最简hadoop3.x完全分布式集群搭建
环境准备
- 三台 Linux centos 7机器,本例中使用 vmware 创建三台虚拟机作为替代
- 基于1,电脑需要安装好 vmware 软件,需要使用 secureCRT 登录Linux机器方便操作
- 准备好 jdk 8 和 hadoop-3.1.2 安装包
- 所有需要的安装包均为官网下载下来的 传送门 提取码 wgze
效果描述
最后的集群为一个三台机器的 hadoop 集群,其中数据结点(DataNode)和计算结点(NodeManager)分布在三台机器上,192.168.19.200既是数据结点和计算结点,又是集群管理结点所在机器,按照官方文档上写NameNode, ResourceManager 需分别部署在不同的机器上共同构成主节点,本例中将主节点复用在192.168.19.200机器上。 集群搭建完成后可以针对该集群做简单的 hdfs 操作与 mapreduce 操作,还能通过相关的web页面对 hadoop 集群进行管理。
最后机器的结点分布为
| 192.168.19.200 | 192.168.19.201 | 192.168.19.202 |
|---|---|---|
| NameNode SecondaryNameNode ResourceManager DataNode NodeManager |
DataNode NodeManager |
DataNode NodeManager |
结点网络拓扑图
准备三台虚拟机
创建虚拟机,并且将网络适配器选用 NAT模式,并且配置为静态 ip, 机器静态ip配置参考 静态ip设置 分别将三台机器的ip 设置为 [192.168.19.200,192.168.19.201,192.168.19.202]
安装 java 环境
由于 hadoop 框架的启动是依赖 java 环境,因此需要准备 jdk 环境,本例中使用的 jdk8 在 /mywork 目录下进行演示,使用 tar -zxvf jdk-8u201-linux-x64.tar.gz 解压jdk ,然后使用 mv jdk1.8.0_201 jdk8 将目录改名
//解压
tar -zxvf jdk-8u201-linux-x64.tar.gz
//重命名
mv jdk-8u201-linux-x64 jdk8

配置 jdk 环境变量
使用命令 vi /etc/profile 将如下代码添加到文件末尾,JAVA_HOME 变量设置为自己的目录
export JAVA_HOME=/mywork/jdk8
export CLASSPATH=.$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
配置好以后使用 source /etc/profile 重新加载配置文件,使用 java -version 测试jdk 配置是否成功
修改三台主机 hostname
本例中Linux操作系统为为 centos 7,使用自带的 hostnamectl 修改hostname
//192.168.19.200 上执行
hostnamectl set-hostname master
//192.168.19.201 上执行
hostnamectl set-hostname slave1
//192.168.19.202 上执行
hostnamectl set-hostname slave2
修改 host文件
使用 vi /etc/hosts 编辑该文件,在文件最后追加主机与ip的对应关系
192.168.19.200 master
192.168.19.201 slave1
192.168.19.202 slave2
最后重启机器,将这些配置生效
配置集群机器之间的免密登录
hadoop 集群是通过主节点的 rpc 调用来对整个集群进行统一的操作管理,如果不配置免密登录,在每次启动集群时需要输入每个从节点的机器密码,免密登录很好的解决此问题
- 分别在三台机器上生成 ssh 链接的私钥和公钥(一直回车,直到结束),在用户的家目录下生成一个隐藏文件 .ssh
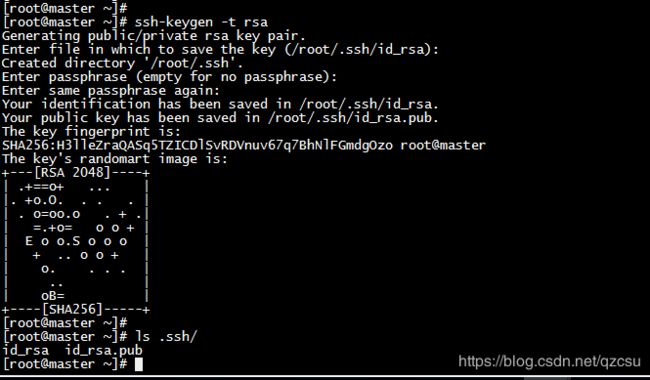
- 将本机的公钥拷贝到其余两台机器和本机,以 master 机器为例

- 将三台机器公钥都拷贝完成后,会在 ~/.ssh 文件下生成 authorized_keys,known_hosts 两个文件,存放的是一些免密登录的信息

关闭防火墙
关闭防火墙,并且设置开机不启动
systemctl stop firewalld.service
systemctl disable firewalld.service
安装 hadoop
- 使用命令 tar -zxvf hadoop-3.1.2.tar.gz 解压 hadoop 压缩包

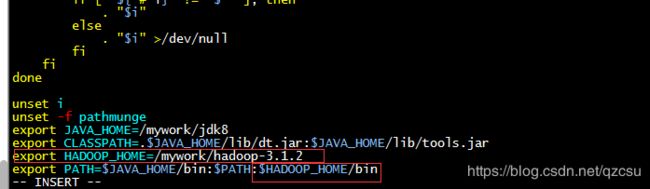
- 在三台机器上都配置 HADOOP_HOME ,vi /etc/profile 添加图中内容,保存后,使用 source /etc/profile 使配置文件生效
- 修改 hadoop 配置文件 hadoop 的配置文件位置如图所示,涉及修改的配置文件有 core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml,yarn-site.xml,workers。先修改 master 节点上的配置文件,然后通过远程复制到 slave1 与 slave2

- 在 core-site.xml 添加以下配置

- 在 hadoop-env.sh 最后添加以下配置

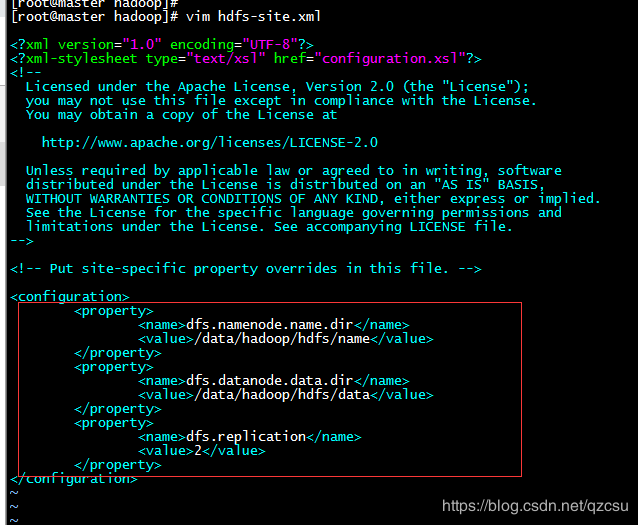
- 在 hdfs-site.xml 中添加以下配置
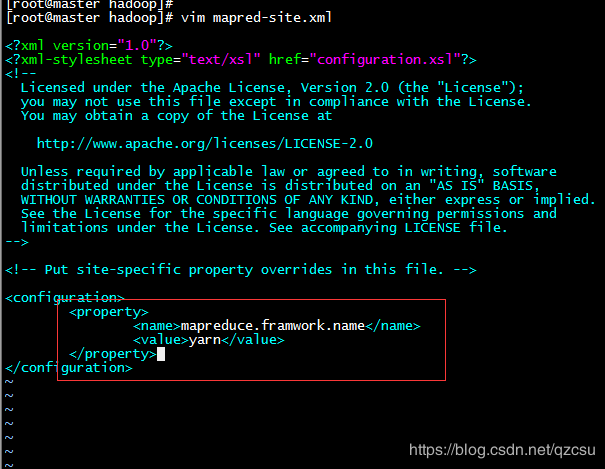
- 在 mapred-site.xml 中添加以下配置
- 在 workers 中修改为如下配置

- 在 yarn-site.xml 添加如下配置

- 将 hadoop 目录从 master 拷贝到 slave1 与 slave2,由于之前配置了免密登录,所以不需要输入密码即可完成拷贝
scp -qr /mywork/hadoop-3.1.2 slave1:/mywork
scp -qr /mywork/hadoop-3.1.2 slave2:/mywork
- 创建临时文件目录 (三台机器都需创建), 创建的目录对应于 第六步 hdfs-site.xml 中配置的目录
mkdir -p /data/hadoop/hdfs/data
mkdir -p /data/hadoop/hdfs/name
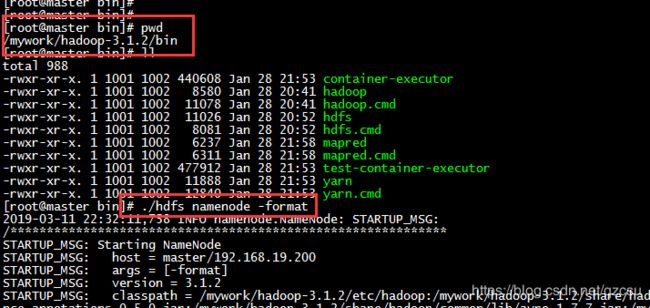
- 格式化 hdfs 文件系统,在master结点上的hadoop的安装目录下的 bin 目录下执行以下命令
./hdfs namenode -format
13. 启动 hdfs
启动hdfs后 master 进程状态

启动hdfs后 slave1 进程状态

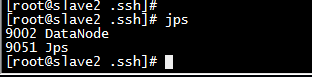
启动hdfs后 slave2 进程状态
14. 启动 yarn
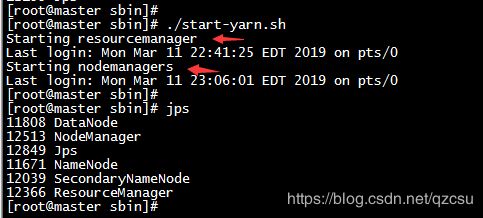
启动yarn后 master 结点进程状态
启动yarn后 slave1结点进程状态

启动yarn后 slave2结点进程状态

测试集群是否搭建成功
web 页面测试
以下几个web页面是否可以正常打开(注意关闭防火墙)
http://192.168.19.200:8088/cluster hadoop 集群信息
http://192.168.19.200:9870/dfshealth.html#tab-overview hdfs 地址
http://192.168.19.200:9864/datanode.html dataNode 地址
http://192.168.19.200:8042/node nodeManager 地址
http://192.168.19.200:9868/status.html secondaryNameNode
hdfs 功能测试
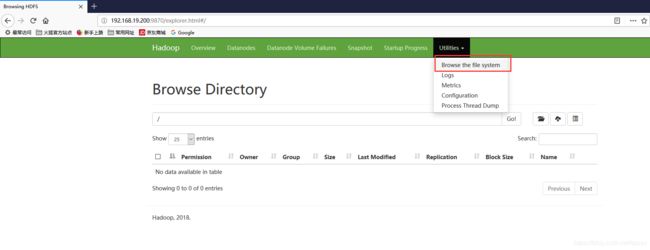
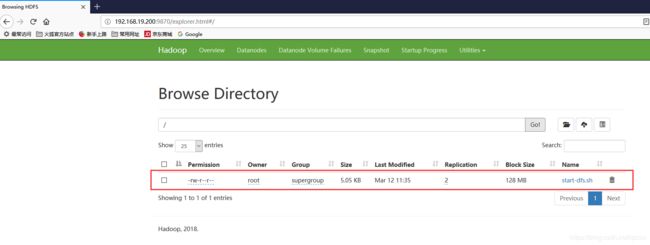
- 提前打开web界面查看 hdfs 文件系统,目前根目录下没有任何文件
- 使用命令 hdfs dfs -put start-dfs.sh / 将本地的 start-dfs.sh 文件上传到 hdfs 文件系统的根目录下

- 重新打开web界面查看 hdfs 文件系统文件是否上传成功
mapreduce 功能测试
- /mywork 目录下创建一个文件 wordtest 文件内容如下,下面我们用自带的库函数 统计各个单词出现的次数
Good morning, everyone. Thank you for taking your time. It’s really my honor to have this opportunity to take part in this interview. Now, I would like to introduce myself briefly.

2. 将该文件上传到 hdfs 文件系统上(因为 mapreduce 功能是在 hdfs 基础之上)【使用的是另一种 hdfs 上传文件的命令】
hadoop fs -put wordtest /wordtest

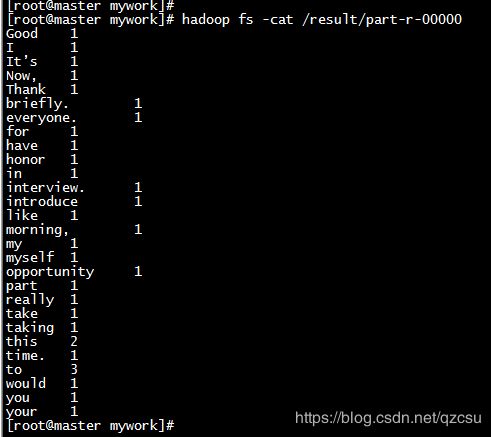
3. 执行 mapreduce 后生成结果文件
hadoop jar /mywork/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /wordtest /result

4. 查看统计结果
小结
本文利用本地本地虚拟机搭建一个三节点最简hadoop-3.x 集群的demo, 在master主节点上同时也作为计算结点使用,最后验证了hdfs和mapreduce功能能正常使用。