CBOW v.s. skip-gram
-
CBOW
上下文预测中心词,出现次数少的词会被平滑,对出现频繁的词有更高的准确率
-
skip-gram
中心词预测上下文,训练次数比CBOW多,表示罕见词更好
例如给定上下文 yesterday was a really [...] day ,CBOW可能会输出 beautiful 或 nice ,但是 delightful 的概率就很低;而skip-gram 是给定 delightful ,模型必须理解它的含义并输出可能的上下文是 yesterday was a really [...] day。[1]
In the "skip-gram" mode alternative to "CBOW", rather than averaging the context words, each is used as a pairwise training example. That is, in place of one CBOW example such as [predict 'ate' from average('The', 'cat', 'the', 'mouse')], the network is presented with four skip-gram examples [predict 'ate' from 'The'], [predict 'ate' from 'cat'], [predict 'ate' from 'the'], [predict 'ate' from 'mouse']. (The same random window-reduction occurs, so half the time that would just be two examples, of the nearest words.)
CBOW 在预测中心词时,用GradientDesent方法,不断的去调整权重(周围词的向量),cbow的对周围词的调整是统一的:求出的gradient的值会同样的作用到每个周围词的词向量当中去。时间复杂度为 \(O(V)\)
skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量。skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次。时间复杂度为 \(O(KV)\)[2]
skip-gram
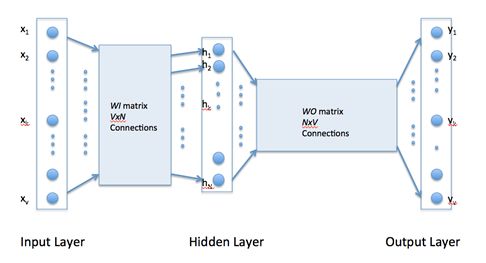
输入层:中心词的one-hot编码,维度等于词典大小
隐藏层:大小等于词向量维度
输出层:与输入层维度相等,输出词的概率
假如有下列句子:
“the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree”
有8个词,假设隐层有三个神经元,则 $ W_I$ 和 \(W_O\) 分别为 8×3 和 3×8 的矩阵,开始训练前进行初始化
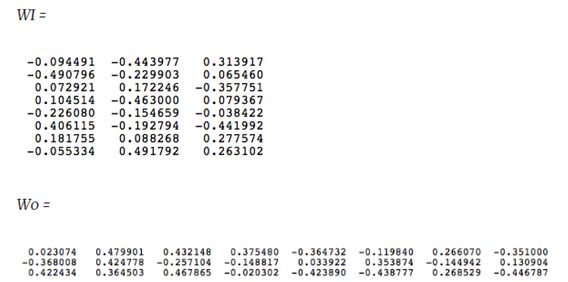
假设输入为“cat”,one-hot编码为[0 1 0 0 0 0 0 0],隐藏层为
对应 \(W_I\) 的第二行(‘cat'的编码表示),就是查表。
实际训练使用了负采样。
霍夫曼树
把 N 分类问题变成 log(N)次二分类
Word2vec v.s. GloVe
predictive 目标是不断提高对其他词的预测能力,减小预测损失,从而得到词向量。
count-based 对共现矩阵降维,得到词向量

[1] https://stackoverflow.com/questions/38287772/cbow-v-s-skip-gram-why-invert-context-and-target-words
[2] https://zhuanlan.zhihu.com/p/37477611