推荐——协同过滤算法以及Python实现
协同过滤算法(collaborative filtering)的目标是基于用户对物品的历史评价信息,向**目标用户(active user)**推荐其未购买的物品。协同过滤算法可分为基于物品的,基于用户的和基于矩阵分解,本文实现基于物品和基于矩阵分解的协同过滤算法。
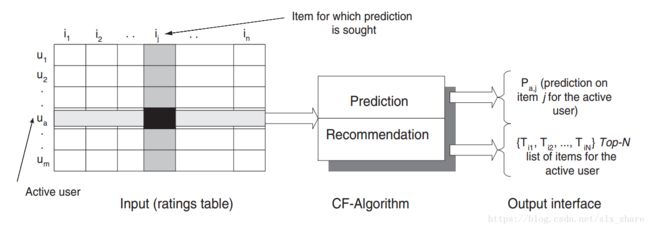
协同过滤算法总览
输入数据:典型的协同过滤问题输入数据为m个用户list,n个物品list,同时每个用户有一个已评价的物品list。
推荐过程:
- 计算similarity(用户间或物品间相似度):通常采用pearson相关系数或余弦相似度。
- 计算prediction(目标用户未购买物品对目标用户的吸引力):目标用户对未购买商品的预测评分。
- 计算recommendation:向目标用户推荐前K个吸引力最大的物品。
基于用户的协同过滤算法
基于用户的协同过滤算法旨在寻找相似的用户,然后在相似的用户间推荐物品。
- similarity:计算用户间的相似度。上文说到每个用户都有一个已评价的物品list,那么该list就是用户的一个属性向量,用户的相似度就是该向量间的相似度。
- prediction:假设用户A和B、C是相似用户。假设Item1, Item2, Item3三个物品是B、C购买过但A未购买过的物品。那么我们就可以向A推荐 这些物品。如何计算这三个物品对用户A的吸引力呢?以B、C和A的相似度为权重,计算B、C对物品的评分均值即可。
基于用户的协同过滤算法实际上面临很大的问题,例如稀疏性问题,毕竟一个用户购买的物品是非常少的。
基于物品的协同过滤算法
基于物品的协同过滤算法旨在寻找相似的物品,然后向目标用户推荐其已购买的物品的相似物品。
- similarity: 提取所有用户对Item1, Item2, Item3,Item4四个物品的评分,每个物品对应一条评分向量,向量间的相似度就是物品间的相似度。(注意计算向量间相似度时,必须元素对应,即某个用户必须同时对两个物品进行了评分)
- prediction: 假设目标用户购买了Item1, Item2,未购买Item3和Item4。那么Item3对目标用户的吸引力如何计算呢?以Item1和Item2与Item3的相似度为权重,用户对Item1和Item2的评分均值即为目标用户对Item3的吸引力。

其中, s i , N s_{i,N} si,N为相似度, R u , N R_{u,N} Ru,N为评分,分母为相似度第一范数。
基于矩阵分解的协同过滤算法
矩阵分解的目的就是提取矩阵中有用的信息,消除噪声,压缩信息,降低计算量。例如矩阵的奇异值分解,大部分信息集中在前k个奇异值上。将矩阵应用于推荐算法的基本思想同样是构建用户与物品的向量,然后计算用户与物品的相似度。显然,用户矩阵乘以物品矩阵应当尽可能接近用户评分矩阵。详细步骤如下:
- 对用户评分矩阵R进行奇异值分解,得到 R = U S V R=USV R=USV,
- 将 S S S简化成k维 S k S_k Sk,同时简化U和V为 U k , V k U_k, V_k Uk,Vk
- 计算 S k − 1 2 S_k^{-\frac{1}{2}} Sk−21
- 计算用户和物品的隐因子矩阵: U k S k − 1 2 , S k − 1 2 V k U_kS_k^{-\frac{1}{2}}, S_k^{-\frac{1}{2}}V_k UkSk−21,Sk−21Vk
- 用户i对未购买物品j的预测评分为 P i j = R ˉ + U k S k − 1 2 ( i ) S k − 1 2 V k ( j ) P_{ij}=\bar{R} +U_kS_k^{-\frac{1}{2}}(i)S_k^{-\frac{1}{2}}V_k(j) Pij=Rˉ+UkSk−21(i)Sk−21Vk(j) ,其中 R ˉ \bar{R} Rˉ为用户对已购买物品评分的均值
代码
"""
协同过滤算法
"""
from abc import ABCMeta, abstractmethod
import numpy as np
from collections import defaultdict
class CF_base(metaclass=ABCMeta):
def __init__(self, k=3):
self.k = k
self.n_user = None
self.n_item = None
@abstractmethod
def init_param(self, data):
pass
@abstractmethod
def cal_prediction(self, *args):
pass
@abstractmethod
def cal_recommendation(self, user_id, data):
pass
def fit(self, data):
# 计算所有用户的推荐物品
self.init_param(data)
all_users = []
for i in range(self.n_user):
all_users.append(self.cal_recommendation(i, data))
return all_users
class CF_knearest(CF_base):
"""
基于物品的K近邻协同过滤推荐算法
"""
def __init__(self, k, criterion='cosine'):
super(CF_knearest, self).__init__(k)
self.criterion = criterion
self.simi_mat = None
return
def init_param(self, data):
# 初始化参数
self.n_user = data.shape[0]
self.n_item = data.shape[1]
self.simi_mat = self.cal_simi_mat(data)
return
def cal_similarity(self, i, j, data):
# 计算物品i和物品j的相似度
items = data[:, [i, j]]
del_inds = np.where(items == 0)[0]
items = np.delete(items, del_inds, axis=0)
if items.size == 0:
similarity = 0
else:
v1 = items[:, 0]
v2 = items[:, 1]
if self.criterion == 'cosine':
if np.std(v1) > 1e-3: # 方差过大,表明用户间评价尺度差别大需要进行调整
v1 = v1 - v1.mean()
if np.std(v2) > 1e-3:
v2 = v2 - v2.mean()
similarity = (v1 @ v2) / np.linalg.norm(v1, 2) / np.linalg.norm(v2, 2)
elif self.criterion == 'pearson':
similarity = np.corrcoef(v1, v2)[0, 1]
else:
raise ValueError('the method is not supported now')
return similarity
def cal_simi_mat(self, data):
# 计算物品间的相似度矩阵
simi_mat = np.ones((self.n_item, self.n_item))
for i in range(self.n_item):
for j in range(i + 1, self.n_item):
simi_mat[i, j] = self.cal_similarity(i, j, data)
simi_mat[j, i] = simi_mat[i, j]
return simi_mat
def cal_prediction(self, user_row, item_ind):
# 计算预推荐物品i对目标活跃用户u的吸引力
purchase_item_inds = np.where(user_row > 0)[0]
rates = user_row[purchase_item_inds]
simi = self.simi_mat[item_ind][purchase_item_inds]
return np.sum(rates * simi) / np.linalg.norm(simi, 1)
def cal_recommendation(self, user_ind, data):
# 计算目标用户的最具吸引力的k个物品list
item_prediction = defaultdict(float)
user_row = data[user_ind]
un_purchase_item_inds = np.where(user_row == 0)[0]
for item_ind in un_purchase_item_inds:
item_prediction[item_ind] = self.cal_prediction(user_row, item_ind)
res = sorted(item_prediction, key=item_prediction.get, reverse=True)
return res[:self.k]
class CF_svd(CF_base):
"""
基于矩阵分解的协同过滤算法
"""
def __init__(self, k=3, r=3):
super(CF_svd, self).__init__(k)
self.r = r # 选取前k个奇异值
self.uk = None # 用户的隐因子向量
self.vk = None # 物品的隐因子向量
return
def init_param(self, data):
# 初始化,预处理
self.n_user = data.shape[0]
self.n_item = data.shape[1]
self.svd_simplify(data)
return data
def svd_simplify(self, data):
# 奇异值分解以及简化
u, s, v = np.linalg.svd(data)
u, s, v = u[:, :self.r], s[:self.r], v[:self.r, :] # 简化
sk = np.diag(np.sqrt(s)) # r*r
self.uk = u @ sk # m*r
self.vk = sk @ v # r*n
return
def cal_prediction(self, user_ind, item_ind, user_row):
rate_ave = np.mean(user_row) # 用户已购物品的评价的平均值(未评价的评分为0)
return rate_ave + self.uk[user_ind] @ self.vk[:, item_ind] # 两个隐因子向量的内积加上平均值就是最终的预测分值
def cal_recommendation(self, user_ind, data):
# 计算目标用户的最具吸引力的k个物品list
item_prediction = defaultdict(float)
user_row = data[user_ind]
un_purchase_item_inds = np.where(user_row == 0)[0]
for item_ind in un_purchase_item_inds:
item_prediction[item_ind] = self.cal_prediction(user_ind, item_ind, user_row)
res = sorted(item_prediction, key=item_prediction.get, reverse=True)
return res[:self.k]
if __name__ == '__main__':
# data = np.array([[4, 3, 0, 5, 0],
# [4, 0, 4, 4, 0],
# [4, 0, 5, 0, 3],
# [2, 3, 0, 1, 0],
# [0, 4, 2, 0, 5]])
data = np.array([[3.5, 1.0, 0.0, 0.0, 0.0, 0.0],
[2.5, 3.5, 3.0, 3.5, 2.5, 3.0],
[3.0, 3.5, 1.5, 5.0, 3.0, 3.5],
[2.5, 3.5, 0.0, 3.5, 4.0, 0.0],
[3.5, 2.0, 4.5, 0.0, 3.5, 2.0],
[3.0, 4.0, 2.0, 3.0, 3.0, 2.0],
[4.5, 1.5, 3.0, 5.0, 3.5, 0.0]])
# cf = CF_svd(k=1, r=3)
cf = CF_knearest(k=1)
print(cf.fit(data))
参考:https://blog.csdn.net/yimingsilence/article/details/54934302
http://wwwconference.org/proceedings/www10/papers/pdf/p519.pdf
我的GitHub
注:如有不当之处,请指正。