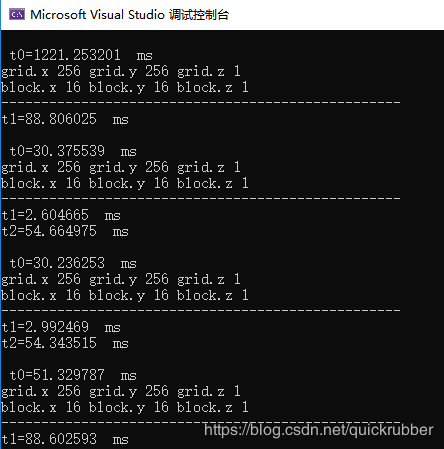
cudaMalloc和cudaMallocManaged的所用时间比较
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/imgproc/types_c.h"
#include
#include
#include
using namespace std;
#define N 4096 //512
#define K 16 //32 //64 //实际上64是不合理的超过32*32的blcok就会导致核函数失效。 //大矩阵的情况下,16的效果是最好的。
#pragma region 通用函数
//写文件
//1通道的Mat写成文本文件,uchar类型
int write_into_txt_file(string filename, float* input_arr)
{
ofstream ofs; //打开文件用于写,若文件不存在就创建它
locale loc = locale::global(locale("")); //要打开的文件路径含中文,设置全局locale为本地环境
ofs.open(filename, ios::out, _SH_DENYNO); //输出到文件 ,覆盖的方式,二进制。 可同时用其他的工具打开此文件
locale::global(loc); //恢复全局locale
if (!ofs.is_open())
return 0; //打开文件失败则结束运行
for (int i = 0; i < N; i++)
{
string dbgstr = "";
for (int j = 0; j < N; j++)
{
//uchar point = input_mat.at
dbgstr = dbgstr + " " + to_string(input_arr[N * i + j]);
}
dbgstr = dbgstr + "\n";
ofs.write(dbgstr.c_str(), dbgstr.size());
ofs.flush();
}
ofs.close();
return 1;
}
#pragma endregion
__global__ void printf_base()
{
printf("Hello \n");
}
void printf_base_test()
{
dim3 block(1);
dim3 grid(1);
printf_base << < grid, block >> > ();
}
__global__ void grid_block_Idx()
{
printf(" blockIdx.x=%d blockIdx.y=%d threadIdx.x=%d threadIdx.y=%d kernel print test \n", blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y);
}
void grid_block_Idx_test()
{
//针对block容量的测试
//dim3 block(32, 32);//经过测试发现,在本台机器block的上限,就是block(32,32),如果block(33.33),kernel函数中的内容就无法被调用(比如printf语句)
//dim3 block(16, 64);//block(16, 64)是可以的,但是block(16,65)就不可以,说明当前系统当前显卡,block当中的线程数量上限是16*64=32*32=1024个
//dim3 grid(1, 1);
//针对grid容量的测试
/*
dim3 block(1, 1);
dim3 grid(8192, 8192);//(64,64)是可以的,(128,128)也是可以的,(256,256)也是可以的,(1024,1024)也是可以的,(4096,4096)也是可以的
//(8192,8192)也是可以的,感觉grid中的block的数量是可以没有上限的
*/
//综合测试
dim3 block(2, 2);
dim3 grid(512, 512);
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
printf("-------------------------------------------------- \n");
grid_block_Idx << < grid, block >> > ();
}
#pragma region GPU转置(分成多个Block)
__global__ void transposeParallelPerElement(float in[], float out[],int threads_num)
{
int i = blockIdx.x * threads_num + threadIdx.x;
/* column */
int j = blockIdx.y * threads_num + threadIdx.y;
//printf("i=%d j=%d \n", i,j);
//printf(" blockIdx.x=%d blockIdx.y=%d threadIdx.x=%d threadIdx.y=%d kernel print test \n", blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y);
/* row */
out[j * N + i] = in[i * N + j];
//if((i*N+j)<100)
// printf("in[%d]=%f \n", i*N+j,in[i * N + j]);
}
void Gpu_Transfer_2()
{
int size = N * N * sizeof(float);
float* in, * out;
double t0 = (double)cv::getTickCount();
cudaMallocManaged(&in, size);
cudaMallocManaged(&out, size);
t0 = ((double)cv::getTickCount() - t0) * 1000 / cv::getTickFrequency();
printf("\n t0=%f ms\n", t0);
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
in[i * N + j] = i * N + j;
/*
dim3 block(32, 32); //Debug用时3.1ms release 2.6ms
dim3 grid(16, 16);
int threads_num = 32;
*/
/*
dim3 block(8, 8); //Debug用时2.79ms release 2.36ms
dim3 grid(64, 64);
int threads_num = 8;
*/
/*
dim3 block(4, 4); //release 2.29ms
dim3 grid(128, 128);
int threads_num = 4;
*/
/*
dim3 block(2, 2); //release 2.54ms
dim3 grid(256, 256);
int threads_num = 2;
*/
dim3 block(K, K); //release 2.54ms
dim3 grid(N/K, N/K);
int threads_num = K;
//write_into_txt_file("gpu_arr_in_1.txt", in);
double t1 = (double)cv::getTickCount();
transposeParallelPerElement << < grid, block >> > (in, out,threads_num);
cudaDeviceSynchronize();
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
printf("-------------------------------------------------- \n");
t1 = ((double)cv::getTickCount() - t1) * 1000 / cv::getTickFrequency();
printf("t1=%f ms\n", t1);
//write_into_txt_file("gpu_arr_out_2.txt", out);
cudaFree(in);
cudaFree(out);
}
void Gpu_Transfer_21()
{
int size = N * N * sizeof(float);
float* in, * out;
float* f_in, * f_out;
f_in = (float*)malloc(size);
f_out = (float*)malloc(size);
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
f_in[i * N + j] = i * N + j;
double t0 = (double)cv::getTickCount();
cudaMalloc((float**)&in, size);
cudaMalloc((float**)&out,size);
// transfer data from host to device
cudaMemcpy(in, f_in, size, cudaMemcpyHostToDevice);
t0 = ((double)cv::getTickCount() - t0) * 1000 / cv::getTickFrequency();
printf("\n t0=%f ms\n", t0);
dim3 block(K, K); //release 2.54ms
dim3 grid(N / K, N / K);
int threads_num = K;
//write_into_txt_file("gpu_arr_in_1.txt", in);
double t1 = (double)cv::getTickCount();
transposeParallelPerElement << < grid, block >> > (in, out, threads_num);
cudaDeviceSynchronize();
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
printf("-------------------------------------------------- \n");
t1 = ((double)cv::getTickCount() - t1) * 1000 / cv::getTickFrequency();
printf("t1=%f ms\n", t1);
double t2 = (double)cv::getTickCount();
cudaMemcpy(f_out, out, size, cudaMemcpyDeviceToHost);
t2 = ((double)cv::getTickCount() - t2) * 1000 / cv::getTickFrequency();
printf("t2=%f ms\n", t2);
//write_into_txt_file("gpu_arr_out_21.txt", f_out);
cudaFree(in);
cudaFree(out);
}
#pragma endregion
#pragma region GPU转置(Shared memory)
__global__ void transposeParallelPerElementTiled(float in[], float out[])
{
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K];
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y) * N];
__syncthreads();
out[(out_corner_i + x) + (out_corner_j + y) * N] = tile[x][y];
}
void Gpu_Transfer_3()
{
int size = N * N * sizeof(float);
float* in, * out;
double t0 = (double)cv::getTickCount();
cudaMallocManaged(&in, size);
cudaMallocManaged(&out, size);
t0 = ((double)cv::getTickCount() - t0) * 1000 / cv::getTickFrequency();
printf("\n t0=%f ms\n", t0);
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
in[i * N + j] = i * N + j;
//dim3 blocks(N / K, N / K);
//dim3 threads(K, K);
dim3 block(K, K);//(32,32)
dim3 grid(N / K, N / K);//(16,16)
double t1 = (double)cv::getTickCount();
transposeParallelPerElementTiled << < grid,block>> > (in, out);
cudaDeviceSynchronize();
//显然blocks 对应的是grid
//threads 对应的是block
//只是在一维的情况下,便这么写了。
//但是这样写很容易让人产生误会。
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
printf("-------------------------------------------------- \n");
t1 = ((double)cv::getTickCount() - t1) * 1000 / cv::getTickFrequency();
printf("t1=%f ms\n", t1);
//write_into_txt_file("gpu_arr_out_3.txt", out);
cudaFree(in);
cudaFree(out);
}
#pragma endregion
int main()
{
//printf_base_test();
//grid_block_Idx_test();
Gpu_Transfer_2();
Gpu_Transfer_21();
Gpu_Transfer_21();
Gpu_Transfer_3();
return 0;
}
//非常显然,采用cudaMalloc,并且用cudaMemcpy进行内存和GPU内存间的复制,比cudaMallocManaged,时间上要省的多。
运行结果如下图: