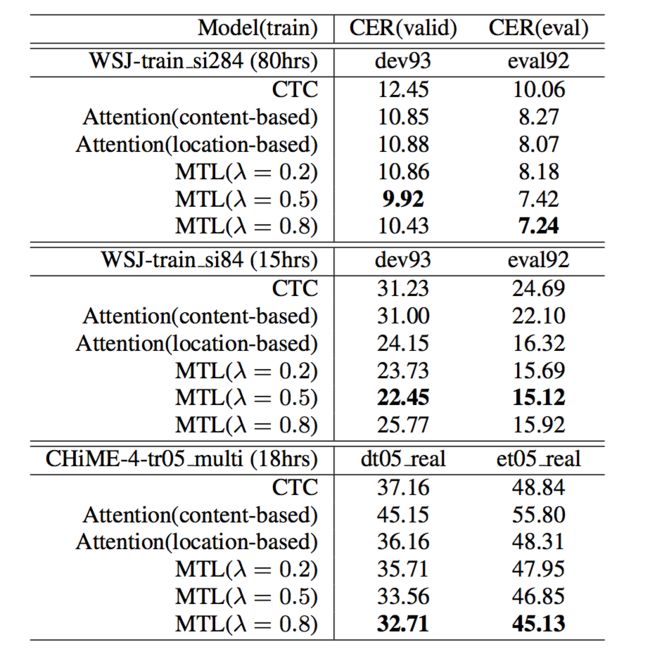
λ在0.5或者0.8的情况下,字正确率超过了单纯的Attention模型和CTC模型。
2017年7月,Facebook提出的Attention在CNN的机器翻译领域达到了state-of-art水平[6],其结构如下图所示:

与上面讨论不同的是,该Attention是多层的,每层都有对应一个Attention。是一个multiple steps结构。
Google在2017年6月针对MNT提出了纯Attention模型[7],文中提出了self-attention结构和Multi-head Attention结构。如下图所示:
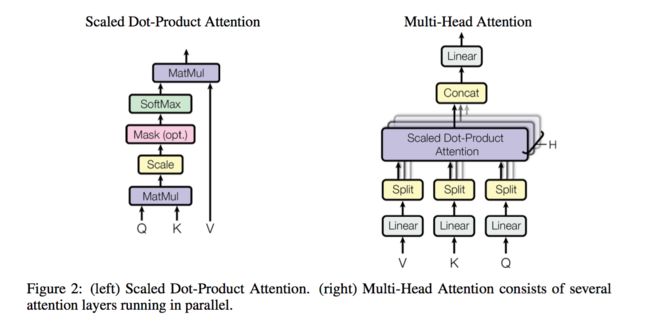
整体架构如下:

关于MNT的架构分析会在接下来的文章中进行讨论
Attention相关的更多文章可以看看NIPS workshop 2015相关的主题介绍 [8]
[1].https://zhuanlan.zhihu.com/p/28054589
[2] Attention-Based Models for Speech Recognition
[3] END-TO-END ATTENTION-BASED LARGE VOCABULARY SPEECH RECOGNITION
[4] GMIS 2017 | 腾讯AI Lab副主任俞栋:语音识别研究的四大前沿方向
[5] JOINT CTC-ATTENTION BASED END-TO-END SPEECH RECOGNITIONUSING MULTI-TASK LEARNING
[6]Convolutional Sequence to Sequence Learning
[7]Attention Is All You Need
[8]Reasoning, Attention, Memory (RAM) NIPS Workshop 2015