Bag of Freebies for Training Object Detection Neural Networks-论文阅读
摘要
本文提出了对定位网络具有普遍性的技巧,可以让定位算法的performance提升到一个新的高度。
简介
物体定位的任务吸引了各个领域研究者的注意,最近比较流行的算法有SSD,YOLO还有RCNN之类,这些网络的backbone都是分类网路比如VGG,ResNet,Inception和MobileNet等。
但是,因为网络的容量在变大,而且网络非常复杂,越来越少人关注定位网络的训练技巧。有些人训练定位网络直接使用他们训练分类网络的准则,不考虑特定的初始化,数据预处理,不对优化做分析,这样训练定位网络会比较混乱。
本文的目的就是研究可以对流行的定位网络提升准确率的方法,而不会给inference带来额外的消耗。首先研究的是物体定位上的mixup技术,作者意识到多目标检测任务有空间保留变换的特殊属性,而想到了对物体定位任务使用视觉上一致的图像混合方法。第二,作者提出了一系列训练方法,包括学习率的设定,weight decay和同步BN。第三,作者研究了有效的训练技巧去训练one-stage和multi-stage的定位网络。
主要的贡献可以总结如下:
1. 作者是第一个将各种训练技巧有条理的在不同的定位网络上进行验证,为未来的研究提供了有价值的指导方针。
2. 为物体定位网络提供了一个视觉上一致的图像混合方法,对模型泛化能力的提升非常有效。
3. 对现有模型不改变网络模型和损失函数的情况下,可以将准确率提升5个点,并且在预测的时候不会带来任何额外的时间花 费。
4. 研究了数据增强的方法,明显提升了模型的泛化能力,降低了过拟合。这种处理也会带来定位网络准确率的提升。
实验代码可以查看https://github.com/dmlc/gluon-cv
相关工作
1.分类网络的训练技巧
图像分类是所有视觉任务的基础,分类模型相对定位和分割网络更为简单,因此吸引了大量的研究人员研究优化方法。Learning rate warm up方法(备注1)是为了克服极大的batchsize带来的负面影响。虽然在物体定位上使用的mini batch尺寸和分类网络中的mini batch尺寸(10k或者30k)完全不是一个数量级,但是物体定位的anchor的个数却可以达到差不多的数量级。作者的实验证明了使用逐渐增大学习率的方法对YOLOv3网络是非常有用的。还有一系列的方法试图解决深度神经网络的脆弱性。Label smoothing(备注2)在交叉熵损失中修改了真实标签的label。 Mixup方法(备注3)可以缓解对抗性扰动。SGDR(备注4)提出了一种基于余弦的学习率衰减策略,不同于以前跳跃式的学习率衰减方式。在一篇论文(备注5)中提到通过一系列的技巧, 使分类网络的训练精度得到了重大的提升。本文就是通过分类网络训练技巧的启发来研究定位网络。
2.物体定位网络的准则
one-stage或者multi-stage的物体定位网络,比如YOLO系列或者RCNN系列都有各自的pipeline。one-stage的网络是直接通过卷积网络进行预测,所以空间上是对齐的。但是multi-stage的网络,最后的预测是基于RoI进行的,RoI是通过神经网络或者特定的算法生成的,这个主要的差别导致了在数据处理和优化网络上的重大差异。由于one-stage算法缺少空间上的变化,因此空间上的数据增强是非常有用的,已经在SSD上证明了。由于缺少研究,很多训练的细节都没有成体系,本文就是要系统的研究提升这两类算法的技巧。
备注1:参考Accurate, large minibatch sgd: training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017,主要是当batch size非常大的时候,学习率从小开始,然后逐渐增大的方法,因此叫做learning rate warmup
备注2:参考Rethinking the inception architecture for computer vision,对真实标签做一个均匀分布介入的变形,可以防止模型过于相信预测的类别。
备注3:参考mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017,使用mixup公式把普通的分布转为一种通用临近分布,这样可以让网络优化VRM,从而降低过拟合。
备注4:参考Sgdr: Stochastic gradient de- scent with warm restarts. arXiv preprint arXiv:1608.03983, 2016
备注5:Bag of tricks for image classification with convolutional neural networks. arXiv preprint arXiv:1812.01187, 2018
技术细节一:视觉上一致的图像混合技术
Mixup技术已经被证明了在分类网络中可以缓解对抗性扰动,在之前提到的mixup技术中混合比的分布是由beta分布得出的 (a=0.2,b=0.2)。大多数的混合数据仅仅是这个beta分布的噪声。受论文(备注6)的启发,作者考虑在图片的视觉上进行混合。
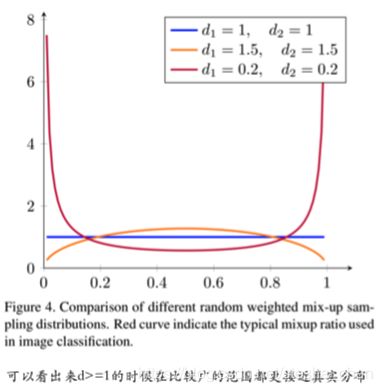
作者尝试持续增加Mixup方法中的混合比例,生成的图片会越来越接近自然展示的效果,实际上为了防止图像变形,在最初的步 骤还使用了几何对齐。图2和图3可以看到这两种混合方式的差别。作者仍然选择了beta分布,但是使用的 a>=1,b>=1,这样混合的图片更加有可视化的效果。图4可以看到不同混合比例的分布情况。
作者使用YOLOv3在Pascal VOC数据上做了尝试,验证不同权重对精度提升的效果,可以看到1.5时效果最好,参考表格1 。
为了验证有效性,作者还试验了“大象在房间”的情况,作者使用COCO数据训练了两个YOLOv3网络,差别就是一个使用了作者 提出的视觉一致的mixup方法,一个没有使用,可以看到没有使用mixup技术的网络不能正确识别出房间中的大象,使用了mixup的算法会更鲁棒一些。另外作者还发现使用了mixup的算法会更加谦逊,对识别物体的信心比较低。可以参考图5
备注6:The elephant in the room. arXiv preprint arXiv:1808.03305, 2018,这篇论文主要是尝试在一些房间里面贴入一张大象的图片,发现大多数算法都 不能识别出大象,对此提出了改进方法,从而增强了算法的抗干扰性。



技术细节二:Label Smoothing
对于每一个物体,定位网络常常会通过softmax函数计算出所有类别的可能性,softmax函数形式如下:
![]()
其中 是最后一层网络计算出来的logits。物体定位网络在训练的时候,分类的损失函数是输出的概率分布p和真实分布q之间的
是最后一层网络计算出来的logits。物体定位网络在训练的时候,分类的损失函数是输出的概率分布p和真实分布q之间的
交叉熵:
![]()
q一般是one-hot的形式,就是正确的类别是1,其他的类别是0。 使用softmax函数只有当 ≫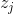 时才能接近one-hot的值,并且几 乎永远达不到one-hot值,这样会导致网络对自己的预测过于自 信并且也会出现过拟合(备注7)。
时才能接近one-hot的值,并且几 乎永远达不到one-hot值,这样会导致网络对自己的预测过于自 信并且也会出现过拟合(备注7)。
Label smoothing就是一种正则化的方式,将真值的分布变的更加平滑。
![]()
K是所有类别数, 是一个很小的常数。这个技术可以减少模型的自信度。
是一个很小的常数。这个技术可以减少模型的自信度。
备注7:由于我们的样本不能穷举所有的情况,可能存在某种特征的数据更多,网络会放大这种特征的重要性,而导致了数据的过拟合。
技术细节三:数据预处理
图像分类任务对图像几何变形的容忍度很高,所以图像分类任务 中为了提高泛化准确率很鼓励对图片进行变形。然而物体定位网 络对图像的预处理则需要小心,因为定位网络对这种变形会更敏感。
作者通过实验的方式回顾了一些图片增强的方法:
1.随机几何变换。包括随机裁剪,随机扩展,随机水平翻转和随机缩放。
2.随机颜色抖动。包括亮度,色调,饱和度和对比度的抖动。
有两种类型的物体定位网络,一种是one-stage算法,最终输出是由特征图上每个像素点生成的,例如SSD和YOLO他们的输出尺 寸都是有一定比例的;另一种是multi-stage方法,比如Fast RCNN,对大量的IoU进行固定数量的采样,检测结果由对应候选框大小的特征图生成,预测结果与固定采样数量成正比。
由于基于采样的方法在特征图上重复进行了大量的剪裁,可以替代在输入图片上进行随机剪裁的操作,因此这里网络在训练阶段 不需要进行几何的数据增强。(one-stage网络适合进行几何数据增强,并且两种网络都适合进行随机颜色抖动的增强方式)
技术细节四:重新计划学习率
在训练的时候学习率一般都是从一个相对比较大的数开始,随着训练过程慢慢变小。最常用的方式就是达到某些epochs或者 iterations后,就将学习率乘以一个小于1的常数。比如Faster RCNN在60k迭代后,会将学习率乘以0.1,相似的,YOLOv3会在40k和45k迭代后分别将学习率乘以0.1。这种方式是比较突然的变化学习率,导致在变化后需要一些迭代次数来稳定学习动量。 SGDR论文中提出了一种比较平滑的使用余弦来改变学习率的方式。通过余弦函数从0到pi的变化来逐渐调整学习率,这种方式 在最开始会比较慢的降低学习率,然后会比较快的降低学习率, 最后梯度比较小的时候是慢慢降低学习率直到0。
在这个式子里面可以看出,随着迭代次数Tcurr 的逐渐增大,余弦函数的取值在1到-1之间变化,从而将学习率从最大值慢慢变成 最小值。
学习率预热(就是使用学习率先增后降的方式)是一种防止训练 初期发生梯度爆炸的一种策略,预热学习率的方式对很多物体定 位算法都比较重要,例如YOLOv3在迭代的最初阶段,大多数预 测中sigmoid分类分数会被初始化为0.5,偏置为0,所以开始阶段 梯度会比较大。
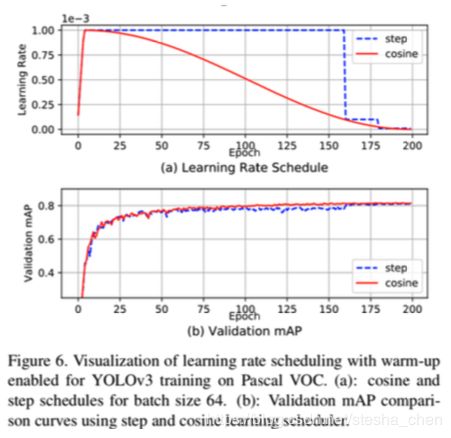
训练的时候使用余弦函数处理学习率和使用合适的预热学习率方式都会提升网络的准确率。图6是实验结果,可以看到使用余弦 函数的方式比使用step下降梯度的方式要好,可以更快的适应学习率变化。

技术细节五:同步batch normalization
近几年,由于大量的计算需求导致训练环境会使用多GPU的方式去加速训练。但是在多GPU上使用batch normalization是值得关 注的。虽然在每块GPU上独立使用BN会加快训练速度,但是不可避免的会减少batch size并且在计算期间导致统计数据略有不 同,而使performance下降。对于batch size足够大的情况是不会有这个问题的,但是对于batch size小的情况损害很大。(备注8)论文提出的在物体定位中同步batch normalization的方法被证明非常重要。同步方式看下图
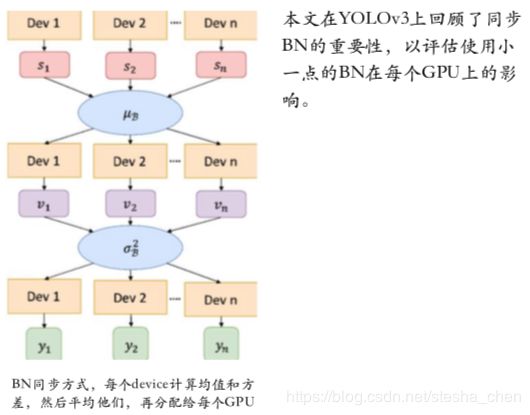
备注8:C.Peng,T.Xiao,Z.Li,Y.Jiang,X.Zhang,K.Jia,G.Yu,and J. Sun. Megdet: A large mini-batch object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6181–6189, 2018
技术细节六:使用随机尺寸训练one-stage网络
自然图片的尺寸是各种各样的,但是为了适应内存的限制, 使用更简单的batch,很多one-stage的物体定位网络都是使用固定尺寸进行训练。为了降低过拟合,并且提高网络的泛化能力,可以使用随机尺寸进行训练。对长宽可以做一些随 机的乘或者除运算,比如YOLOv3训练使用的长宽为
H = W ∈ {320,352,384,416,448,480,512,544,576,608}
实验
为了验证比较这些技巧对网络的提升,选择了YOLOv3和Faster RCNN作为one-stage和multi-stage定位网络的代表。为了适应大 规模的训练任务,使用Pascal VOC数据集进行精调评估,COCO 数据集用于验证整体性能增益和泛化能力。
Pascal VOC数据集
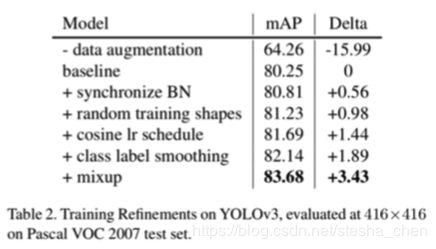
使用了VOC2007和2012的trainval进行训练,使用VOC2007的test进行验证。对于YOLOv3如果开启了随机尺寸进行训练的功能, 那么输入尺寸会在320x320到608x608之间间隔32pixel的值里面随机选择,否则就使用固定尺寸416x416。Faster RCNN可以任意尺寸作为输入,但为了减少内存消耗,把图片短边压缩到600pixel,并且保证长边少于1000pixel。训练和验证使用同样的 数据预处理,另外还有0.5的可能性对图片进行水平翻转。从右边的表2和3可以看到两个网络的效果。YOLOv3通过这一系列的 技巧可以带来3.43个百分点的提升,Faster RCNN使用的技巧少 一点,但是也可以带来类似百分点的提升。有一个现象,数据增 强对one-stage网络非常有用,对multi-stage网络用处不大,因为one-stage网络更缺少空间多样性。
MS COCO数据集
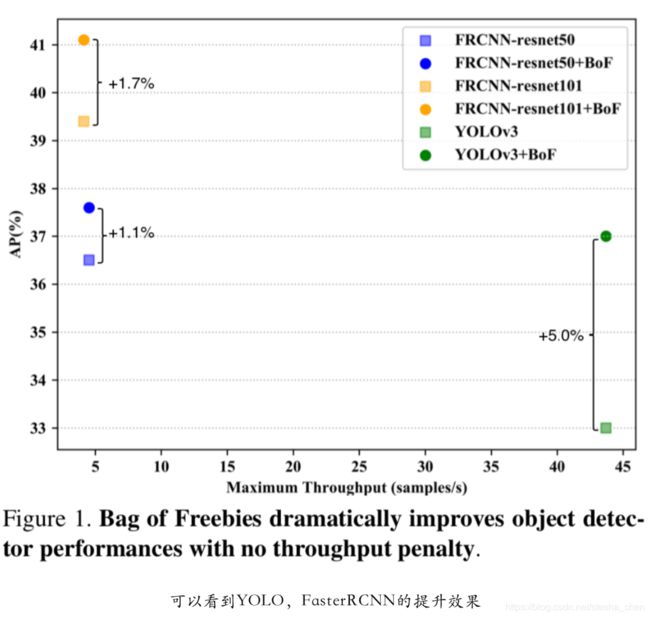
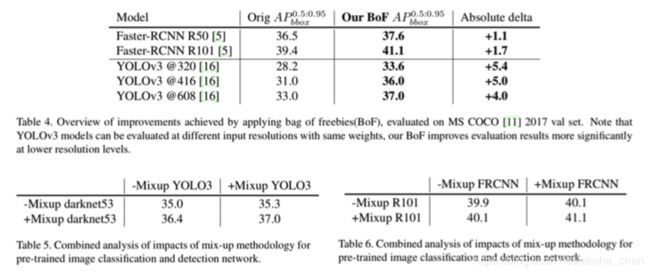
COCO数据集比VOC数据集复杂很多,使用COCO数据集验证使用本文中提到的技巧后对网络的提升。与训练VOC网络时候的设 置类似,但是Faster RCNN的输入尺寸是800x1300,是为了更好的处理小物体。结果见表4,Faster RCNN使用 Resnet50和Resnet101分别有1.1和1.7个百分点的提升,YOLOv3有 高达4个点以上的提升。并且这些技巧都不会影响预测时候的计算消耗。
不同阶段使用mixup的影响
mixup可以用在两个阶段,1.预训练分类网络backbone的 时候;2.训练定位网络的时候使用视觉一致的mixup。作者实验了YOLOv3使用darknet-53做为backbone和Faster RCNN使用ResNet101做为backbone。从表5和6可以看到结果,表明在两个阶段都使用mixup可以达 到1+1>2的效果。

结论
本文提出了一些技巧,可以在不增加额外inference开销的情况下提升模型性能。建议在未来无论是multi-stage还是one-stage都可以 广泛使用这些技巧。