Python面试题(第二篇)
第二部分 网络编程和并发(34题)
- 1、简述 OSI 七层协议。
- 2、什么是C/S和B/S架构?
- 3、简述 三次握手、四次挥手的流程。
- 4、什么是arp协议?
- 5、TCP和UDP的区别?
- 6、什么是局域网和广域网?
- 7、为何基于tcp协议的通信比基于udp协议的通信更可靠?
- 8、什么是socket?简述基于tcp协议的套接字通信流程。
- 9、什么是粘包?socket 中造成粘包的原因是什么?哪些情况会发生粘包现象?
- 10、IO多路复用的作用?
- 11、什么是防火墙以及作用?
- 12、select、poll、epoll 模型的区别?
- 13、简述 进程、线程、协程的区别 以及应用场景?
- 14、GIL锁是什么鬼?
- 15、Python中如何使用线程池和进程池?
- 16、threading.local的作用?
- 17、进程之间如何进行通信?
- 18、什么是并发和并行?
- 19、进程锁和线程锁的作用?
- 20、解释什么是异步非阻塞?
- 21、路由器和交换机的区别?
- 22、什么是域名解析?
- 23、如何修改本地hosts文件?
- 24、生产者消费者模型应用场景及优势?
- 25、什么是CDN?有什么用?
- 26、LVS是什么及作用?
- 27、Nginx是什么及作用?
- 28、keepalived是什么及作用?
- 29、haproxy是什么以及作用?
- 30、什么是负载均衡?
- 31、什么是rpc及应用场景?
- 32、简述 asynio模块的作用和应用场景。
- 33、简述 gevent模块的作用和应用场景。
- 34、twisted框架的使用和应用?
1、简述 OSI 七层协议。
-
概念
s
Open System Interconnection : 开放互联系统 -
图示

注:图片来源:https://www.cnblogs.com/maybe2030/p/4781555.html#_label1,作者:Poll的笔记
3.粗浅理解
物理层:主要设备,中继器、集线器,传输单位是比特(比特流),保证比特数据远距离传输不会衰减,都能对数据进行再生和重定时。
数据链路层:主要设备,网卡,网桥,交换机,传输单位是帧,以太网协议为基础进行传输。帧就是对字节的封装,字节(byte)是由位(bit)组成的。
网络层:主要设备,路由器,传输单位是报文(包),以IP协议为基础进行传输,提供逻辑地址IP,选路,数据从源端到目的端的传输。
传输层:主要设备,网管,传输单位是数据段(段),以TCP/UDP协议为主,实现网络不同主机上用户进程之间的数据通信,可靠与不可靠的传输,传输层的错误检验,流量控制等。
会话层:传输单位是:数据,会话层管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。会话层还利用在数据中插入校验点来实现数据的同步。如服务器验证用户登录便是会话层完成额。
表示层:传输单位是:数据,表示层对上层数据或信息进行变换以保证一个主机应用层信息可以被另一个主机的应用程序理解。表示层的数据转换包括数据的加密、压缩、格式转换等。
应用层:传输单位是:数据,为操作系统或网络应用程序提供访问网络服务的接口。确定进程之间的性质以满足用户需求以及提供网络与用户的应用。
2、什么是C/S和B/S架构?
一、什么是C/S架构
C/S架构是第一种比较早的软件架构,主要用于局域网内。也叫 客户机/服务器模式。
它可以分为客户机和服务器两层:
第一层: 在客户机系统上结合了界面显示与业务逻辑;
第二层: 通过网络结合了数据库服务器。
简单的说就是第一层是用户表示层,第二层是数据库层。
这里需要补充的是,客户端不仅仅是一些简单的操作,它也是会处理一些运算,业务逻辑的处理等。也就是说,客户端也做着一些本该由服务器来做的一些事情,如图所示:
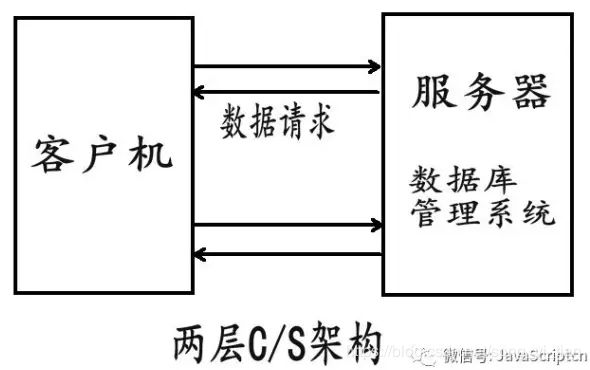
C/S架构软件有一个特点,就是如果用户要使用的话,需要下载一个客户端,安装后就可以使用。比如QQ,OFFICE软件等。
1、C/S架构的优点:
1 C/S架构的界面和操作可以很丰富。(客户端操作界面可以随意排列,满足客户的需要)
2 安全性能可以很容易保证。(因为只有两层的传输,而不是中间有很多层。
3 由于只有一层交互,因此响应速度较快。(直接相连,中间没有什么阻隔或岔路,比如QQ,每天那么多人在线,也不觉得慢)
2、C/S架构的缺点:
可以将QQ作为类比:
1 适用面窄,通常用于局域网中。
2 用户群固定。由于程序需要安装才可使用,因此不适合面向一些不可知的用户。
3 维护成本高,发生一次升级,则所有客户端的程序都需要改变。
二、什么是B/S架构
B/S架构的全称为Browser/Server,即浏览器/服务器结构。
Browser指的是Web浏览器,极少数事务逻辑在前端实现,但主要事务逻辑在服务器端实现。
B/S架构的系统无须特别安装,只有Web浏览器即可。
其实就是我们前端现在做的一些事情,大部分的逻辑交给后台来实现,我们前端大部分是做一些数据渲染,请求等比较少的逻辑。
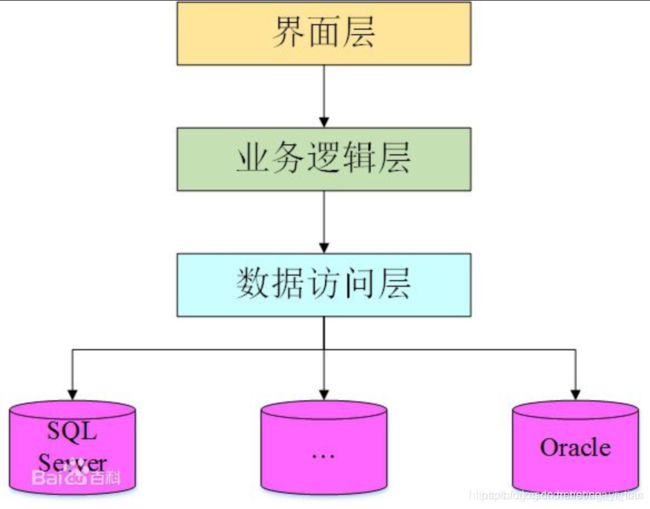
B/S架构的分层:
与C/S架构只有两层不同的是,B/S架构有三层,分别为:
第一层表现层:主要完成用户和后台的交互及最终查询结果的输出功能。
第二层逻辑层:主要是利用服务器完成客户端的应用逻辑功能。
第三层数据层:主要是接受客户端请求后独立进行各种运算。
如图所示:
B/S架构的优点:
1、客户端无需安装,有Web浏览器即可。
2、BS架构可以直接放在广域网上,通过一定的权限控制实现多客户访问的目的,交互性较强。
3、BS架构无需升级多个客户端,升级服务器即可。可以随时更新版本,而无需用户重新下载啊什么的。
B/S架构的缺点:
1、在跨浏览器上,BS架构不尽如人意。
2、表现要达到CS程序的程度需要花费不少精力。
3、在速度和安全性上需要花费巨大的设计成本,这是BS架构的最大问题。
4、客户端服务器端的交互是请求-响应模式,通常需要刷新页面,这并不是客户乐意看到的。(在Ajax风行后此问题得到了一定程度的缓解)
三、B/S架构的几种形式
第一种:客户端-服务器-数据库
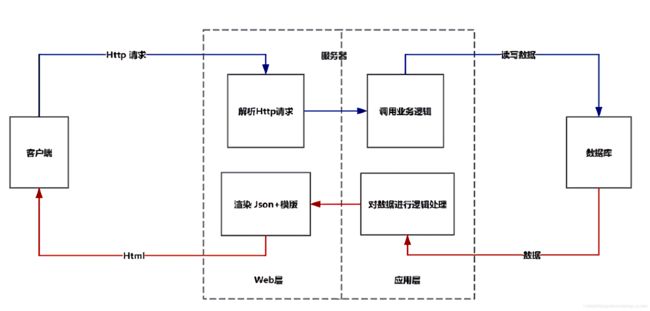
这个应该是我们平时比较常用的一种模式:
1、客户端向服务器发起Http请求
2、服务器中的web服务层能够处理Http请求
3、服务器中的应用层部分调用业务逻辑,调用业务逻辑上的方法
4、如果有必要,服务器会和数据库进行数据交换. 然后将模版+数据渲染成最终的Html, 返送给客户端
第二种:客户端-web服务器-应用服务器-数据库

类似于第一种方法,只是将web服务和应用服务解耦
1 客户端向web服务器发起Http请求
2 web服务能够处理Http请求,并且调用应用服务器暴露在外的RESTFUL接口
3 应用服务器的RESTFUL接口被调用,会执行对应的暴露方法.如果有必要和数据库进行数据交互,应用服务器会和数据库进行交互后,将json数据返回给web服务器
4 web服务器将模版+数据组合渲染成html返回给客户端
第三种方法:客户端-负载均衡器(Nginx)-中间服务器(Node)-应用服务器-数据库
这种模式一般用在有大量的用户,高并发的应用中。
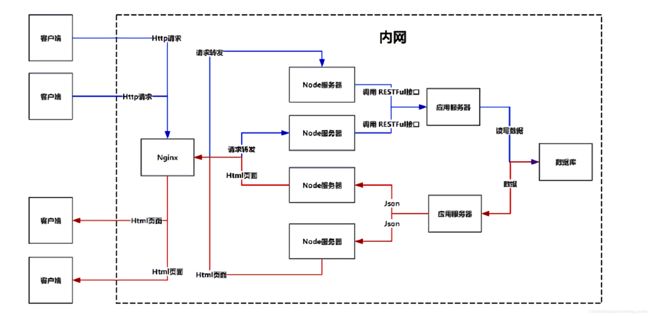
1、整正暴露在外的不是真正web服务器的地址,而是负载均衡器器的地址
2、客户向负载均衡器发起Http请求
3、负载均衡器能够将客户端的Http请求均匀的转发给Node服务器集群
4、Node服务器接收到Http请求之后,能够对其进行解析,并且能够调用应用服务器暴露在外的RESTFUL接口
5、应用服务器的RESTFUL接口被调用,会执行对应的暴露方法.如果有必要和数据库进行数据交互,应用服务器会和数据库进行交互后,将json数据返回给Node
6、Node层将模版+数据组合渲染成html返回反向代理服务器
7、反向代理服务器将对应html返回给客户端
Nginx的优点有:
1、它能够承受、高并发的大量的请求,然后将这些请求均匀的转发给内部的服务器,分摊压力.
2、反向代理能够解决跨域引起的问题,因为Nginx,Node,应用服务器,数据库都处于内网段中。
3、Nginx非常擅长处理静态资源(img,css,js,video),所以也经常作为静态资源服务器,也就是我们平时所说的CDN
比如:前一个用户访问index.html, 经过Nginx-Node-应用服务器-数据库链路之后,Nginx会把index.html返回给用户,并且会把index.html缓存在Nginx上,
下一个用户再想请求index.html的时候,请求Nginx服务器,Nginx发现有index.html的缓存,于是就不用去请求Node层了,会直接将缓存的页面(如果没过期的话)返回给用户。
四、发展前景
1、 C/S和B/S各有优势,C/S在图形的表现能力上以及运行的速度上肯定是强于B/S模式的,不过缺点就是他需要运行专门的客户端,而且更重要的是它不能跨平台,用c++在windows下写的程序肯定是不能在linux下跑的。
2、B/S模式就,它不需要专门的客户端,只要浏览器,而浏览器是随操作系统就有的,方便就是他的优势了。
而且,B/S是基于网页语言的、与操作系统无关,所以跨平台也是它的优势,而且以后随着网页语言以及浏览器的进步,
B/S在表现能力上的处理以及运行的速度上会越来越快,它的缺点将会越来越少。尤其是HTML5的普及,在图形的渲染方面以及音频、文件的处理上已经非常强大了。
不过,C/S架构也有着不可替代的作用。
————————————————
版权声明:本文为CSDN博主「雪飞_海」的原创文章
原文链接:https://blog.csdn.net/sea_snow/article/details/81187804
3、简述 三次握手、四次挥手的流程。
TCP三次握手与四次挥手过程
首先,客户端与服务器均处于未连接状态,并且是客户端主动向服务器请求建立连接:
客户端将报文段中的SYN=1,并选择一个seq=x,(即该请求报文的序号为x) 将这个报文发送到服务器。此时,客户端进入同步已发送状态(SYN-SEND).SYN报文段不能携带数据,但是要消耗掉一个序号。
服务器收到请求报文后,若同意建立连接,则回复报文中,SYN=1,ACK=1,并选择一个seq = y,且报文中确认号为x+1,序号为y .此时服务器进入同步已接收状态(SYN-RCVD)
客户端收到服务器的同步确认后,对服务器发送确认的确认。将ACK=1,确认号为y+1,而报文首部的序号为x+1,将该报文发出后,客户端进入已连接状态(ESTABLISHED)。
服务器收到客户端的确认后,也进入已连接状态。
以上即三次握手
为何使用三次握手机制:
假设如下异常情况:
客户端向服务器发送了第一条请求报文,但是该报文并未在网络中被丢弃,而是长时间阻滞在某处,而客户端收不到服务器确认,以为该报文丢失,于是重新发送该报文,这次的报文成功到达服务器,如果不使用三次握手,则服务器只需对该报文发出确认,就建立了一个连接。而在这个连接建立,并释放后,第一次发送的,阻滞在网络中的报文到达了服务器,服务器以为是客户端又重新发送了一个连接请求(实际上在客户端那里,该连接早已失效),就又向客户端发送一个确认,但客户端认为他没有发送该请求报文,因此不理睬服务器发送的确认,而服务器以为又建立了一个新的连接,于是一直等待A发来数据,造成了服务器资源的浪费,并且会产生安全隐患。因此,若使用三次握手机制,服务器发送了该确认后,收不到客户端的确认,也就知道并没有建立连接,因此不会将资源浪费在这种没有意义的等待上。

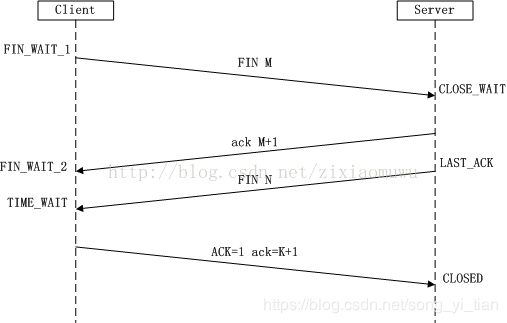
TCP连接的释放(四次挥手)
连接的释放较连接的建立复杂。
现假设客户端与服务器均处于连接建立状态,客户端主动断开连接:
1.客户端向服务器发送FIN报文:FIN=1,序号seq=上一个最后传输的字节序号+1=u,发送后,客户端进入FIN-WAIT-1状态。
2.服务器接收到该报文后,发送一个确认报文:令ACK=1,确认序号ack = u+1,自己的报文序号seq=v,发送后,服务器进入CLOSE-WAIT状态。
3.此时TCP连接进入连接半关闭状态,服务器可能还会向客户端发送一些数据。
4.客户端收到来自服务器的确认之后,进入FIN-WAIT-2状态。等待服务器发送连接释放报文。
5.如果服务器已经没有要发送的数据,则释放TCP连接,向客户端发送报文:令FIN=1,ACK=1,确认号ack =u+1,自己的序号seq = w(w可能等于v也可能大于v),服务器进入LAST-ACK状态。
6.客户端收到服务器的连接释放报文后,对该报文发出确认,令ACK=1,确认号ack=w+1,自己的序号seq=u+1,发送此报文后,等待2个msl时间后,进入CLOSED状态。
7.服务器收到客户端的确认后,也进入CLOSED状态并撤销传输控制块。
客户端状态变化:未连接----->SYN-SEND----->ESTABLISHED----->FIN-WAIT-1----->FIN-WAIT-2----->TIME-WAIT----->CLOSED
服务器状态变化:未连接----->SYN-RCVD----->ESTABLISHED----->CLOSE-WAIT----->LAST-ACK----->CLOSED
通俗描述3次握手就是
A对B说:我的序号是x,我要向你请求连接;(第一次握手,发送SYN包,然后进入SYN-SEND状态)
B听到之后对A说:我的序号是y,期待你下一句序号是x+1的话(意思就是收到了序号为x的话,即ack=x+1),同意建立连接。(第二次握手,发送ACK-SYN包,然后进入SYN-RCVD状态)
A听到B说同意建立连接之后,对A说:与确认你同意与我连接(ack=y+1,ACK=1,seq=x+1)。(第三次握手,A已进入ESTABLISHED状态)
B听到A的确认之后,也进入ESTABLISHED状态。
描述四次挥手就是:
1.A与B交谈结束之后,A要结束此次会话,对B说:我要关闭连接了(seq=u,FIN=1)。(第一次挥手,A进入FIN-WAIT-1)
2.B收到A的消息后说:确认,你要关闭连接了。(seq=v,ack=u+1,ACK=1)(第二次挥手,B进入CLOSE-WAIT)
3.A收到B的确认后,等了一段时间,因为B可能还有话要对他说。(此时A进入FIN-WAIT-2)
4.B说完了他要说的话(只是可能还有话说)之后,对A说,我要关闭连接了。(seq=w, ack=u+1,FIN=1,ACK=1)(第三次挥手)
5.A收到B要结束连接的消息后说:已收到你要关闭连接的消息。(seq=u+1,ack=w+1,ACK=1)(第四次挥手,然后A进入CLOSED)
6.B收到A的确认后,也进入CLOSED。

最简单的理解
一:建立TCP连接:三次握手协议
客户端:我要对你讲话,你能听到吗;
服务端:我能听到;而且我也要对你讲话,你能听到吗;
客户端:我也能听到。
…….
互相开始通话
………
二:关闭TCP连接:四次握手协议
客户端:我说完了,我要闭嘴了;
服务端:我收到请求,我要闭耳朵了;
(客户端收到这个确认,于是安心地闭嘴了。)
…….
服务端还没倾诉完自己的故事,于是继续唠唠叨叨向客户端说了半天,直到说完为止
…….
服务端:我说完了,我也要闭嘴了;
客户端:我收到请求,我要闭耳朵了;(事实上,客户端为了保证这个确认包成功送达,等待了两个最大报文生命周期后,才闭上耳朵。)
(服务端收到这个确认,于是安心地闭嘴了。)
————————————————
版权声明:本文为CSDN博主「lizmit」的原创文章
原文链接:https://blog.csdn.net/qq_35216516/article/details/80554575
4、什么是arp协议?
链接地址点击进入
5、TCP和UDP的区别?
链接地址点击进入
6、什么是局域网和广域网?
正如题目所问,平时我们经常会听到这些熟悉的名词,但是当别人问我们他们之间到底有什么区别时,却发现自己也解释不清楚,不知道怎么去回答。下面本文将去探索他们是什么,相互之间有什么区别。
局域网:(Local Area Network,LAN), 局域网是一个局部范围的计算组,比如家庭网络就是一个小型的局域网,里面包含电脑、手机和平板等,他们共同连接到你家的路由器上。又比如学校的机房就是一个局域网,里面有几百几千台电脑,当机房无法上外网时,但是电脑之间仍可以通信,你们可以通过这个局域网来打CS 、玩红警。理论上,局域网是封闭的,并不可以上外网,可以只有两台电脑,也可以有上万台。
广域网:(WAN,Wide Area Network),广域网的范围就比较大了,可以把你家和别人家、各个省、各个国家连接起来相互通信。广域网和局域网都是从范围的角度来划分的,广域网也可以看成是很多个局域网通过路由器等相互连接起来。
以太网:(Ethernet),以太网可以看成是一种实现局域网通信的技术标准,是目前最广泛的局域网技术。以太网的运行速率有10Mbps,100Mbps,1Gbps,10Gbps的,它的传输介质有的是双绞线,有的是光纤。 简单的说,以太网就是在局域网内,把附近的设备连接起来,可以进行通讯。
互联网:(Internet),互联网可以看成是局域网、广域网等组成的一个最大的网络,它可以把世界上各个地方的网路都连接起来,个人、政府、学校、企业,只要你能想到的,都包含在内。互联网是一种宽泛的概念,是一个极其庞大的网络。
————————————————
版权声明:本文为CSDN博主「夜风~」的原创文章
原文链接:https://blog.csdn.net/u014470361/article/details/79231787
7、为何基于tcp协议的通信比基于udp协议的通信更可靠?
tcp协议一定是先建好双向链接,发一个数据包要得到确认才算发送完成,没有收到就一直给你重发;udp协议没有链接存在,udp直接丢数据,不管你有没有收到。
TCP的可靠保证,是它的三次握手双向机制,这一机制保证校验了数据,保证了他的可靠性。
而UDP就没有了,udp信息发出后,不验证是否到达对方,所以不可靠。
不过UDP的速度是TCP比不了的,而且UDP的反应速度更快,QQ就是用UDP协议传输的,HTTP是用TCP协议传输的,不用我说什么,自己体验一下就能发现区别了。
再有就是UDP和TCP的目的端口不一样(这句话好象是多余的),而且两个协议不在同一层,TCP在三层,UDP不是在四层就是七层。
注:搬运与 https://www.cnblogs.com/Rivend/p/12038675.html
8、什么是socket?简述基于tcp协议的套接字通信流程。
什么是 socket?简述基于 tcp 协议的套接字通信流程?
Socket的英文原义是"孔"或"插座"。通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,
可以用来实现不同虚拟机或不同计算机之间的通信。
在Internet上的主机一般运行了多个服务软件,同时提供几种服务。每种服务都打开一个Socket,并绑定到一个端口上,不同的端口对应于不同的服务。
基于tcp 协议的套接字通信流程:
1). 服务器先用 socket 函数来建立一个套接字,用这个套接字完成通信的监听。
2). 用 bind 函数来绑定一个端口号和 IP 地址。因为本地计算机可能有多个网址和 IP,每一个 IP 和端口有多个端口。需要指定一个 IP 和端口进行监听。
3). 服务器调用 listen 函数,使服务器的这个端口和 IP 处于监听状态,等待客户机的连接。
4). 客户机用 socket 函数建立一个套接字,设定远程 IP 和端口。
5). 客户机调用 connect 函数连接远程计算机指定的端口。
6). 服务器用 accept 函数来接受远程计算机的连接,建立起与客户机之间的通信。
7). 建立连接以后,客户机用 write 函数向 socket 中写入数据。也可以用 read 函数读取服务器发送来的数据。
8). 服务器用 read 函数读取客户机发送来的数据,也可以用 write 函数来发送数据。
9). 完成通信以后,用 close 函数关闭 socket 连接。
注:搬运与 https://www.cnblogs.com/Rivend/p/12047299.html
9、什么是粘包?socket 中造成粘包的原因是什么?哪些情况会发生粘包现象?
只有TCP有粘包现象,UDP永远不会粘包!
粘包:在接收数据时,一次性多接收了其它请求发送来的数据(即多包接收)。如,对方第一次发送hello,第二次发送world,
在接收时,应该收两次,一次是hello,一次是world,但事实上是一次收到helloworld,一次收到空,这种现象叫粘包。
原因
粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
什么情况会发生:
1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据很小,会合到一起,产生粘包)
2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
解决方案:
一个思路是发送之前,先打个招呼,告诉对方自己要发送的字节长度,这样对方可以根据长度判断什么时候终止接受。
注:搬运与 https://www.cnblogs.com/Rivend/p/12047330.html
参考链接:点击进入https://blog.csdn.net/Nice07/article/details/83515660
10、IO多路复用的作用?
参考链接:https://blog.csdn.net/SkydivingWang/article/details/74917897
11、什么是防火墙以及作用?
一、防火墙的基本概念
古时候,人们常在寓所之间砌起一道砖墙,一旦火灾发生,它能够防止火势蔓延到别的寓所。
现在,如果一个网络接到了Internet上面,它的用户就可以访问外部世界并与之通信。但同时,外部世界也同样可以访问该网络并与之交互。
为安全起见,可以在该网络和Internet之间插入一个中介系统,竖起一道安全屏障。
这道屏障的作用是阻断来自外部通过网络对本网络的威胁和入侵,提供扼守本网络的安全和审计的唯一关卡,它的作用与古时候的防火砖墙有类似之处,因此我们把这个屏障就叫做“防火墙”。
在电脑中,防火墙是一种装置,它是由软件或硬件设备组合而成,通常处于企业的内部局域网与Internet之间,限制Internet用户对内部网络的访问以及管理内部用户访问外界的权限。
换言之,防火墙是一个位于被认为是安全和可信的内部网络与一个被认为是不那么安全和可信的外部网络(通常是Internet)之间的一个封锁工具。
防火墙是一种被动的技术,因为它假设了网络边界的存在,它对内部的非法访问难以有效地控制。因此防火墙只适合于相对独立的网络,例如企业内部的局域网络等。
1.过滤不安全服务
基于这个准则,防火墙应封锁所有信息流,然后对希望提供的安全服务逐项开放,对不安全的服务或可能有安全隐患的服务一律扼杀在萌芽之中。
这是一种非常有效实用的方法,可以造成一种十分安全的环境,因为只有经过仔细挑选的服务才能允许用户使用。
2.过滤非法用户和访问特殊站点
基于这个准则,防火墙应先允许所有的用户和站点对内部网络的访问,然后网络管理员按照IP地址对未授权的用户或不信任的站点进行逐项屏蔽。
这种方法构成了一种更为灵活的应用环境,网络管理员可以针对不同的服务面向不同的用户开放,也就是能自由地设置各个用户的不同访问权限。
参考链接:https://www.cnblogs.com/Rivend/p/12052499.html
12、select、poll、epoll 模型的区别?
POLL模型
Poll功能:监测文件描述符上,是否有某些事件发生
1.函数:
#include
int poll(struct pollfd fds,unsigned int nfds,int timeout);
参数:
(1)fds:是一个poll函数监听的struct pollfd结构类型的数组,每一个元素中,包含了三部分内容:文件描述符,监听的事件集合,返回的事件集合。
pollfd结构体定义如下:
struct pollfd
{
int fd; //文件描述符(scoket描述符)
short events; //等待的事件
short revents; //实际发生了的事件
};
event和revent的取值是一样的,常用的事件:
POLLIN 有数据可读
POLLOUT 写数据不会导致堵塞
POLLMSGIGPOLL 消息可用
POLLERR 指定的文件描述发生错误
nfds:和select函数的第一个参数相同,最大scoket描述符+1
timeout:表示poll函数的超时时间,单位是毫秒(ms)
注意:timeout==0 代表立即返回
timeout>0 代表等待指定的毫秒数后,返回
timeout<0 代表永不过期,就是阻塞
poll的返回值:==0 等待超时
>0 正常返回
==-1 错误
2.和select的区别
poll没有socket的FD_SETSIZE(1024)个数的限制
poll不用每次不会清理监测的socket的集合
不同与select使用三个位图来表示三个fdset的方式,poll使用一个Pollfd的指针实现。
3.poll的缺点
poll中监听的文件描述符数目增多时,则:
和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符
每次调poll都需要大量的pollfd结构从用户态拷贝到内核中。
同时连接的大量客户端在一时刻只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
select模型:
select用于IO复用,用于监视多个文件描述符的集合,判断是否有符合条件的事件发生。
函数select可以先对需要操作的文件描述符进行查询,查看是否目标文件描述符可以进行读写或者错误操作,然后当文件描述符满足操作的条件的时候才进行真正的IO操作
函数原型如下:
int select(int nfds,//nfds最大文件描述符+1
fd_setreadfds,//监控的所有读文件描述符集合
fd_set *writes,//写集合
fd_set exceptfds //异常集合
struct timeval timeout);//超长时间
返回值:>0正常(正常情况下返回就绪的文件描述符个数)
=0 超时
=-1 发生错误(select被某个信号中断它将返回-1并设置errno为EINTR)
EBADF 文件描述词为无效的或该文件已关闭
EINTR 此调用被信号所中断
EINVAL 参数n为负值
#从某个文件描述符的集合中取出某个文件描述符
void FD_CLR(int fd,fd_setset);
#测试某个文件描述符是否在某个集合中
int FD_ISSET(int fd,fd_setset)
#向某个文件描述符集合中加入文件描述符
void FD_SET(int fd,fd_set *set);
#清理文件描述符集合
void FD_ZERO(fd_set *set);
注意:文件描述符的集合存在最大的限制,其最大值为FD_SETSIZE=1024
优点:与多进程多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程,线程,也不必维护这些进城线程,从而大大减小了系统的开销。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是写就绪或读就绪),能通知程序进行相应的读写操作。
epoll模型:
epoll是select和poll的增强版本,相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到一个内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
epoll相关的函数:
#include
int epoll_create(int size);
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event):
int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout)
epoll_create
功能:用来创建epoll实例,,创建一个epoll的句柄。(注意:最后要关闭epoll的句柄)
参数size:当创建好这个句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
函数描述:epoll_create返回的是一个文件描述符,也就是说epoll是以特殊文件的方式体现给用户,size提示操作系统,用户可能使用多少个文件描述符,该参数已废弃,填写一个大于0的正整数
返回值:大于0:成功,-1:出错
epoll_ctl
功能:用来增加或移除被epoll所监听的文件描述符,epoll的事件注册函数(epoll在这里先注册要监听的事件类型)
参数:epfd :epoll上下文描述符,就是epoll_create函数的返回值
op:EPOLL_CTL_ADD向epoll监听集合当中添加socket描述符
EPOLL_CTL_DEL从epoll监听当中删除socket描述符
EPOLL_CTL_MOD修改
fd socket描述符,对TCP来说就是accept函数的返回值
event 在向epoll监听集合当中添加socket描述符的同时,为描述符绑定一个触发事件
event可以是以下宏的集合:
EPOLLIN:表示对应的文件描述符可以读(包括对端socket正常关闭)
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可以读
EPOLLERR:表示对应的文件描述符发生错误
EPOLLHUP:表示对应的文件描述符被挂断
EPOLLET:将EPOLL设为边缘触发模式,这是相对于水平触发来说的
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里。
返回值:0:成功 -1:出错
epoll_wait
功能:用来等待发生在监听描述符上的事件的产生,类似于select调用。(等待epfd_所代表的epoll实例中监听的事件发生,events指针返回已经准备好的事件,最多有maxevents个,参数maxevents必须大于零)
参数:epfd:标识epoll的文件描述符
events:用来从内核得到事件的集合
maxevents:告知内核这个events有多大,这个maxevents的值不能大于创建epoll—_create()时的size
timeout:是超时时间
返回值:return>0,发生事件个数 =0 时间到 -1 出错
该函数返回需要处理的事件数目,如返回0表示已超时。
epoll的优点:
1、支持一个进程打开大数目的socket描述符(FD)
select最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是1024,对于那些需要支持的上万连接数目的IM服务器来说显然太少了。不过epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字远大于1024,比如,在1GB内存的机器上大约是10万左右,具体数目可以cat/pro/sys/fs/file-max查看,一般来说这个数目和系统内存关系很大。
2.IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是“活跃”的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降,而epoll不存在此问题。
3.使用mmap加速内核与用户空间的消息传递
epoll是通过内核于用户空间mmap同一块内存实现的
epoll、poll、select三者的区别与比较:
select、poll实现需要自己不断轮询所有fd集合,直到设备就绪,此段时间,它们可能多次睡眠与唤醒交替进行。epoll虽需要调用epoll_wait不断轮询就绪链表,也会经历多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,就把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和唤醒交替,但是select和poll在醒着时要遍历整个fd集合,而epoll在醒着时只要判断一下就绪链表是否为空就行了(可以节省大量的CPU时间)。
select,poll每次调用都要把fd集合从用户态网内核态拷贝一次,而epoll只要拷贝一次。
下面列出如下表格来进行比较:

总结:I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的读写操作。select、poll、epoll都是I/O多路复用的机制。但select、poll、epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
————————————————
版权声明:本文为CSDN博主「weixin_42904113」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42904113/article/details/97647412
13、简述 进程、线程、协程的区别 以及应用场景?
1.进程是计算器最小资源分配单位 .
2.线程是CPU调度的最小单位 .
3.进程切换需要的资源很最大,效率很低 .
4.线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下) .
5.协程切换任务资源很小,效率高(协程本身并不存在,是程序员通过控制IO操作完成) .
6.多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发.
进程:
一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所以进程间数据不共享,开销大。
线程:
调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
协程:
是一种用户态的轻量级线程,协程的调度完全由用户控制。
协程拥有自己的寄存器上下文和栈。
协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,
可以不加锁的访问全局变量,所以上下文的切换非常快。
原文链接:https://www.cnblogs.com/Rivend/p/12052550.html
14、GIL锁是什么鬼?
全局解释锁,每次只能一个线程获得cpu的使用权:为了线程安全,也就是为了解决多线程之间的数据完整性和状态同步而加的锁,因为我们知道线程之间的数据是共享的。
大神讲解:http://cenalulu.github.io/python/gil-in-python/
15、Python中如何使用线程池和进程池?
为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。
那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。
第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。
因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,
等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,
拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
from multiprocessing import Pool
from multiprocessing import Process
import time
import os
def func(n):
print("子进程开始: %s"%n, os.getpid())
time.sleep(1)
print("子进程结束: %s" % n, os.getpid())
if __name__ == "__main__":
# 开启了5个进程
pool = Pool(5)
for i in range(10):
# 正常情况下先执行5个start 后执行5个end
p = Process(target=func,args=(i,))
p.start()
线程池的使用
import time
from concurrent.futures import ThreadPoolExecutor
def func(n):
print(n)
time.sleep(1)
return n * 10
t_lst = []
# 定义一个线程池(默认 不要超过cup个数*5)
tpool = ThreadPoolExecutor(max_workers=5)
for i in range(20):
# 传值(开启20个子线程)
t = tpool.submit(func, i)
t_lst.append(t)
# 相当于 close + join
tpool.shutdown()
print("主线程")
for t in t_lst:
# t.result() 接受返回值
print("\033[31m ==== \033[0m", t.result())
16、threading.local的作用?
**threading.local()这个方法的特点用来保存一个全局变量,但是这个全局变量只有在当前线程才能访问,如果你在开发多线程应用的时候 需要每个线程保存一个单独的数据供当前线程操作,可以考虑使用这个方法,简单有效。**举例:每个子线程使用全局对象a,但每个线程定义的属性a.xx是该线程独有的,Python提供了 threading.local 类,将这个类实例化得到一个全局对象,但是不同的线程使用这个对象存储的数据其它线程不可见(本质上就是不同的线程使用这个对象时为其创建一个独立的字典)。
基本概念:同一进程内的内存栈是全局的。
threading.local本质上是对全局字典对象管理类的一个封装,
内部自动为每个线程维护一个空间(字典),用于当前存取属于自己的值。保证线程之间的数据隔离。
主要的目的是线程之间的数据隔离。
当然,自己写也不是不可以,但开发的一个宗旨是不必重复造轮子。
案例源码:
import time
import threading
local = threading.local()
def func(n):
print(threading.current_thread())
local.val = n
time.sleep(2)
print(n)
for i in range(10):
t = threading.Thread(target=func,args=(i,))
t.start()
实质上local.val = n等效于local._local__impl.dicts[‘thread_id’][‘val’] = n
另外需要注意的是local类重写了取值方法。
搬运与:https://www.cnblogs.com/insane-Mr-Li/p/12092029.html
17、进程之间如何进行通信?
1、管道
我们来看一条 Linux 的语句
netstat -tulnp | grep 8080
学过 Linux 命名的估计都懂这条语句的含义,其中”|“是管道的意思,它的作用就是把前一条命令的输出作为后一条命令的输入。在这里就是把 netstat -tulnp 的输出结果作为 grep 8080 这条命令的输入。如果两个进程要进行通信的话,就可以用这种管道来进行通信了,并且我们可以知道这条竖线是没有名字的,所以我们把这种通信方式称之为匿名管道。
并且这种通信方式是单向的,只能把第一个命令的输出作为第二个命令的输入,如果进程之间想要互相通信的话,那么需要创建两个管道。
居然有匿名管道,那也意味着有命名管道,下面我们来创建一个命名管道。
mkfifo test
这条命令创建了一个名字为 test 的命名管道。
接下来我们用一个进程向这个管道里面写数据,然后有另外一个进程把里面的数据读出来。
echo "this is a pipe" > test // 写数据
这个时候管道的内容没有被读出的话,那么这个命令就会一直停在这里,只有当另外一个进程把 test 里面的内容读出来的时候这条命令才会结束。接下来我们用另外一个进程来读取
cat < test // 读数据
我们可以看到,test 里面的数据被读取出来了。上一条命令也执行结束了。
从上面的例子可以看出,管道的通知机制类似于缓存,就像一个进程把数据放在某个缓存区域,然后等着另外一个进程去拿,并且是管道是单向传输的。
这种通信方式有什么缺点呢?显然,这种通信方式效率低下,你看,a 进程给 b 进程传输数据,只能等待 b 进程取了数据之后 a 进程才能返回。
所以管道不适合频繁通信的进程。当然,他也有它的优点,例如比较简单,能够保证我们的数据已经真的被其他进程拿走了。我们平时用 Linux 的时候,也算是经常用。
2、消息队列
那我们能不能把进程的数据放在某个内存之后就马上让进程返回呢?无需等待其他进程来取就返回呢?
答是可以的,我们可以用消息队列的通信模式来解决这个问题,例如 a 进程要给 b 进程发送消息,只需要把消息放在对应的消息队列里就行了,b 进程需要的时候再去对应的
消息队列里取出来。同理,b 进程要个 a 进程发送消息也是一样。这种通信方式也类似于缓存吧。
这种通信方式有缺点吗?答是有的,如果 a 进程发送的数据占的内存比较大,并且两个进程之间的通信特别频繁的话,消息队列模型就不大适合了。因为 a 发送的数据很大的话,意味**发送消息(拷贝)**这个过程需要花很多时间来读内存。
哪有没有什么解决方案呢?答是有的,请继续往下看。
3、共享内存
共享内存这个通信方式就可以很好着解决拷贝所消耗的时间了。
这个可能有人会问了,每个进程不是有自己的独立内存吗?两个进程怎么就可以共享一块内存了?
我们都知道,系统加载一个进程的时候,分配给进程的内存并不是实际物理内存,而是虚拟内存空间。那么我们可以让两个进程各自拿出一块虚拟地址空间来,然后映射到相同的物理内存中,这样,两个进程虽然有着独立的虚拟内存空间,但有一部分却是映射到相同的物理内存,这就完成了内存共享机制了。
4、信号量
共享内存最大的问题是什么?没错,就是多进程竞争内存的问题,就像类似于我们平时说的线程安全问题。如何解决这个问题?这个时候我们的信号量就上场了。
信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存1的时候,我们就把信号量的值设为 0,然后进程b 也要来访问内存1的时候,看到信号量的值为 0 就知道已经有进程在访问内存1了,这个时候进程 b 就会访问不了内存1。所以说,信号量也是进程之间的一种通信方式。
5、Socket
上面我们说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?
答是必须的,这个时候 Socket 这家伙就派上用场了,例如我们平时通过浏览器发起一个 http 请求,然后服务器给你返回对应的数据,这种就是采用 Socket 的通信方式了。
总结
所以,进程之间的通信方式有:
1、管道
2、消息队列
3、共享内存
4、信号量
5、Socket
讲到这里也就完结了,之前我看进程之间的通信方式的时候,也算是死记硬背,并没有去理解他们之间的关系,优缺点,为什么会有这种通信方式。所以最近花点时间去研究了一下,
整理了这篇文章,相信看完这篇文章,你就可以更好着理解各种通信方式的由来的。
————————————————
版权声明:本文为CSDN博主「帅地」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_37907797/article/details/103188294
18、什么是并发和并行?
做并发编程之前,必须首先理解什么是并发,什么是并行,什么是并发编程,什么是并行编程。
并发(concurrency)和并行(parallellism)是:
解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群
所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能
并发(Concurrent),
在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
就想前面提到的操作系统的时间片分时调度。打游戏和听音乐两件事情在同一个时间段内都是在同一台电脑上完成了从开始到结束的动作。那么,就可以说听音乐和打游戏是并发的。
并行
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
这里面有一个很重要的点,那就是系统要有多个CPU才会出现并行。在有多个CPU的情况下,才会出现真正意义上的『同时进行』。
并发与并行
我们两个人在吃午饭。你在吃饭的整个过程中,吃了米饭、吃了蔬菜、吃了牛肉。吃米饭、吃蔬菜、吃牛肉这三件事其实就是并发执行的。
对于你来说,整个过程中看似是同时完成的的。但其实你是在吃不同的东西之间来回切换的。
还是我们两个人吃午饭。在吃饭过程中,你吃了米饭、蔬菜、牛肉。我也吃了米饭、蔬菜和牛肉。
我们两个人之间的吃饭就是并行的。两个人之间可以在同一时间点一起吃牛肉,或者一个吃牛肉,一个吃蔬菜。之间是互不影响的。
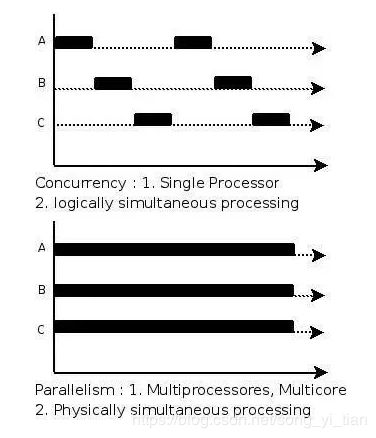
所以,并发是指在一段时间内宏观上多个程序同时运行。并行指的是同一个时刻,多个任务确实真的在同时运行。
并发和并行的区别
并发,指的是多个事情,在同一时间段内同时发生了。
并行,指的是多个事情,在同一时间点上同时发生了。
并发的多个任务之间是互相抢占资源的。
并行的多个任务之间是不互相抢占资源的、
只有在多CPU的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。

19、进程锁和线程锁的作用?
线程锁:
多线程可以同时运行多个任务但是当多个线程同时访问共享数据时,可能导致数据不同步,甚至错误! so,不使用线程锁, 可能导致错误
大家都不陌生,主要用来给方法、代码块加锁。当某个方法或者代码块使用锁时,那么在同一时刻至多仅有有一个线程在执行该段代码。
当有多个线程访问同一对象的加锁方法/代码块时,同一时间只有一个线程在执行,其余线程必须要等待当前线程执行完之后才能执行该代码段。但是,其余线程是可以访问该对象中的非加锁代码块的。
进程锁:
也是为了控制同一操作系统中多个进程访问一个共享资源,
只是因为程序的独立性,各个进程是无法控制其他进程对资源的访问的,
但是可以使用本地系统的信号量控制(操作系统基本知识)
优点:保证资源同步
缺点:有等待肯定会慢
原文链接:w.cnblogs.com/Rivend/p/12058156.html
20、解释什么是异步非阻塞?
在IO和网络编程中,我们经常看到几个概念:同步、异步、阻塞、非阻塞。
同步和异步
同步和异步是针对应用程序和内核的交互而言的,同步指的是用户进程触发IO 操作并等待或者轮询的去查看IO 操作是否就绪,而异步是指用户进程触发IO 操作以后便开始做自己的事情,而当IO 操作已经完成的时候会得到IO 完成的通知。
阻塞和非阻塞
阻塞和非阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作方法的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入方法会立即返回一个状态值。
理解方式
乍一看这四个概念的解释会瞬间感到头大,也经常讲同步异步等同于阻塞非阻塞,其实,区分他们非常简单。
同步异步与阻塞非阻塞的主要区别是针对对象不同。
同步异步是针对调用者来说的,调用者发起一个请求后,一直干等被调用者的反馈就是同步,不必等去做别的事就是异步。
阻塞非阻塞是针对被调用者来说的,被调用者收到一个请求后,做完请求任务后才给出反馈就是阻塞,收到请求直接给出反馈再去做任务就是非阻塞。
在公交站等公交
对调用者-乘客而言:
1,一直干望着公交来的方向,就是同步。
2,不望着公交来的方向,掏出笔记本改bug,听公交站广播是否到车,就是异步。
对被动用者-公交系统而言:
1,公交站有广播的就是非阻塞的。
2,公交站没有广播的就是阻塞的。
原文链接;https://www.cnblogs.com/Rivend/p/12065474.htmlv
21、路由器和交换机的区别?
第一,使用交换机上网是分别拨号,各自使用自己的宽带账号,大家上网互不影响。而路由器是共用一个宽带账号,大家上网会相互影响。
第二,交换机工作在中继层,交换机根据MAC地址寻址。路由器工作在网络层,根据IP地址寻址。
第三,交换机可以使连接它的多台电脑组成局域网,如果还有代理服务器的话还可以实现同时上网功能,但是交换机没有路由器的自动识别数据包发送和到达地址的功能。
第四,路由器提供了防火墙的服务。路由器仅仅转发特定地址的数据包,不传送不支持路由协议的数据包传送。
22、什么是域名解析?
域名解析也称为域名指向、服来务器设置、域名配置、反向ip注册等。简单地说,将一个可记忆的域名解析为一个ip,服务由dns服务器完成,dns服务器将域名解析为一个ip地址,并将一个子目录绑定到ip地址主机上知的域名。
域名解析就像在移动电话上使用对方的姓名来表示对方的电话号码一样,因为它很容易记道住。Dns是文本到ip号码的解析。
域名解析的过程详解
23、如何修改本地hosts文件?
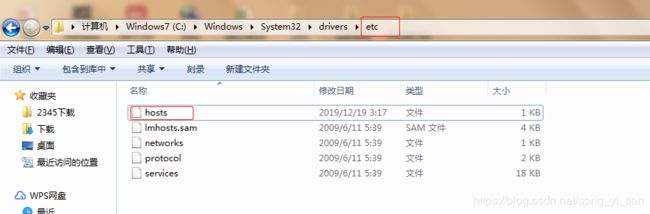
1.window7修改本地hosts文件
# window7系统hosts文件位置
C:\Windows\System32\drivers\etc
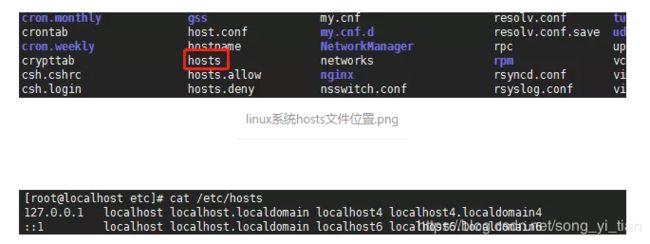
2.linux
# linux系统hosts文件位置
[root@localhost etc]# cat /etc/hosts
24、生产者消费者模型应用场景及优势?
在 工作中,大家可能会碰到这样一种情况:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。
产 生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
在生产者与消费者之间在加个缓冲区,我们形象的称之为仓库,生产者负责往仓库了进商 品,而消费者负责从仓库里拿商品,这就构成了生产者消费者模型。
结构图如下:

生产者消费者模型的优点:
1、解耦
假设生产者和消费者分别是两个类。
如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。
将来如果消费者的代码发生变化, 可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
举个例子,我们去邮局投递信件,如果不使用邮筒(也就是缓冲区),你必须得把信直接交给邮递员。
有同学会说,直接给邮递员不是挺简单的嘛?其实不简单,你必须 得认识谁是邮递员,才能把信给他(光凭身上穿的制服,万一有人假冒,就惨了)。
这就产生和你和邮递员之间的依赖(相当于生产者和消费者的强耦合)。
万一哪天邮递员换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码)。
而邮筒相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)。
2、支持并发
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,
就可以继续生产下一个数据,而消费者只需要从缓冲区了拿数据即可,这样就不会因为彼此的处理速度而发生阻塞。
接上面的例子,如果我们不使用邮筒,我们就得在邮局等邮递员,直到他回来,
我们把信件交给他,这期间我们啥事儿都不能干(也就是生产者阻塞),或者邮递员得挨家挨户问,谁要寄信(相当于消费者轮询)。
3、支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。 等生产者的制造速度慢下来,消费者再慢慢处理掉。
为了充分复用,我们再拿寄信的例子来说事。假设邮递员一次只能带走1000封信。万一某次碰上情人节(也可能是圣诞节)送贺卡,
需要寄出去的信超过1000封,这时 候邮筒这个缓冲区就派上用场了。邮递员把来不及带走的信暂存在邮筒中,等下次过来 时再拿走。
应用场景:
使用多线程,在做爬虫的时候,生产者用着产生url链接,消费者用于获取url数据,在队列的帮助下可以使用多线程加快爬虫速度。
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
print content
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://211.103.242.133:8080/Disease/Details.aspx?id=2258',
'http://211.103.242.133:8080/Disease/Details.aspx?id=2258',
'http://211.103.242.133:8080/Disease/Details.aspx?id=2258',
'http://211.103.242.133:8080/Disease/Details.aspx?id=2258'
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
for url in urls:
queue.put(url)
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
25、什么是CDN?有什么用?
CDN的全称是内容分发网络,比如我们客户端向服务器请求一个数据,当这个数据很大,请求频繁,而且服务器距离客户端很远这样是不是很浪费资源,浪费大量的带宽,严重时候还会造成网络阻塞。而且这样响应时间非常慢。
CDN主要由负载均衡,和高速缓存服务器组成。其中分为中心部分和边缘部分。中心部分就是负责全局负载均衡,当客户端发送请求,首先会访问中心CDN,经过全局负载均衡,根据用户请求的ip 地址,一定的算法,然后算出距离用户最近,用户接入量最少得CDN缓存服务器,这样是不是相当于走了捷径。因为cdn是介于客户端和请求服务器之间的一个缓存服务器,有一点点像redis缓存。当然第一次请求的时候,cdn没有缓存的话,cdn也会请求一次服务器,然后根据服务器返回的数据一方面留给自己缓存作为备用,另一方面也返回给客户端,好像现在像腾讯网,阿里云都有提供cdn服务器。而且域名配置服务器时候,就可以配到cdn。
而且现在应用也很多,比如网络教学,金融,证券,不允许有过多延迟和数据较大的应用。这就是我大致了解的cdn ,content delivery network ,内容分发网络。
CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
目前的CDN服务主要应用于证券、金融保险、ISP、ICP、网上交易、门户网站、大中型公司、网络教学等领域。另外在行业专网、互联网中都可以用到,甚至可以对局域网进行网络优化。利用CDN,这些网站无需投资昂贵的各类服务器、设立分站点,特别是流媒体信息的广泛应用、远程教学课件等消耗带宽资源多的媒体信息,应用CDN网络,把内容复制到网络的最边缘,使内容请求点和交付点之间的距离缩至最小,从而促进Web站点性能的提高,具有重要的意义。CDN 网络的建设主要有企业建设的CDN网络,为企业服务;IDC的CDN网络,主要服务于IDC和增值服务;网络运营上主建的CDN网络,主要提供内容推送服务;CDN网络服务商,专门建设的CDN用于做服务,用户通过与CDN机构进行合作,CDN负责信息传递工作,保证信息正常传输,维护传送网络,而网站只需要内容维护,不再需要考虑流量问题。
CDN的网络架构
CDN网络架构主要由两大部分,分为中心和边缘两部分,中心指CDN网管中心和DNS重定向解析中心,负责全局负载均衡,设备系统安装在管理中心机房,边缘主要指异地节点,CDN分发的载体,主要由Cache和负载均衡器等组成。
当用户访问加入CDN服务的网站时,域名解析请求将最终交给全局负载均衡DNS进行处理。全局负载均衡DNS通过一组预先定义好的策略,将当时最接近用户的节点地址提供给用户,使用户能够得到快速的服务。同时,它还与分布在世界各地的所有CDNC节点保持通信,搜集各节点的通信状态,确保不将用户的请求分配到不可用的CDN节点上,实际上是通过DNS做全局负载均衡。
对于普通的Internet用户来讲,每个CDN节点就相当于一个放置在它周围的WEB。通过全局负载均衡DNS的控制,用户的请求被透明地指向离他最近的节点,节点中CDN服务器会像网站的原始服务器一样,响应用户的请求。由于它离用户更近,因而响应时间必然更快。
每个CDN节点由两部分组成:负载均衡设备和高速缓存服务器
负载均衡设备负责每个节点中各个Cache的负载均衡,保证节点的工作效率;同时,负载均衡设备还负责收集节点与周围环境的信息,保持与全局负载DNS的通信,实现整个系统的负载均衡。
高速缓存服务器(Cache)负责存储客户网站的大量信息,就像一个靠近用户的网站服务器一样响应本地用户的访问请求。
CDN的管理系统是整个系统能够正常运转的保证。它不仅能对系统中的各个子系统和设备进行实时监控,对各种故障产生相应的告警,还可以实时监测到系统中总的流量和各节点的流量,并保存在系统的数据库中,使网管人员能够方便地进行进一步分析。通过完善的网管系统,用户可以对系统配置进行修改。
理论上,最简单的CDN网络有一个负责全局负载均衡的DNS和各节点一台Cache,即可运行。DNS支持根据用户源IP地址解析不同的IP,实现就近访问。为了保证高可用性等,需要监视各节点的流量、健康状况等。一个节点的单台Cache承载数量不够时,才需要多台Cache,多台Cache同时工作,才需要负载均衡器,使Cache群协同工作。
————————————————
版权声明:本文为CSDN博主「X_Ming_H」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xmh594603296/article/details/81435821
26、LVS是什么及作用?
一.LVS是什么?
LVS的英文全称是Linux Virtual Server,即Linux虚拟服务器。它是我们国家的章文嵩博士的一个开源项目。在linux内存2.6中,它已经成为内核的一部分,在此之前的内核版本则需要重新编译内核。
二.LVS能干什么?
LVS主要用于多服务器的负载均衡。它工作在网络层,可以实现高性能,高可用的服务器集群技术。它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。它易用,配置非常简单,且有多种负载均衡的方法。它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
27、Nginx是什么及作用?
1 nginx是什么?Welcome to nginx!
nginx是一款免费开源的高性能HTTP服务器及反向代理服务器(Reverse Proxy)
2 nginx优点及常用web服务器产品
静态web服务软件
1 Apache 中小型web服务的主流
优点:运行速度快,性能稳定,扩展丰富
缺点:以进程为结构基础,消耗cpu,性能下降
2 Lighttpd 开源轻量级web服务器软件
优点:1 安全,快速,兼容性好,灵活
2 低开销,低CPU使用率
3 支持大多数apache的重要功能
缺点: 功能存在不足,部分代码缺陷(如对proxy功能不完善)
动态web服务软件
1 Microsoft IIS 微软旗下产品
优点:可靠、安全、性能和扩展能力强
缺点:部署成本高
2 Tomcat(公猫) Sun公司旗下产品
优点:部署安装方便,系统占有率低,主要的Servlet和JSP容器
缺点:功能少,无法满足复杂业务场景
nginx优点
1 高并发连接
2 内存消耗少
3 稳定性高
3 Nginx 版本信息
nginx官网有三个版本
1 stable version 稳定版(企业用)
2 mainline version 开发版(个人用)
3 Legacy versions 历史版
4 Nginx功能特性
1.处理静态文件,索引文件以及自动索引
2.反向代理加速(无缓存),简单的负载均衡和容错
3.FastCGI,简单的负载均衡和容错
4.模块化的结构。过滤器包括gzipping,byte ranges,chunked responses,以及 SSI-filter。在SSI过滤 器中,到同一个 proxy 或者 FastCGI 的多个子请求并发处理
5.SSL 和 TLS SNI 支持
6.IMAP/POP3代理服务功
7.使用外部 HTTP 认证服务器重定向用户到 IMAP/POP3 后端
8.使用外部 HTTP 认证服务器认证用户后连接重定向到内部的 SMTP 后端
5 Nginx主要功能
1 nginx可作为HTTP代理服务和反向代理
2 nginx可作为负载均衡
3 nginx可作为Web缓存
————————————————
版权声明:本文为CSDN博主「VictoryKingLIU」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/VictoryKingLIU/article/details/91784881
28、keepalived是什么及作用?
大神讲解,点击进入
29、haproxy是什么以及作用?
HAProxy 是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。
HAProxy运行在时下的硬件上,完全可以支持数以万计的 并发连接。
并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
(作用: 高可用性,负载平衡和用于TCP和基于http的应用程序的代理)
原文链接:
https://www.cnblogs.com/Rivend/p/12075870.html
30、什么是负载均衡?
Load balancing,即负载均衡,是一种计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
参考链接https://www.cnblogs.com/fanBlog/p/10936190.html
31、什么是rpc及应用场景?
l链接地址:http://www.manongjc.com/article/72153.html
32、简述 asynio模块的作用和应用场景。
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
作者:把早晨六点的太阳留给我
链接:https://www.jianshu.com/p/17fe7ab54263
33、简述 gevent模块的作用和应用场景。
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成:
作者:把早晨六点的太阳留给我
链接:https://www.jianshu.com/p/17fe7ab54263
34、twisted框架的使用和应用?
Twisted是用Python实现的基于事件驱动的网络引擎框架,Twisted支持许多常见的传输及应用层协议,包括TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC以及FTP。就像Python一样,Twisted也具有“内置电池”(batteries-included)的特点。Twisted对于其支持的所有协议都带有客户端和服务器实现,同时附带有基于命令行的工具,使得配置和部署产品级的Twisted应用变得非常方便。
作者:把早晨六点的太阳留给我
链接:https://www.jianshu.com/p/17fe7ab54263