numpy
一,NumPy 介绍
1,什么是 NumPy?
NumPy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
NumPy包的核心是 ndarray 对象。它封装了python原生的同数据类型的 n 维数组,为了保证其性能优良,其中有许多操作都是代码在本地进行编译后执行的。
NumPy数组 和 原生Python Array(数组)之间有几个重要的区别:
- NumPy 数组在创建时具有固定的大小,与Python的原生数组对象(可以动态增长)不同。更改ndarray的大小将创建一个新数组并删除原来的数组。
- NumPy 数组中的元素都需要具有相同的数据类型,因此在内存中的大小相同。 例外情况:Python的原生数组里包含了NumPy的对象的时候,这种情况下就允许不同大小元素的数组。
- NumPy 数组有助于对大量数据进行高级数学和其他类型的操作。通常,这些操作的执行效率更高,比使用Python原生数组的代码更少。
- 越来越多的基于Python的科学和数学软件包使用NumPy数组; 虽然这些工具通常都支持Python的原生数组作为参数,但它们在处理之前会还是会将输入的数组转换为NumPy的数组,而且也通常输出为NumPy数组。换句话说,为了高效地使用当今科学/数学基于Python的工具(大部分的科学计算工具),你只知道如何使用Python的原生数组类型是不够的 - 还需要知道如何使用 NumPy 数组。
关于数组大小和速度的要点在科学计算中尤为重要。举一个简单的例子,考虑将1维数组中的每个元素与相同长度的另一个序列中的相应元素相乘的情况。如果数据存储在两个Python 列表 a和 b 中,我们可以迭代每个元素,如下所示:
c = []
for i in range(len(a)):
c.append(a[i]*b[i])
确实符合我们的要求,但如果a和b每一个都包含数以百万计的数字,我们会付出Python中循环的效率低下的代价。我们可以通过在C中写入以下代码,更快地完成相同的任务(为了清楚起见,我们忽略了变量声明和初始化,内存分配等)。
for (i = 0; i < rows; i++): {
c[i] = a[i]*b[i];
}
这节省了解释Python代码和操作Python对象所涉及的所有开销,但牺牲了用Python编写代码所带来的好处。此外,编码工作需要增加的维度,我们的数据。例如,对于二维数组,C代码(如前所述)会扩展为这样:
for (i = 0; i < rows; i++): {
for (j = 0; j < columns; j++): {
c[i][j] = a[i][j]*b[i][j];
}
}
NumPy 为我们提供了两全其美的解决方案:当涉及到 ndarray 时,逐个元素的操作是“默认模式”,但逐个元素的操作由预编译的C代码快速执行。在NumPy中:
c = a * b
以近C速度执行前面的示例所做的事情,但是我们期望基于Python的代码具有简单性。的确,NumPy的语法更为简单!最后一个例子说明了NumPy的两个特征,它们是NumPy的大部分功能的基础:矢量化和广播。
2,为什么 NumPy 这么快?
矢量化描述了代码中没有任何显式的循环,索引等 - 这些当然是预编译的C代码中“幕后”优化的结果。矢量化代码有许多优点,其中包括:
- 矢量化代码更简洁,更易于阅读
- 更少的代码行通常意味着更少的错误
- 代码更接近于标准的数学符号(通常,更容易正确编码数学结构)
- 矢量化导致产生更多 “Pythonic” 代码。如果没有矢量化,我们的代码就会被低效且难以阅读的
for循环所困扰。
广播是用于描述操作的隐式逐元素行为的术语; 一般来说,在NumPy中,所有操作,不仅仅是算术运算,而是逻辑,位,功能等,都以这种隐式的逐元素方式表现,即它们进行广播。此外,在上面的例子中,a并且b可以是相同形状的多维数组,或者标量和数组,或者甚至是具有不同形状的两个数组,条件是较小的数组可以“扩展”到更大的形状。结果广播明确无误的方式。有关广播的详细“规则”,请参阅numpy.doc.broadcasting。
3,还有谁在使用 NumPy?
NumPy完全支持面向对象的方法,我们再夸奖一次 ndarray 。 我们知道 ndarray 是一个类,拥有许多方法和属性。它的许多方法都由最外层的NumPy命名空间中的函数镜像,允许程序员在他们喜欢的范例中进行编码。这种灵活性使NumPy数组方言和NumPy ndarray 类成为在Python中使用的多维数据交换的首选对象。
二,快速入门教程
1,先决条件先决条件
在阅读本教程之前,你应该了解一些Python的基础知识。
如果您希望使用本教程中的示例,则还必须在计算机上安装某些软件。有关说明,请参阅。
2,基础知识
NumPy的主要对象是同构多维数组。它是一个元素表(通常是数字),所有类型都相同,由非负整数元组索引。在NumPy维度中称为轴。
例如,3D空间中的点的坐标[1, 2, 1]具有一个轴。该轴有3个元素,所以我们说它的长度为3.在下图所示的例子中,数组有2个轴。第一轴的长度为2,第二轴的长度为3。
[[ 1., 0., 0.],
[ 0., 1., 2.]]
NumPy的数组类被调用ndarray。它也被别名所知 array。请注意,numpy.array这与标准Python库类不同array.array,后者只处理一维数组并提供较少的功能。ndarray对象更重要的属性是:
- ndarray.ndim - 数组的轴(维度)的个数。在Python世界中,维度的数量被称为rank。
- ndarray.shape - 数组的维度。这是一个整数的元组,表示每个维度中数组的大小。对于有 n行和 m 列的矩阵,
shape将是(n,m)。因此,shape元组的长度就是rank或维度的个数ndim。 - ndarray.size - 数组元素的总数。这等于
shape的元素的乘积。 - ndarray.dtype - 一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。例如numpy.int32、numpy.int16和numpy.float64。
- ndarray.itemsize - 数组中每个元素的字节大小。例如,元素为
float64类型的数组的itemsize为8(=64/8),而complex32类型的数组的itemsize为4(=32/8)。它等于ndarray.dtype.itemsize。 - ndarray.data - 该缓冲区包含数组的实际元素。通常,我们不需要使用此属性,因为我们将使用索引访问数组中的元素。
一个例子
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
<type 'numpy.ndarray'>
数组创建
有几种方法可以创建数组。
例如,你可以使用array函数从常规Python列表或元组中创建数组。得到的数组的类型是从Python列表中元素的类型推导出来的。
>>> import numpy as np
>>> a = np.array([2,3,4])
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int64')
>>> b = np.array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')
一个常见的错误,就是调用array的时候传入多个数字参数,而不是提供单个数字的列表类型作为参数。
>>> a = np.array(1,2,3,4) # WRONG
>>> a = np.array([1,2,3,4]) # RIGHT
array 还可以将序列的序列转换成二维数组,将序列的序列的序列转换成三维数组,等等。
>>> b = np.array([(1.5,2,3), (4,5,6)])
>>> b
array([[ 1.5, 2. , 3. ],
[ 4. , 5. , 6. ]])
也可以在创建时显式指定数组的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])
通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。这就减少了数组增长的必要,因为数组增长的操作花费很大。
函数zeros创建一个由0组成的数组,函数 ones创建一个完整的数组,函数empty 创建一个数组,其初始内容是随机的,取决于内存的状态。默认情况下,创建的数组的dtype是 float64类型的。
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])
为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
>>> np.arange( 10, 30, 5 )
array([10, 15, 20, 25])
>>> np.arange( 0, 2, 0.3 ) # it accepts float arguments
array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
当arange与浮点参数一起使用时,由于有限的浮点精度,通常不可能预测所获得的元素的数量。出于这个原因,通常最好使用linspace函数来接收我们想要的元素数量的函数,而不是步长(step):
>>> from numpy import pi
>>> np.linspace( 0, 2, 9 ) # 9 numbers from 0 to 2
array([ 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ])
>>> x = np.linspace( 0, 2*pi, 100 ) # useful to evaluate function at lots of points
>>> f = np.sin(x)
另见这些API
array, zeros, zeros_like, ones, ones_like, empty,empty_like, arange, linspace, numpy.random.mtrand.RandomState.rand, numpy.random.mtrand.RandomState.randn, fromfunction, fromfile
打印数组打印数组
当您打印数组时,NumPy以与嵌套列表类似的方式显示它,但具有以下布局:
- 最后一个轴从左到右打印,
- 倒数第二个从上到下打印,
- 其余部分也从上到下打印,每个切片用空行分隔。
然后将一维数组打印为行,将二维数据打印为矩阵,将三维数据打印为矩数组表。
>>> a = np.arange(6) # 1d array
>>> print(a)
[0 1 2 3 4 5]
>>>
>>> b = np.arange(12).reshape(4,3) # 2d array
>>> print(b)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
>>>
>>> c = np.arange(24).reshape(2,3,4) # 3d array
>>> print(c)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
有关 reshape 的详情,请参阅下文。
如果数组太大而无法打印,NumPy会自动跳过数组的中心部分并仅打印角点:
>>> print(np.arange(10000))
[ 0 1 2 ..., 9997 9998 9999]
>>>
>>> print(np.arange(10000).reshape(100,100))
[[ 0 1 2 ..., 97 98 99]
[ 100 101 102 ..., 197 198 199]
[ 200 201 202 ..., 297 298 299]
...,
[9700 9701 9702 ..., 9797 9798 9799]
[9800 9801 9802 ..., 9897 9898 9899]
[9900 9901 9902 ..., 9997 9998 9999]]
要禁用此行为并强制NumPy打印整个数组,可以使用更改打印选项set_printoptions。
>>> np.set_printoptions(threshold=sys.maxsize) # sys module should be imported
基本操作
数组上的算术运算符会应用到元素级别。下面是创建一个新数组并填充结果的示例:
>>> a = np.array( [20,30,40,50] )
>>> b = np.arange( 4 )
>>> b
array([0, 1, 2, 3])
>>> c = a-b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10*np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a<35
array([ True, True, False, False])
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行:
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])
某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'
当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'
许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray类的方法实现的。
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595
默认情况下,这些操作适用于数组,就像它是一个数字列表一样,无论其形状如何。但是,通过指定axis 参数,您可以沿数组的指定轴应用操作:
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # sum of each column
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # min of each row
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
通函数
NumPy提供熟悉的数学函数,例如sin,cos和exp。在NumPy中,这些被称为“通函数”(ufunc)。在NumPy中,这些函数在数组上按元素进行运算,产生一个数组作为输出。
>>> B = np.arange(3)
>>> B
array([0, 1, 2])
>>> np.exp(B)
array([ 1. , 2.71828183, 7.3890561 ])
>>> np.sqrt(B)
array([ 0. , 1. , 1.41421356])
>>> C = np.array([2., -1., 4.])
>>> np.add(B, C)
array([ 2., 0., 6.])
另见这些通函数
all, any, apply_along_axis, argmax, argmin, argsort,average, bincount, ceil, clip, conj, corrcoef, cov, cross, cumprod, cumsum, diff, dot, floor, inner, INV , lexsort, max, maximum, mean, median, min,minimum, nonzero, outer, prod, re, round, sort,std, sum, trace, transpose, var, vdot, vectorize, where
索引、切片和迭代
一维的数组可以进行索引、切片和迭代操作的,就像 列表 和其他Python序列类型一样。
>>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # equivalent to a[0:6:2] = -1000; from start to position 6, exclusive, set every 2nd element to -1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, 216, 343, 512, 729])
>>> a[ : :-1] # reversed a
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
>>> for i in a:
... print(i**(1/3.))
...
nan
1.0
nan
3.0
nan
5.0
6.0
7.0
8.0
9.0
多维的数组每个轴可以有一个索引。这些索引以逗号分隔的元组给出:
>>> def f(x,y):
... return 10*x+y
...
>>> b = np.fromfunction(f,(5,4),dtype=int)
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
当提供的索引少于轴的数量时,缺失的索引被认为是完整的切片:
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])
b[i] 方括号中的表达式 i 被视为后面紧跟着 : 的多个实例,用于表示剩余轴。NumPy也允许你使用三个点写为 b[i,...]。
三个点( ... )表示产生完整索引元组所需的冒号。例如,如果 x 是rank为的5数组(即,它具有5个轴),则:
x[1,2,...]相当于x[1,2,:,:,:],x[...,3]等效于x[:,:,:,:,3]x[4,...,5,:]等效于x[4,:,:,5,:]。
>>> c = np.array( [[[ 0, 1, 2], # a 3D array (two stacked 2D arrays)
... [ 10, 12, 13]],
... [[100,101,102],
... [110,112,113]]])
>>> c.shape
(2, 2, 3)
>>> c[1,...] # same as c[1,:,:] or c[1]
array([[100, 101, 102],
[110, 112, 113]])
>>> c[...,2] # same as c[:,:,2]
array([[ 2, 13],
[102, 113]])
对多维数组进行 迭代(Iterating) 是相对于第一个轴完成的:
>>> for row in b:
... print(row)
...
[0 1 2 3]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]
[40 41 42 43]
但是,如果想要对数组中的每个元素执行操作,可以使用flat属性,该属性是数组的所有元素的迭代器:
>>> for element in b.flat:
... print(element)
...
0
1
2
3
10
11
12
13
20
21
22
23
30
31
32
33
40
41
42
43
另见
Indexing, Indexing (reference), newaxis, ndenumerate, indices
3,形状操纵
改变数组的形状
一个数组的形状是由每个轴的元素数量决定的:
>>> a = np.floor(10*np.random.random((3,4)))
>>> a
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
>>> a.shape
(3, 4)
可以使用各种命令更改数组的形状。请注意,以下三个命令都返回一个修改后的数组,但不会更改原始数组:
>>> a.ravel() # returns the array, flattened
array([ 2., 8., 0., 6., 4., 5., 1., 1., 8., 9., 3., 6.])
>>> a.reshape(6,2) # returns the array with a modified shape
array([[ 2., 8.],
[ 0., 6.],
[ 4., 5.],
[ 1., 1.],
[ 8., 9.],
[ 3., 6.]])
>>> a.T # returns the array, transposed
array([[ 2., 4., 8.],
[ 8., 5., 9.],
[ 0., 1., 3.],
[ 6., 1., 6.]])
>>> a.T.shape
(4, 3)
>>> a.shape
(3, 4)
由 ravel() 产生的数组中元素的顺序通常是“C风格”,也就是说,最右边的索引“变化最快”,因此[0,0]之后的元素是[0,1] 。如果将数组重新整形为其他形状,则该数组将被视为“C风格”。NumPy通常创建按此顺序存储的数组,因此 ravel() 通常不需要复制其参数,但如果数组是通过获取另一个数组的切片或使用不常见的选项创建的,则可能需要复制它。还可以使用可选参数指示函数 ravel() 和 reshape(),以使用FORTRAN样式的数组,其中最左边的索引变化最快。
该reshape函数返回带有修改形状的参数,而该 ndarray.resize方法会修改数组本身:
>>> a
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
>>> a.resize((2,6))
>>> a
array([[ 2., 8., 0., 6., 4., 5.],
[ 1., 1., 8., 9., 3., 6.]])
如果在 reshape 操作中将 size 指定为-1,则会自动计算其他的 size 大小:
>>> a.reshape(3,-1)
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
另见
ndarray.shape, reshape, resize, ravel
将不同数组堆叠在一起
几个数组可以沿不同的轴堆叠在一起,例如:
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])
该函数将column_stack 1D数组作为列堆叠到2D数组中。它仅相当于 hstack2D数组:
>>> from numpy import newaxis
>>> np.column_stack((a,b)) # with 2D arrays
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])
另一方面,该函数ma.row_stack等效vstack 于任何输入数组。通常,对于具有两个以上维度的数组, hstack沿其第二轴vstack堆叠,沿其第一轴堆叠,并concatenate 允许可选参数给出连接应发生的轴的编号。
注意
在复杂的情况下,r_和c c_于通过沿一个轴堆叠数字来创建数组很有用。它们允许使用范围操作符(“:”)。
>>> np.r_[1:4,0,4]
array([1, 2, 3, 0, 4])
与数组一起用作参数时, r_ 和 c_ 在默认行为上类似于 vstack 和 hstack ,但允许使用可选参数给出要连接的轴的编号。
另见
hstack, vstack, column_stack, concatenate, c_, r_
将一个数组拆分成几个较小的数组
使用hsplit,可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
vsplit沿垂直轴分割,并array_split允许指定要分割的轴。
4,拷贝和视图
当计算和操作数组时,有时会将数据复制到新数组中,有时则不会。这通常是初学者混淆的根源。有三种情况:
完全不复制
简单分配不会复制数组对象或其数据。
>>> a = np.arange(12)
>>> b = a # no new object is created
>>> b is a # a and b are two names for the same ndarray object
True
>>> b.shape = 3,4 # changes the shape of a
>>> a.shape
(3, 4)
Python将可变对象作为引用传递,因此函数调用不会复制。
>>> def f(x):
... print(id(x))
...
>>> id(a) # id is a unique identifier of an object
148293216
>>> f(a)
148293216
视图或浅拷贝
不同的数组对象可以共享相同的数据。该view方法创建一个查看相同数据的新数组对象。
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c is a view of the data owned by a
True
>>> c.flags.owndata
False
>>>
>>> c.shape = 2,6 # a's shape doesn't change
>>> a.shape
(3, 4)
>>> c[0,4] = 1234 # a's data changes
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])
切片数组会返回一个视图:
>>> s = a[ : , 1:3] # spaces added for clarity; could also be written "s = a[:,1:3]"
>>> s[:] = 10 # s[:] is a view of s. Note the difference between s=10 and s[:]=10
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
深拷贝
该copy方法生成数组及其数据的完整副本。
>>> d = a.copy() # a new array object with new data is created
>>> d is a
False
>>> d.base is a # d doesn't share anything with a
False
>>> d[0,0] = 9999
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
有时,如果不再需要原始数组,则应在切片后调用 copy。例如,假设a是一个巨大的中间结果,最终结果b只包含a的一小部分,那么在用切片构造b时应该做一个深拷贝:
>>> a = np.arange(int(1e8))
>>> b = a[:100].copy()
>>> del a # the memory of ``a`` can be released.
如果改为使用 b = a[:100],则 a 由 b 引用,并且即使执行 del a 也会在内存中持久存在。
功能和方法概述
以下是按类别排序的一些有用的NumPy函数和方法名称的列表。有关完整列表,请参阅参考手册里的常用API。
- 数组的创建(Array Creation) - arange, array, copy, empty, empty_like, eye, fromfile, fromfunction, identity, linspace, logspace, mgrid, ogrid, ones, ones_like, zeros, zeros_like
- 转换和变换(Conversions) - ndarray.astype, atleast_1d, atleast_2d, atleast_3d, mat
- 操纵术(Manipulations) - array_split, column_stack, concatenate, diagonal, dsplit, dstack, hsplit, hstack, ndarray.item, newaxis, ravel, repeat, reshape, resize, squeeze, swapaxes, take, transpose, vsplit, vstack
- 询问(Questions) - all, any, nonzero, where,
- 顺序(Ordering) - argmax, argmin, argsort, max, min, ptp, searchsorted, sort
- 操作(Operations) - choose, compress, cumprod, cumsum, inner, ndarray.fill, imag, prod, put, putmask, real, sum
- 基本统计(Basic Statistics) - cov, mean, std, var
- 基本线性代数(Basic Linear Algebra) - cross, dot, outer, linalg.svd, vdot
5,Less 基础
广播(Broadcasting)规则
广播允许通用功能以有意义的方式处理不具有完全相同形状的输入。
广播的第一个规则是,如果所有输入数组不具有相同数量的维度,则将“1”重复地预先添加到较小数组的形状,直到所有数组具有相同数量的维度。
广播的第二个规则确保沿特定维度的大小为1的数组表现为具有沿该维度具有最大形状的数组的大小。假定数组元素的值沿着“广播”数组的那个维度是相同的。
应用广播规则后,所有数组的大小必须匹配。更多细节可以在广播中找到。
6,花式索引和索引技巧
NumPy提供比常规Python序列更多的索引功能。除了通过整数和切片进行索引之外,正如我们之前看到的,数组可以由整数数组和布尔数组索引。
使用索引数组进行索引
>>> a = np.arange(12)**2 # the first 12 square numbers
>>> i = np.array( [ 1,1,3,8,5 ] ) # an array of indices
>>> a[i] # the elements of a at the positions i
array([ 1, 1, 9, 64, 25])
>>>
>>> j = np.array( [ [ 3, 4], [ 9, 7 ] ] ) # a bidimensional array of indices
>>> a[j] # the same shape as j
array([[ 9, 16],
[81, 49]])
当索引数组a是多维的时,单个索引数组指的是第一个维度a。以下示例通过使用调色板将标签图像转换为彩色图像来显示此行为。
>>> palette = np.array( [ [0,0,0], # black
... [255,0,0], # red
... [0,255,0], # green
... [0,0,255], # blue
... [255,255,255] ] ) # white
>>> image = np.array( [ [ 0, 1, 2, 0 ], # each value corresponds to a color in the palette
... [ 0, 3, 4, 0 ] ] )
>>> palette[image] # the (2,4,3) color image
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])
我们还可以为多个维度提供索引。每个维度的索引数组必须具有相同的形状。
>>> a = np.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> i = np.array( [ [0,1], # indices for the first dim of a
... [1,2] ] )
>>> j = np.array( [ [2,1], # indices for the second dim
... [3,3] ] )
>>>
>>> a[i,j] # i and j must have equal shape
array([[ 2, 5],
[ 7, 11]])
>>>
>>> a[i,2]
array([[ 2, 6],
[ 6, 10]])
>>>
>>> a[:,j] # i.e., a[ : , j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])
当然,我们可以按顺序(比如列表)放入i,j然后使用列表进行索引。
>>> l = [i,j]
>>> a[l] # equivalent to a[i,j]
array([[ 2, 5],
[ 7, 11]])
但是,我们不能通过放入i和j放入数组来实现这一点,因为这个数组将被解释为索引a的第一个维度。
>>> s = np.array( [i,j] )
>>> a[s] # not what we want
Traceback (most recent call last):
File "" , line 1, in ?
IndexError: index (3) out of range (0<=index<=2) in dimension 0
>>>
>>> a[tuple(s)] # same as a[i,j]
array([[ 2, 5],
[ 7, 11]])
使用数组索引的另一个常见用法是搜索与时间相关的系列的最大值:
>>> time = np.linspace(20, 145, 5) # time scale
>>> data = np.sin(np.arange(20)).reshape(5,4) # 4 time-dependent series
>>> time
array([ 20. , 51.25, 82.5 , 113.75, 145. ])
>>> data
array([[ 0. , 0.84147098, 0.90929743, 0.14112001],
[-0.7568025 , -0.95892427, -0.2794155 , 0.6569866 ],
[ 0.98935825, 0.41211849, -0.54402111, -0.99999021],
[-0.53657292, 0.42016704, 0.99060736, 0.65028784],
[-0.28790332, -0.96139749, -0.75098725, 0.14987721]])
>>>
>>> ind = data.argmax(axis=0) # index of the maxima for each series
>>> ind
array([2, 0, 3, 1])
>>>
>>> time_max = time[ind] # times corresponding to the maxima
>>>
>>> data_max = data[ind, range(data.shape[1])] # => data[ind[0],0], data[ind[1],1]...
>>>
>>> time_max
array([ 82.5 , 20. , 113.75, 51.25])
>>> data_max
array([ 0.98935825, 0.84147098, 0.99060736, 0.6569866 ])
>>>
>>> np.all(data_max == data.max(axis=0))
True
您还可以使用数组索引作为分配给的目标:
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[[1,3,4]] = 0
>>> a
array([0, 0, 2, 0, 0])
但是,当索引列表包含重复时,分配会多次完成,留下最后一个值:
>>> a = np.arange(5)
>>> a[[0,0,2]]=[1,2,3]
>>> a
array([2, 1, 3, 3, 4])
这是合理的,但请注意是否要使用Python的 +=构造,因为它可能不会按预期执行:
>>> a = np.arange(5)
>>> a[[0,0,2]]+=1
>>> a
array([1, 1, 3, 3, 4])
即使0在索引列表中出现两次,第0个元素也只增加一次。这是因为Python要求“a + = 1”等同于“a = a + 1”。
使用布尔数组进行索引
当我们使用(整数)索引数组索引数组时,我们提供了要选择的索引列表。使用布尔索引,方法是不同的; 我们明确地选择我们想要的数组中的哪些项目以及我们不需要的项目。
人们可以想到的最自然的布尔索引方法是使用与原始数组具有 相同形状的 布尔数组:
>>> a = np.arange(12).reshape(3,4)
>>> b = a > 4
>>> b # b is a boolean with a's shape
array([[False, False, False, False],
[False, True, True, True],
[ True, True, True, True]])
>>> a[b] # 1d array with the selected elements
array([ 5, 6, 7, 8, 9, 10, 11])
此属性在分配中非常有用:
>>> a[b] = 0 # All elements of 'a' higher than 4 become 0
>>> a
array([[0, 1, 2, 3],
[4, 0, 0, 0],
[0, 0, 0, 0]])
您可以查看以下示例,了解如何使用布尔索引生成Mandelbrot集的图像:
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> def mandelbrot( h,w, maxit=20 ):
... """Returns an image of the Mandelbrot fractal of size (h,w)."""
... y,x = np.ogrid[ -1.4:1.4:h*1j, -2:0.8:w*1j ]
... c = x+y*1j
... z = c
... divtime = maxit + np.zeros(z.shape, dtype=int)
...
... for i in range(maxit):
... z = z**2 + c
... diverge = z*np.conj(z) > 2**2 # who is diverging
... div_now = diverge & (divtime==maxit) # who is diverging now
... divtime[div_now] = i # note when
... z[diverge] = 2 # avoid diverging too much
...
... return divtime
>>> plt.imshow(mandelbrot(400,400))
>>> plt.show()

使用布尔值进行索引的第二种方法更类似于整数索引; 对于数组的每个维度,我们给出一个1D布尔数组,选择我们想要的切片:
>>> a = np.arange(12).reshape(3,4)
>>> b1 = np.array([False,True,True]) # first dim selection
>>> b2 = np.array([True,False,True,False]) # second dim selection
>>>
>>> a[b1,:] # selecting rows
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[b1] # same thing
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[:,b2] # selecting columns
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
>>>
>>> a[b1,b2] # a weird thing to do
array([ 4, 10])
请注意,1D布尔数组的长度必须与要切片的尺寸(或轴)的长度一致。在前面的例子中,b1具有长度为3(的数目 的行 中a),和 b2(长度4)适合于索引的第二轴线(列) a。
ix_()函数
ix_函数可用于组合不同的向量,以便获得每个n-uplet的结果。例如,如果要计算从每个向量a,b和c中取得的所有三元组的所有a + b * c:
>>> a = np.array([2,3,4,5])
>>> b = np.array([8,5,4])
>>> c = np.array([5,4,6,8,3])
>>> ax,bx,cx = np.ix_(a,b,c)
>>> ax
array([[[2]],
[[3]],
[[4]],
[[5]]])
>>> bx
array([[[8],
[5],
[4]]])
>>> cx
array([[[5, 4, 6, 8, 3]]])
>>> ax.shape, bx.shape, cx.shape
((4, 1, 1), (1, 3, 1), (1, 1, 5))
>>> result = ax+bx*cx
>>> result
array([[[42, 34, 50, 66, 26],
[27, 22, 32, 42, 17],
[22, 18, 26, 34, 14]],
[[43, 35, 51, 67, 27],
[28, 23, 33, 43, 18],
[23, 19, 27, 35, 15]],
[[44, 36, 52, 68, 28],
[29, 24, 34, 44, 19],
[24, 20, 28, 36, 16]],
[[45, 37, 53, 69, 29],
[30, 25, 35, 45, 20],
[25, 21, 29, 37, 17]]])
>>> result[3,2,4]
17
>>> a[3]+b[2]*c[4]
17
您还可以按如下方式实现reduce:
>>> def ufunc_reduce(ufct, *vectors):
... vs = np.ix_(*vectors)
... r = ufct.identity
... for v in vs:
... r = ufct(r,v)
... return r
然后将其用作:
>>> ufunc_reduce(np.add,a,b,c)
array([[[15, 14, 16, 18, 13],
[12, 11, 13, 15, 10],
[11, 10, 12, 14, 9]],
[[16, 15, 17, 19, 14],
[13, 12, 14, 16, 11],
[12, 11, 13, 15, 10]],
[[17, 16, 18, 20, 15],
[14, 13, 15, 17, 12],
[13, 12, 14, 16, 11]],
[[18, 17, 19, 21, 16],
[15, 14, 16, 18, 13],
[14, 13, 15, 17, 12]]])
与普通的ufunc.reduce相比,这个版本的reduce的优点是它利用了广播规则 ,以避免创建一个参数数组,输出的大小乘以向量的数量。
使用字符串建立索引
请参见结构化数组。
7,线性代数
工作正在进行中。这里包括基本线性代数。
简单数组操作
有关更多信息,请参阅numpy文件夹中的linalg.py.
>>> import numpy as np
>>> a = np.array([[1.0, 2.0], [3.0, 4.0]])
>>> print(a)
[[ 1. 2.]
[ 3. 4.]]
>>> a.transpose()
array([[ 1., 3.],
[ 2., 4.]])
>>> np.linalg.inv(a)
array([[-2. , 1. ],
[ 1.5, -0.5]])
>>> u = np.eye(2) # unit 2x2 matrix; "eye" represents "I"
>>> u
array([[ 1., 0.],
[ 0., 1.]])
>>> j = np.array([[0.0, -1.0], [1.0, 0.0]])
>>> j @ j # matrix product
array([[-1., 0.],
[ 0., -1.]])
>>> np.trace(u) # trace
2.0
>>> y = np.array([[5.], [7.]])
>>> np.linalg.solve(a, y)
array([[-3.],
[ 4.]])
>>> np.linalg.eig(j)
(array([ 0.+1.j, 0.-1.j]), array([[ 0.70710678+0.j , 0.70710678-0.j ],
[ 0.00000000-0.70710678j, 0.00000000+0.70710678j]]))
Parameters:
square matrix
Returns
The eigenvalues, each repeated according to its multiplicity.
The normalized (unit "length") eigenvectors, such that the
column ``v[:,i]`` is the eigenvector corresponding to the
eigenvalue ``w[i]`` .
8,技巧和提示
这里我们列出一些简短有用的提示。
“自动”整形
要更改数组的尺寸,您可以省略其中一个尺寸,然后自动推导出尺寸:
>>> a = np.arange(30)
>>> a.shape = 2,-1,3 # -1 means "whatever is needed"
>>> a.shape
(2, 5, 3)
>>> a
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]],
[[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]]])
矢量堆叠
我们如何从同等大小的行向量列表中构造一个二维数组?在MATLAB这是很简单:如果x和y你只需要做两个相同长度的向量m=[x;y]。在此NumPy的通过功能的工作原理column_stack,dstack,hstack和vstack,视维在堆叠是必须要做的。例如:
x = np.arange(0,10,2) # x=([0,2,4,6,8])
y = np.arange(5) # y=([0,1,2,3,4])
m = np.vstack([x,y]) # m=([[0,2,4,6,8],
# [0,1,2,3,4]])
xy = np.hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])
这些函数背后的逻辑在两个以上的维度上可能很奇怪。
另见
与 Matlab 比较
直方图
histogram应用于数组的NumPy 函数返回一对向量:数组的直方图和bin的向量。注意:matplotlib还有一个构建直方图的功能(hist在Matlab中称为),与NumPy中的直方图不同。主要区别在于pylab.hist自动绘制直方图,而 numpy.histogram只生成数据。
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> # Build a vector of 10000 normal deviates with variance 0.5^2 and mean 2
>>> mu, sigma = 2, 0.5
>>> v = np.random.normal(mu,sigma,10000)
>>> # Plot a normalized histogram with 50 bins
>>> plt.hist(v, bins=50, density=1) # matplotlib version (plot)
>>> plt.show()
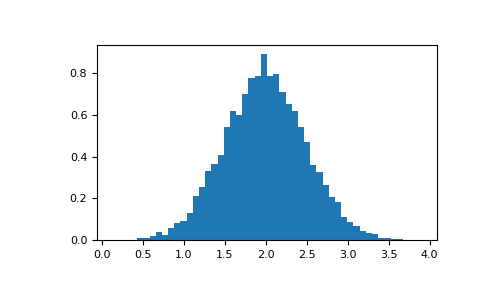
>>> # Compute the histogram with numpy and then plot it
>>> (n, bins) = np.histogram(v, bins=50, density=True) # NumPy version (no plot)
>>> plt.plot(.5*(bins[1:]+bins[:-1]), n)
>>> plt.show()
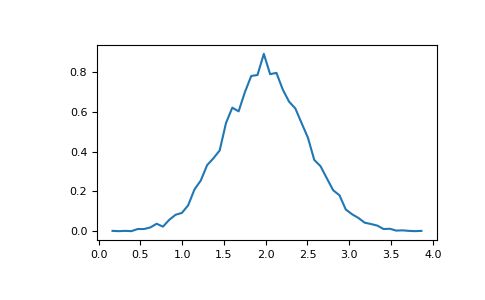
9,进一步阅读
- Python的教程
- NumPy参考
- SciPy教程
- SciPy讲义
- MATLAB,R,IDL,NumPy/SciPy 宝典
三,NumPy 基础知识
1,数据类型
(1)数组类型之间的转换
NumPy支持比Python更多种类的数字类型。本节显示了哪些可用,以及如何修改数组的数据类型。
支持的原始类型与 C 中的原始类型紧密相关:
| Numpy 的类型 | C 的类型 | 描述 |
|---|---|---|
| np.bool | bool | 存储为字节的布尔值(True或False) |
| np.byte | signed char | 平台定义 |
| np.ubyte | unsigned char | 平台定义 |
| np.short | short | 平台定义 |
| np.ushort | unsigned short | 平台定义 |
| np.intc | int | 平台定义 |
| np.uintc | unsigned int | 平台定义 |
| np.int_ | long | 平台定义 |
| np.uint | unsigned long | 平台定义 |
| np.longlong | long long | 平台定义 |
| np.ulonglong | unsigned long long | 平台定义 |
| np.half / np.float16 | 半精度浮点数:符号位,5位指数,10位尾数 | |
| np.single | float | 平台定义的单精度浮点数:通常为符号位,8位指数,23位尾数 |
| np.double | double | 平台定义的双精度浮点数:通常为符号位,11位指数,52位尾数。 |
| np.longdouble | long double | 平台定义的扩展精度浮点数 |
| np.csingle | float complex | 复数,由两个单精度浮点数(实部和虚部)表示 |
| np.cdouble | double complex | 复数,由两个双精度浮点数(实部和虚部)表示。 |
| np.clongdouble | long double complex | 复数,由两个扩展精度浮点数(实部和虚部)表示。 |
由于其中许多都具有依赖于平台的定义,因此提供了一组固定大小的别名:
| Numpy 的类型 | C 的类型 | 描述 |
|---|---|---|
| np.int8 | int8_t | 字节(-128到127) |
| np.int16 | int16_t | 整数(-32768至32767) |
| np.int32 | int32_t | 整数(-2147483648至2147483647) |
| np.int64 | int64_t | 整数(-9223372036854775808至9223372036854775807) |
| np.uint8 | uint8_t | 无符号整数(0到255) |
| np.uint16 | uint16_t | 无符号整数(0到65535) |
| np.uint32 | uint32_t | 无符号整数(0到4294967295) |
| np.uint64 | uint64_t | 无符号整数(0到18446744073709551615) |
| np.intp | intptr_t | 用于索引的整数,通常与索引相同 ssize_t |
| np.uintp | uintptr_t | 整数大到足以容纳指针 |
| np.float32 | float | |
| np.float64 / np.float_ | double | 请注意,这与内置python float的精度相匹配。 |
| np.complex64 | float complex | 复数,由两个32位浮点数(实数和虚数组件)表示 |
| np.complex128 / np.complex_ | double complex | 请注意,这与内置python 复合体的精度相匹配。 |
NumPy数值类型是dtype(数据类型)对象的实例,每个对象都具有独特的特征。使用后导入NumPy
import numpy as np
在dtypes可作为np.bool_,np.float32等等。
上表中未列出的高级类型将在结构化数组中进行探讨。
有5种基本数字类型表示布尔值(bool),整数(int),无符号整数(uint)浮点(浮点数)和复数。名称中带有数字的那些表示该类型的位大小(即,在内存中表示单个值需要多少位)。某些类型(例如 int 和 intp)具有不同的位,取决于平台(例如,32位与64位计算机)。在与寻址原始内存的低级代码(例如C或Fortran)连接时,应考虑这一点。
数据类型可以用作将python数转换为数组标量的函数(请参阅数组标量部分以获得解释),将python数字序列转换为该类型的数组,或作为许多numpy函数或方法接受的dtype关键字的参数。一些例子:
>>> import numpy as np
>>> x = np.float32(1.0)
>>> x
1.0
>>> y = np.int_([1,2,4])
>>> y
array([1, 2, 4])
>>> z = np.arange(3, dtype=np.uint8)
>>> z
array([0, 1, 2], dtype=uint8)
数组类型也可以通过字符代码引用,主要是为了保持与较旧的包(如Numeric)的向后兼容性。有些文档可能仍然引用这些,例如:
>>> np.array([1, 2, 3], dtype='f')
array([ 1., 2., 3.], dtype=float32)
我们建议使用dtype对象。
要转换数组的类型,请使用 .astype() 方法(首选)或类型本身作为函数。例如:
>>> z.astype(float)
array([ 0., 1., 2.])
>>> np.int8(z)
array([0, 1, 2], dtype=int8)
注意,在上面,我们使用 Python 的 float对象作为dtype。NumPy的人都知道int是指np.int_,bool意味着np.bool_,这float是np.float_和complex是np.complex_。其他数据类型没有Python等价物。
要确定数组的类型,请查看dtype属性:
>>> z.dtype
dtype('uint8')
dtype对象还包含有关类型的信息,例如其位宽和字节顺序。数据类型也可以间接用于查询类型的属性,例如它是否为整数:
>>> d = np.dtype(int)
>>> d
dtype('int32')
>>> np.issubdtype(d, np.integer)
True
>>> np.issubdtype(d, np.floating)
False
(2)数组标量
NumPy通常将数组元素作为数组标量返回(带有关联dtype的标量)。数组标量与Python标量不同,但在大多数情况下它们可以互换使用(主要的例外是早于v2.x的Python版本,其中整数数组标量不能作为列表和元组的索引)。有一些例外,例如当代码需要标量的非常特定的属性或者它特定地检查值是否是Python标量时。通常,存在的问题很容易被显式转换数组标量到Python标量,采用相应的Python类型的功能(例如,固定的int,float,complex,str,unicode)。
使用数组标量的主要优点是它们保留了数组类型(Python可能没有匹配的标量类型,例如int16)。因此,使用数组标量可确保数组和标量之间的相同行为,无论值是否在数组内。NumPy标量也有许多与数组相同的方法。
(3)溢出错误
当值需要比数据类型中的可用内存更多的内存时,NumPy数值类型的固定大小可能会导致溢出错误。例如,numpy.power对于64位整数正确计算 100 * 10 * 8,但对于32位整数给出1874919424(不正确)。
>>> np.power(100, 8, dtype=np.int64)
10000000000000000
>>> np.power(100, 8, dtype=np.int32)
1874919424
NumPy和Python整数类型的行为在整数溢出方面存在显着差异,并且可能会使用户期望NumPy整数的行为类似于Python int。与 NumPy 不同,Python 的大小int 是灵活的。这意味着Python整数可以扩展以容纳任何整数并且不会溢出。
NumPy分别提供numpy.iinfo并numpy.finfo验证NumPy整数和浮点值的最小值或最大值:
>>> np.iinfo(np.int) # Bounds of the default integer on this system.
iinfo(min=-9223372036854775808, max=9223372036854775807, dtype=int64)
>>> np.iinfo(np.int32) # Bounds of a 32-bit integer
iinfo(min=-2147483648, max=2147483647, dtype=int32)
>>> np.iinfo(np.int64) # Bounds of a 64-bit integer
iinfo(min=-9223372036854775808, max=9223372036854775807, dtype=int64)
如果64位整数仍然太小,则结果可能会转换为浮点数。浮点数提供了更大但不精确的可能值范围。
>>> np.power(100, 100, dtype=np.int64) # Incorrect even with 64-bit int
0
>>> np.power(100, 100, dtype=np.float64)
1e+200
(4)扩展精度
Python 的浮点数通常是64位浮点数,几乎等同于 np.float64 。在某些不寻常的情况下,使用更精确的浮点数可能会很有用。这在numpy中是否可行取决于硬件和开发环境:具体地说,x86机器提供80位精度的硬件浮点,虽然大多数C编译器提供这一点作为它们的 long double 类型,MSVC(Windows构建的标准)使 long double 等同于 double (64位)。NumPy使编译器的 long double 作为 np.longdouble 可用(而 np.clongdouble 用于复数)。您可以使用 np.finfo(np.longdouble) 找出 numpy提供了什么。
NumPy不提供比C的 long double 更高精度的dtype;特别是128位IEEE四精度数据类型(FORTRAN的 REAL*16 )不可用。
为了有效地进行内存的校准,np.longdouble通常以零位进行填充,即96或者128位, 哪个更有效率取决于硬件和开发环境;通常在32位系统上它们被填充到96位,而在64位系统上它们通常被填充到128位。np.longdouble被填充到系统默认值;为需要特定填充的用户提供了np.float96和np.float128。尽管它们的名称是这样叫的, 但是np.float96和np.float128只提供与np.longdouble一样的精度, 即大多数x86机器上的80位和标准Windows版本中的64位。
请注意,即使np.longdouble提供比python float更多的精度,也很容易失去额外的精度,因为python通常强制值通过float传递值。例如,%格式操作符要求将其参数转换为标准python类型,因此即使请求了许多小数位,也不可能保留扩展精度。使用值1 + np.finfo(np.longdouble).eps测试你的代码非常有用。
2,创建数组
1) 简介
创建数组有5种常规机制:
- 从其他Python结构(例如,列表,元组)转换
- numpy原生数组的创建(例如,arange、ones、zeros等)
- 从磁盘读取数组,无论是标准格式还是自定义格式
- 通过使用字符串或缓冲区从原始字节创建数组
- 使用特殊库函数(例如,random)
本节不包括复制,连接或以其他方式扩展或改变现有数组的方法。它也不会涵盖创建对象数组或结构化数组。这些都包含在他们自己的章节中。
2) 将Python array_like对象转换为Numpy数组
通常,在Python中排列成array-like结构的数值数据可以通过使用array()函数转换为数组。最明显的例子是列表和元组。有关其使用的详细信息,请参阅array()的文档。一些对象可能支持数组协议并允许以这种方式转换为数组。找出对象是否可以使用array()转换为一个数组numpy 数组的简单方法很简单,只要交互式试一下,看看它是否工作!(Python方式)。
例子:
>>> x = np.array([2,3,1,0])
>>> x = np.array([2, 3, 1, 0])
>>> x = np.array([[1,2.0],[0,0],(1+1j,3.)]) # note mix of tuple and lists,
and types
>>> x = np.array([[ 1.+0.j, 2.+0.j], [ 0.+0.j, 0.+0.j], [ 1.+1.j, 3.+0.j]])
3) Numpy原生数组的创建
Numpy内置了从头开始创建数组的函数:
zeros(shape)将创建一个用指定形状用0填充的数组。默认的dtype是float64。
>>> np.zeros((2, 3)) array([[ 0., 0., 0.], [ 0., 0., 0.]])
ones(shape)将创建一个用1个值填充的数组。它在所有其他方面与zeros相同。
arange()将创建具有有规律递增值的数组。检查文档字符串以获取有关可以使用的各种方式的完整信息。这里给出几个例子:
>>> np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(2, 10, dtype=np.float)
array([ 2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.arange(2, 3, 0.1)
array([ 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9])
请注意,关于用户应该注意的最后用法在arange文档字符串中有一些细微的描述。
linspace() 将创建具有指定数量元素的数组,并在指定的开始值和结束值之间平均间隔。例如:
>>> np.linspace(1., 4., 6)
array([ 1. , 1.6, 2.2, 2.8, 3.4, 4. ])
这个创建函数的优点是可以保证元素的数量以及开始和结束点,对于任意的开始,停止和步骤值,arange()通常不会这样做。
indices() 将创建一组数组(堆积为一个更高维的数组),每个维度一个,每个维度表示该维度中的变化。一个例子说明比口头描述要好得多:
>>> np.indices((3,3))
array([[[0, 0, 0], [1, 1, 1], [2, 2, 2]], [[0, 1, 2], [0, 1, 2], [0, 1, 2]]])
这对于评估常规网格上多个维度的功能特别有用。
4) 从磁盘读取数组
这大概是大数组创建的最常见情况。当然,细节很大程度上取决于磁盘上的数据格式,所以本节只能给出如何处理各种格式的一般指示。
标准二进制格式
各种字段都有数组数据的标准格式。下面列出了那些已知的Python库来读取它们并返回numpy数组(可能有其他可能读取并转换为numpy数组的其他数据,因此请检查最后一节)
HDF5: h5py
FITS: Astropy
无法直接读取但不易转换的格式示例是像PIL这样的库支持的格式(能够读取和写入许多图像格式,如jpg,png等)。
常见ASCII格式
逗号分隔值文件(CSV)被广泛使用(以及Excel等程序的导出和导入选项)。有很多方法可以在Python中阅读这些文件。python中有CSV函数和pylab函数(matplotlib的一部分)。
更多通用的ascii文件可以在scipy中使用io软件包读取。
自定义二进制格式
有各种各样的方法可以使用。如果文件具有相对简单的格式,那么可以编写一个简单的 I/O 库,并使用 numpy fromfile() 函数和 .tofile() 方法直接读取和写入numpy数组(尽管介意你的字节序)!如果存在一个读取数据的良好 C 或 C++ 库,可以使用各种技术来封装该库,但这肯定要做得更多,并且需要更多的高级知识才能与C或C++ 接口。
使用特殊库
有些库可用于生成特殊用途的数组,且无法列出所有的这些库。最常见的用途是随机使用许多数组生成函数,这些函数可以生成随机值数组,以及一些实用函数来生成特殊矩阵(例如对角线)。
3,NumPy与输入输出
使用genfromtxt导入数据
NumPy提供了几个函数来根据表格数据创建数组。我们将重点放在genfromtxt函数上。
In a nutshell, genfromtxt runs two main loops. 第一个循环以字符串序列转换文件的每一行。第二个循环将每个字符串转换为适当的数据类型。这种机制比单一循环慢,但提供了更多的灵活性。特别的, genfromtxt考虑到缺失值的情况, 其他更简单的方法如loadtxt无法做到这点.
注意 举例时,我们将使用以下约定:
>>> import numpy as np
>>> from io import BytesIO
定义输入
genfromtxt的唯一强制参数是数据的来源。它可以是一个字符串,一串字符串或一个生成器。如果提供了单个字符串,则假定它是本地或远程文件的名称,或者带有read方法的开放文件类对象,例如文件或StringIO.StringIO对象。如果提供了字符串列表或生成器返回字符串,则每个字符串在文件中被视为一行。当传递远程文件的URL时,该文件将自动下载到当前目录并打开。
识别的文件类型是文本文件和档案。目前,该功能可识别gzip和bz2(bzip2)档案。归档文件的类型由文件的扩展名决定:如果文件名以'.gz'结尾,则需要一个gzip归档文件;如果它以'bz2'结尾,则假定bzip2存档。
将行拆分为列
delimiter参数
一旦文件被定义并打开进行读取,genfromtxt会将每个非空行分割为一串字符串。 空的或注释的行只是略过。 delimiter关键字用于定义拆分应该如何进行。
通常,单个字符标记列之间的分隔。例如,逗号分隔文件(CSV)使用逗号(,)或分号(;)作为分隔符:
>>> data = "1, 2, 3\n4, 5, 6"
>>> np.genfromtxt(BytesIO(data), delimiter=",")
array([[ 1., 2., 3.],
[ 4., 5., 6.]])
另一个常用的分隔符是"\t",即制表符。但是,我们不限于单个字符,任何字符串都可以。默认情况下,genfromtxt假定delimiter=None,这意味着该行沿着空白区域(包括制表符)分割,并且连续的空白区域被视为单个空白区域。
或者,我们可能正在处理一个固定宽度的文件,其中列被定义为给定数量的字符。在这种情况下,我们需要将delimiter设置为单个整数(如果所有列的大小相同)或整数序列(如果列的大小可能不同):
>>> data = " 1 2 3\n 4 5 67\n890123 4"
>>> np.genfromtxt(BytesIO(data), delimiter=3)
array([[ 1., 2., 3.],
[ 4., 5., 67.],
[ 890., 123., 4.]])
>>> data = "123456789\n 4 7 9\n 4567 9"
>>> np.genfromtxt(BytesIO(data), delimiter=(4, 3, 2))
array([[ 1234., 567., 89.],
[ 4., 7., 9.],
[ 4., 567., 9.]])
autostrip参数
默认情况下,当一行被分解为一系列字符串时,单个条目不会被剥离前导空白或尾随空白。通过将可选参数autostrip设置为值True,可以覆盖此行为:
>>> data = "1, abc , 2\n 3, xxx, 4"
>>> # Without autostrip
>>> np.genfromtxt(BytesIO(data), delimiter=",", dtype="|S5")
array([['1', ' abc ', ' 2'],
['3', ' xxx', ' 4']],
dtype='|S5')
>>> # With autostrip
>>> np.genfromtxt(BytesIO(data), delimiter=",", dtype="|S5", autostrip=True)
array([['1', 'abc', '2'],
['3', 'xxx', '4']],
dtype='|S5')
comments参数
可选参数comments用于定义标记注释开始的字符串。默认情况下,genfromtxt假定comments='#'。评论标记可能发生在线上的任何地方。评论标记之后的任何字符都会被忽略:
>>> data = """#
... # Skip me !
... # Skip me too !
... 1, 2
... 3, 4
... 5, 6 #This is the third line of the data
... 7, 8
... # And here comes the last line
... 9, 0
... """
>>> np.genfromtxt(BytesIO(data), comments="#", delimiter=",")
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]
[ 9. 0.]]
注意
这种行为有一个明显的例外:如果可选参数names=True,则会检查第一条注释行的名称。
跳过直线并选择列
skip_header和skip_footer`参数
文件中存在标题可能会妨碍数据处理。在这种情况下,我们需要使用skip_header可选参数。此参数的值必须是一个整数,与执行任何其他操作之前在文件开头跳过的行数相对应。同样,我们可以使用skip_footer属性跳过文件的最后一行n,并给它一个n的值:
>>> data = "\n".join(str(i) for i in range(10))
>>> np.genfromtxt(BytesIO(data),)
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.genfromtxt(BytesIO(data),
... skip_header=3, skip_footer=5)
array([ 3., 4.])
默认情况下,skip_header=0和skip_footer=0,这意味着不会跳过任何行。
usecols`参数
在某些情况下,我们对数据的所有列不感兴趣,但只有其中的一小部分。我们可以用usecols参数选择要导入的列。该参数接受与要导入的列的索引相对应的单个整数或整数序列。请记住,按照惯例,第一列的索引为0。负整数的行为与常规Python负向索引相同。
例如,如果我们只想导入第一列和最后一列,我们可以使用usecols =(0, -1):
>>> data = "1 2 3\n4 5 6"
>>> np.genfromtxt(BytesIO(data), usecols=(0, -1))
array([[ 1., 3.],
[ 4., 6.]])
如果列有名称,我们也可以通过将它们的名称提供给usecols参数来选择要导入哪些列,可以将其作为字符串序列或逗号分隔字符串:
>>> data = "1 2 3\n4 5 6"
>>> np.genfromtxt(BytesIO(data),
... names="a, b, c", usecols=("a", "c"))
array([(1.0, 3.0), (4.0, 6.0)],
dtype=[('a', '), ('c', ')])
>>> np.genfromtxt(BytesIO(data),
... names="a, b, c", usecols=("a, c"))
array([(1.0, 3.0), (4.0, 6.0)],
dtype=[('a', '), ('c', ')])
选择数据的类型
控制我们从文件中读取的字符串序列如何转换为其他类型的主要方法是设置dtype参数。这个参数的可接受值是:
- 单一类型,如
dtype=float。除非使用names参数将名称与每个列关联(见下文),否则输出将是给定dtype的2D格式。请注意,dtype=float是genfromtxt的默认值。 - 一系列类型,如
dtype =(int, float, float)。 - 逗号分隔的字符串,例如
dtype="i4,f8,|S3"。 - 一个包含两个键
'names'和'formats'的字典。 - a sequence of tuples
(name, type), such asdtype=[('A', int), ('B', float)]. - 现有的
numpy.dtype对象。 - 特殊值
None。在这种情况下,列的类型将根据数据本身确定(见下文)。
在所有情况下,除了第一种情况,输出将是一个带有结构化dtype的一维数组。这个dtype与序列中的项目一样多。字段名称由names关键字定义。
当dtype=None时,每列的类型由其数据迭代确定。我们首先检查一个字符串是否可以转换为布尔值(也就是说,如果字符串在小写字母中匹配true或false);然后是否可以将其转换为整数,然后转换为浮点数,然后转换为复数并最终转换为字符串。通过修改StringConverter类的默认映射器可以更改此行为。
为方便起见,提供了dtype=None选项。但是,它明显比显式设置dtype要慢。
设置名称
names`参数
处理表格数据时的一种自然方法是为每列分配一个名称。如前所述,第一种可能性是使用明确的结构化dtype。
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=[(_, int) for _ in "abc"])
array([(1, 2, 3), (4, 5, 6)],
dtype=[('a', '), ('b', '), ('c', ')])
另一种更简单的可能性是将names关键字与一系列字符串或逗号分隔的字符串一起使用:
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, names="A, B, C")
array([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0)],
dtype=[('A', '), ('B', '), ('C', ')])
在上面的例子中,我们使用了默认情况下dtype=float的事实。通过给出一个名称序列,我们强制输出到一个结构化的dtype。
我们有时可能需要从数据本身定义列名。在这种情况下,我们必须使用names关键字的值为True。这些名字将从第一行(在skip_header之后)被读取,即使该行被注释掉:
>>> data = BytesIO("So it goes\n#a b c\n1 2 3\n 4 5 6")
>>> np.genfromtxt(data, skip_header=1, names=True)
array([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0)],
dtype=[('a', '), ('b', '), ('c', ')])
names的默认值为None。如果我们给关键字赋予任何其他值,新名称将覆盖我们可能用dtype定义的字段名称:
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> ndtype=[('a',int), ('b', float), ('c', int)]
>>> names = ["A", "B", "C"]
>>> np.genfromtxt(data, names=names, dtype=ndtype)
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('A', '), ('B', '), ('C', ')])
defaultfmt`参数
如果 names=None 的时候,只是预计会有一个结构化的dtype,它的名称将使用标准的NumPy默认值 "f%i"来定义,会产生例如f0,f1等名称:
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int))
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('f0', '), ('f1', '), ('f2', ')])
同样,如果我们没有提供足够的名称来匹配dtype的长度,缺少的名称将使用此默认模板进行定义:
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), names="a")
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('a', '), ('f0', '), ('f1', ')])
我们可以使用defaultfmt参数覆盖此默认值,该参数采用任何格式字符串:
>>> data = BytesIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), defaultfmt="var_%02i")
array([(1, 2.0, 3), (4, 5.0, 6)],
dtype=[('var_00', '), ('var_01', '), ('var_02', ')])
注意!
我们需要记住,仅当预期一些名称但未定义时才使用defaultfmt。
验证名称
具有结构化dtype的NumPy数组也可以被视为recarray,其中可以像访问属性一样访问字段。因此,我们可能需要确保字段名称不包含任何空格或无效字符,或者它不对应于标准属性的名称(如size或shape),这会混淆解释者。genfromtxt接受三个可选参数,这些参数可以更好地控制名称:
- deletechars - 给出一个字符串,将所有必须从名称中删除的字符组合在一起。默认情况下,无效字符是
~!@#$%^&*()-=+~\|]}[{';: /?.>,< - excludelist - 给出要排除的名称列表,如
return,file,print…如果其中一个输入名称是该列表的一部分,则会附加一个下划线字符('_')。 - case_sensitive - 是否区分大小写(
case_sensitive=True),转换为大写(case_sensitive=False或case_sensitive='upper')或小写(case_sensitive='lower')。
调整转换
converters参数
通常,定义一个dtype足以定义字符串序列必须如何转换。但是,有时可能需要一些额外的控制。例如,我们可能希望确保格式为YYYY/MM/DD的日期转换为datetime对象,或者像xx%正确转换为0到1之间的浮点数。在这种情况下,我们应该使用converters参数定义转换函数。
该参数的值通常是以列索引或列名称作为关键字的字典,并且转换函数作为值。这些转换函数可以是实际函数或lambda函数。无论如何,它们只应接受一个字符串作为输入,并只输出所需类型的单个元素。
在以下示例中,第二列从代表百分比的字符串转换为0和1之间的浮点数:
>>> convertfunc = lambda x: float(x.strip("%"))/100.
>>> data = "1, 2.3%, 45.\n6, 78.9%, 0"
>>> names = ("i", "p", "n")
>>> # General case .....
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names)
array([(1.0, nan, 45.0), (6.0, nan, 0.0)],
dtype=[('i', '), ('p', '), ('n', ')])
我们需要记住,默认情况下,dtype=float。因此,对于第二列期望浮点数。但是,字符串'2.3%'和'78.9%无法转换为浮点数,我们最终改为使用np.nan。现在让我们使用一个转换器:
>>> # Converted case ...
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names,
... converters={1: convertfunc})
array([(1.0, 0.023, 45.0), (6.0, 0.78900000000000003, 0.0)],
dtype=[('i', '), ('p', '), ('n', ')])
通过使用第二列("p")作为关键字而不是其索引(1)的名称,可以获得相同的结果:
>>> # Using a name for the converter ...
>>> np.genfromtxt(BytesIO(data), delimiter=",", names=names,
... converters={"p": convertfunc})
array([(1.0, 0.023, 45.0), (6.0, 0.78900000000000003, 0.0)],
dtype=[('i', '), ('p', '), ('n', ')])
转换器也可以用来为缺少的条目提供默认值。在以下示例中,如果字符串为空,则转换器convert会将已剥离的字符串转换为相应的浮点型或转换为-999。我们需要明确地从空白处去除字符串,因为它并未默认完成:
>>> data = "1, , 3\n 4, 5, 6"
>>> convert = lambda x: float(x.strip() or -999)
>>> np.genfromtxt(BytesIO(data), delimiter=",",
... converters={1: convert})
array([[ 1., -999., 3.],
[ 4., 5., 6.]])
使用缺失值和填充值
我们尝试导入的数据集中可能缺少一些条目。在前面的例子中,我们使用转换器将空字符串转换为浮点。但是,用户定义的转换器可能会很快变得繁琐,难以管理。
genfromtxt函数提供了另外两种补充机制:missing_values参数用于识别丢失的数据,第二个参数filling_values用于处理这些缺失的数据。
missing_values
默认情况下,任何空字符串都被标记为缺失。我们也可以考虑更复杂的字符串,比如"N/A"或"???"代表丢失或无效的数据。missing_values参数接受三种值:
- 单个字符串或逗号分隔的字符串 - 该字符串将用作所有列缺失数据的标记
- 字符串 - 在这种情况下,每个项目都按顺序与列关联。
- 字典类型 - 字典的值是字符串或字符串序列。相应的键可以是列索引(整数)或列名称(字符串)。另外,可以使用特殊键None来定义适用于所有列的默认值。
filling_values
我们知道如何识别丢失的数据,但我们仍然需要为这些丢失的条目提供一个值。默认情况下,根据此表根据预期的dtype确定此值:
我们知道如何识别丢失的数据,但我们仍然需要为这些丢失的条目提供一个值。默认情况下,根据此表根据预期的dtype确定此值:
| 预期类型 | 默认 |
|---|---|
bool |
False |
int |
-1 |
float |
np.nan |
complex |
np.nan+0j |
string |
'???' |
通过filling_values可选参数,我们可以更好地控制缺失值的转换。像missing_values一样,此参数接受不同类型的值:
- 单个值 - 这将是所有列的默认值
- 类数组类型 - 每个条目都是相应列的默认值
- 字典类型 - 每个键可以是列索引或列名称,并且相应的值应该是单个对象。我们可以使用特殊键None为所有列定义默认值。
在下面的例子中,我们假设缺少的值在第一列中用"N/A"标记,并由"???"在第三栏。如果它们出现在第一列和第二列中,我们希望将这些缺失值转换为0,如果它们出现在最后一列中,则将它们转换为-999:
>>> data = "N/A, 2, 3\n4, ,???"
>>> kwargs = dict(delimiter=",",
... dtype=int,
... names="a,b,c",
... missing_values={0:"N/A", 'b':" ", 2:"???"},
... filling_values={0:0, 'b':0, 2:-999})
>>> np.genfromtxt(BytesIO(data), **kwargs)
array([(0, 2, 3), (4, 0, -999)],
dtype=[('a', '), ('b', '), ('c', ')])
usemask
我们也可能想通过构造一个布尔掩码来跟踪丢失数据的发生,其中True条目缺少数据,否则False。为此,我们只需将可选参数usemask设置为True(默认值为False)。输出数组将成为MaskedArray。
快捷方式函数
除了 genfromtxt 之外,numpy.lib.io模块还提供了几个从 genfromtxt 派生的方便函数。这些函数的工作方式与原始函数相同,但它们具有不同的默认值。
- recfromtxt - 返回标准 numpy.recarray(如果
usemask=False)或 MaskedRecords数组(如果usemaske=True)。默认dtype是dtype=None,意味着将自动确定每列的类型。 - recfromcsv - 类似 recfromtxt,但有默认值
delimiter=","。
4,索引
数组索引是指使用方括号([])来索引数组值。索引有很多选项,它可以为numpy索引提供强大的功能,但是功能会带来一些复杂性和混淆的可能性。本节仅概述了与索引相关的各种选项和问题。除了单个元素索引之外,大多数这些选项的详细信息都可以在相关章节中找到。
1)赋值与引用
以下大多数示例体现在引用数组中的数据时使用索引。分配给数组时,这些示例也可以正常运行的。有关分配的原理具体示例和说明,请参见最后一节。
2)单个元素索引
人们期望的是1-D数组的单元素索引。它的工作方式与其他标准Python序列完全相同。它基于0,并接受从数组末尾开始索引的负索引。
>>> x = np.arange(10)
>>> x[2]
2
>>> x[-2]
8
与列表和元组不同,numpy数组支持多维数组的多维索引。这意味着没有必要将每个维度的索引分成它自己的一组方括号。
>>> x.shape = (2,5) # now x is 2-dimensional
>>> x[1,3]
8
>>> x[1,-1]
9
请注意,如果索引索引比维度少的多维数组,则会获得一个子维数组。例如:
>>> x[0]
array([0, 1, 2, 3, 4])
也就是说,指定的每个索引选择与所选维度的其余部分对应的数组。在上面的示例中,选择0表示长度为5的剩余维度未指定,返回的是该维度和大小的数组。必须注意的是,返回的数组不是原始数据的副本,而是指向内存中与原始数组相同的值。在这种情况下,返回第一个位置(0)的1-D数组。因此,在返回的数组上使用单个索引会导致返回单个元素。那是:
>>> x[0][2]
2
请注意,尽管第二种情况效率较低,因为在第一个索引之后创建了一个新的临时数组,该索引随后被索引为2:x[0,2] = x[0][2]
请注意那些习惯于IDL或Fortran内存顺序的内容,因为它与索引有关。NumPy使用C顺序索引。这意味着最后一个索引通常代表最快速变化的内存位置,与Fortran或IDL不同,其中第一个索引代表内存中变化最快的位置。这种差异代表了混淆的巨大潜力。
3)其他索引选项
可以对数组进行切片和跨步以提取具有相同数量的尺寸但具有与原始尺寸不同的尺寸的数组。切片和跨步的工作方式与列表和元组的工作方式完全相同,只是它们也可以应用于多个维度。一些例子说明了最好的:
>>> x = np.arange(10)
>>> x[2:5]
array([2, 3, 4])
>>> x[:-7]
array([0, 1, 2])
>>> x[1:7:2]
array([1, 3, 5])
>>> y = np.arange(35).reshape(5,7)
>>> y[1:5:2,::3]
array([[ 7, 10, 13],
[21, 24, 27]])
请注意,数组切片不会复制内部数组数据,只会生成原始数据的新视图。这与列表或元组切片不同,copy()如果不再需要原始数据,建议使用显式。
可以使用其他数组索引数组,以便从数组中选择值列表到新数组中。有两种不同的方法来实现这一点。一个使用一个或多个索引值数组。另一个涉及给出一个正确形状的布尔数组来指示要选择的值。索引数组是一个非常强大的工具,可以避免循环遍历数组中的各个元素,从而大大提高性能。
可以使用特殊功能通过索引有效地增加数组中的维数,以便生成的数组获取在表达式或特定函数中使用所需的形状。
4)索引数组
NumPy数组可以使用其他数组(或任何其他可以转换为数组的类似序列的对象,如列表,除元组之外的索引;请参阅本文档末尾的原因)。索引数组的使用范围从简单,直接的案例到复杂的,难以理解的案例。对于索引数组的所有情况,返回的是原始数据的副本,而不是切片获取的视图。
索引数组必须是整数类型。数组中的每个值指示要使用的数组中的哪个值代替索引。为了显示:
>>> x = np.arange(10,1,-1)
>>> x
array([10, 9, 8, 7, 6, 5, 4, 3, 2])
>>> x[np.array([3, 3, 1, 8])]
array([7, 7, 9, 2])
由值3,3,1和8组成的索引数组相应地创建一个长度为4的数组(与索引数组相同),其中每个索引由索引数组在被索引的数组中具有的值替换。
允许使用负值,并且与单个索引或切片一样工作:
>>> x[np.array([3,3,-3,8])]
array([7, 7, 4, 2])
索引值超出范围是错误的:
>>> x[np.array([3, 3, 20, 8])]
<type 'exceptions.IndexError'>: index 20 out of bounds 0<=index<9
一般来说,使用索引数组时返回的是与索引数组具有相同形状的数组,但索引的数组的类型和值。作为示例,我们可以使用多维索引数组:
>>> x[np.array([[1,1],[2,3]])]
array([[9, 9],
[8, 7]])
5)索引多维数组
当索引多维数组时,事情变得更加复杂,特别是对于多维索引数组。这些往往是更不寻常的用途,但它们是允许的,它们对某些问题很有用。我们将从最简单的多维情况开始(使用前面示例中的数组y):
>>> y[np.array([0,2,4]), np.array([0,1,2])]
array([ 0, 15, 30])
在这种情况下,如果索引数组具有匹配的形状,并且索引数组的每个维度都有一个索引数组,则结果数组具有与索引数组相同的形状,并且值对应于每个索引的索引集在索引数组中的位置。在此示例中,两个索引数组的第一个索引值均为0,因此结果数组的第一个值为y [0,0]。下一个值是y [2,1],最后一个是y [4,2]。
如果索引数组的形状不同,则尝试将它们广播为相同的形状。如果它们无法广播到相同的形状,则会引发异常:
>>> y[np.array([0,2,4]), np.array([0,1])]
<type 'exceptions.ValueError'>: shape mismatch: objects cannot be
broadcast to a single shape
广播机制允许索引数组与其他索引的标量组合。结果是标量值用于索引数组的所有相应值:
>>> y[np.array([0,2,4]), 1]
array([ 1, 15, 29])
跳到下一级复杂性,可以仅使用索引数组对数组进行部分索引。需要一些思考才能理解在这种情况下会发生什么。例如,如果我们只使用一个带y的索引数组:
>>> y[np.array([0,2,4])]
array([[ 0, 1, 2, 3, 4, 5, 6],
[14, 15, 16, 17, 18, 19, 20],
[28, 29, 30, 31, 32, 33, 34]])
结果是构造一个新数组,其中索引数组的每个值从被索引的数组中选择一行,结果数组具有结果形状(索引元素的数量,行的大小)。
这可能有用的示例是用于颜色查找表,其中我们想要将图像的值映射到RGB三元组以供显示。查找表可以具有形状(nlookup,3)。使用带有dtype = np.uint8的形状(ny,nx)的图像索引此类数组(或任何整数类型,只要值与查找表的边界一致)将导致形状数组(ny,nx, 3)其中三个RGB值与每个像素位置相关联。
通常,结果数组的形状将是索引数组的形状(或所有索引数组被广播的形状)与被索引的数组中任何未使用的维度(未索引的那些)的形状的串联。
6)布尔或“掩码”索引数组
用作索引的布尔数组的处理方式与索引数组完全不同。布尔数组的形状必须与要索引的数组的初始尺寸相同。在最直接的情况下,布尔数组具有相同的形状:
>>> b = y>20
>>> y[b]
array([21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34])
与整数索引数组的情况不同,在布尔情况下,结果是一个一维数组,其中包含索引数组中与布尔数组中所有真实元素对应的所有元素。索引数组中的元素始终是迭代的,并以 行主(C样式)顺序返回。结果也是一样的 y[np.nonzero(b)]。与索引数组一样,返回的是数据的副本,而不是切片所获得的视图。
如果y的维数多于b,则结果将是多维的。例如:
>>> b[:,5] # use a 1-D boolean whose first dim agrees with the first dim of y
array([False, False, False, True, True])
>>> y[b[:,5]]
array([[21, 22, 23, 24, 25, 26, 27],
[28, 29, 30, 31, 32, 33, 34]])
这里,从索引数组中选择第4行和第5行,并组合成2-D数组。
通常,当布尔数组的维数小于被索引的数组时,这相当于y [b,…],这意味着y被b索引后跟多少:填充y的等级所需的数量。因此,结果的形状是一个维度,其中包含布尔数组的True元素的数量,后跟被索引的数组的其余维度。
例如,使用具有四个True元素的形状(2,3)的二维布尔数组来从三维形状数组(2,3,5)中选择行,从而得到形状的二维结果(4 ,5):
>>> x = np.arange(30).reshape(2,3,5)
>>> x
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]],
[[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]])
>>> b = np.array([[True, True, False], [False, True, True]])
>>> x[b]
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]])
有关更多详细信息,请参阅有关数组索引的numpy参考文档。
7)将索引数组与切片组合
索引数组可以与切片组合。例如:
>>> y[np.array([0,2,4]),1:3]
array([[ 1, 2],
[15, 16],
[29, 30]])
实际上,切片被转换为索引数组 np.array([[1,2]]) (shape (1,2)),它与索引数组一起广播以产生一个结果 shape(3,2) 的数组。
同样,切片可以与广播的布尔索引组合:
>>> b = y > 20
>>> b
array([[False, False, False, False, False, False, False],
[False, False, False, False, False, False, False],
[False, False, False, False, False, False, False],
[ True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True]])
>>> y[b[:,5],1:3]
array([[22, 23],
[29, 30]])
8)结构索引工具
为了便于数组形状与表达式和赋值的轻松匹配,可以在数组索引中使用np.newaxis对象来添加大小为1的新维度。例如:
>>> y.shape
(5, 7)
>>> y[:,np.newaxis,:].shape
(5, 1, 7)
请注意,数组中没有新元素,只是增加了维度。这可以方便地以一种方式组合两个数组,否则将需要显式重新整形操作。例如:
>>> x = np.arange(5)
>>> x[:,np.newaxis] + x[np.newaxis,:]
array([[0, 1, 2, 3, 4],
[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7],
[4, 5, 6, 7, 8]])
省略号语法可用于指示完全选择任何剩余的未指定维度。例如:
>>> z = np.arange(81).reshape(3,3,3,3)
>>> z[1,...,2]
array([[29, 32, 35],
[38, 41, 44],
[47, 50, 53]])
这相当于:
>>> z[1,:,:,2]
array([[29, 32, 35],
[38, 41, 44],
[47, 50, 53]])
9)为索引数组赋值
如上所述,可以选择要分配给使用单个索引,切片,索引和掩码数组的数组的子集。分配给索引数组的值必须是形状一致的(与索引生成的形状相同的形状或可广播)。例如,允许为切片分配常量:
>>> x = np.arange(10)
>>> x[2:7] = 1
或者正确大小的数组:
>>> x[2:7] = np.arange(5)
请注意,如果将较高类型分配给较低类型(如浮点数到整数)或甚至异常(将复数分配给浮点数或整数),则赋值可能会导致更改:
>>> x[1] = 1.2
>>> x[1]
1
>>> x[1] = 1.2j
<type 'exceptions.TypeError'>: can't convert complex to long; use
long(abs(z))
与某些引用(例如数组和掩码索引)不同,总是对数组中的原始数据进行赋值(实际上,其他任何内容都没有意义!)。但请注意,某些操作可能无法正常工作。这个特殊的例子通常让人惊讶:
>>> x = np.arange(0, 50, 10)
>>> x
array([ 0, 10, 20, 30, 40])
>>> x[np.array([1, 1, 3, 1])] += 1
>>> x
array([ 0, 11, 20, 31, 40])
人们期望第一个位置将增加3.实际上,它只会增加1.原因是因为从原始(作为临时)提取的新数组包含值1,1,3 ,1,然后将值1添加到临时值,然后将临时值分配回原始数组。因此,x [1] +1处的数组的值被赋予x [1]三次,而不是递增3次。
10)在程序中处理可变数量的索引
索引语法非常强大,但在处理可变数量的索引时会受到限制。例如,如果要编写一个可以处理具有不同维数的参数的函数,而不必为每个可能的维度编写特殊的案例代码,那么该怎么做呢?如果向索引提供元组,则元组将被解释为索引列表。例如(使用先前的数组z定义):
>>> indices = (1,1,1,1)
>>> z[indices]
40
因此,可以使用代码构造任意数量的索引的元组,然后在索引中使用它们。
可以使用Python中的slice() 函数在程序中指定切片。例如:
>>> indices = (1,1,1,slice(0,2)) # same as [1,1,1,0:2]
>>> z[indices]
array([39, 40])
同样,可以使用Ellipsis对象通过代码指定省略号:
>>> indices = (1, Ellipsis, 1) # same as [1,...,1]
>>> z[indices]
array([[28, 31, 34],
[37, 40, 43],
[46, 49, 52]])
由于这个原因,可以直接使用 np.nonzero() 函数的输出作为索引,因为它总是返回索引数组的元组。
因为对元组的特殊处理,它们不会像列表那样自动转换为数组。举个例子:
>>> z[[1,1,1,1]] # produces a large array
array([[[[27, 28, 29],
[30, 31, 32], ...
>>> z[(1,1,1,1)] # returns a single value
40
5,广播(Broadcasting)
术语广播(Broadcasting)描述了 numpy 如何在算术运算期间处理具有不同形状的数组。受某些约束的影响,较小的数组在较大的数组上“广播”,以便它们具有兼容的形状。广播提供了一种矢量化数组操作的方法,以便在C而不是Python中进行循环。它可以在不制作不必要的数据副本的情况下实现这一点,通常导致高效的算法实现。然而,有些情况下广播是一个坏主意,因为它会导致内存使用效率低下,从而减慢计算速度。
NumPy 操作通常在逐个元素的基础上在数组对上完成。在最简单的情况下,两个数组必须具有完全相同的形状,如下例所示:
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = np.array([2.0, 2.0, 2.0])
>>> a * b
array([ 2., 4., 6.])
当数组的形状满足某些约束时,NumPy的广播规则放宽了这种约束。当一个数组和一个标量值在一个操作中组合时,会发生最简单的广播示例:
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = 2.0
>>> a * b
array([ 2., 4., 6.])
结果等同于前面的示例,其中b是数组。我们可以将在算术运算期间b被 拉伸 的标量想象成具有相同形状的数组a。新元素 b只是原始标量的副本。拉伸类比只是概念性的。NumPy足够聪明,可以使用原始标量值而无需实际制作副本,因此广播操作尽可能具有内存和计算效率。
第二个示例中的代码比第一个示例中的代码更有效,因为广播在乘法期间移动的内存较少(b是标量而不是数组)。
一般广播规则
在两个数组上运行时,NumPy会逐元素地比较它们的形状。它从尾随尺寸开始,并向前发展。两个尺寸兼容时
- 他们是平等的,或者
- 其中一个是1
如果不满足这些条件,则抛出 ValueError: operands could not be broadcast together 异常,指示数组具有不兼容的形状。结果数组的大小是沿输入的每个轴不是1的大小。
数组不需要具有相同 数量 的维度。例如,如果您有一个256x256x3RGB值数组,并且希望将图像中的每种颜色缩放不同的值,则可以将图像乘以具有3个值的一维数组。根据广播规则排列这些数组的尾轴的大小,表明它们是兼容的:
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3
当比较的任何一个尺寸为1时,使用另一个尺寸。换句话说,尺寸为1的尺寸被拉伸或“复制”以匹配另一个尺寸。
在以下示例中,A和B数组都具有长度为1的轴,在广播操作期间会扩展为更大的大小:
A (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5
以下是一些例子:
A (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
A (2d array): 5 x 4
B (1d array): 4
Result (2d array): 5 x 4
A (3d array): 15 x 3 x 5
B (3d array): 15 x 1 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 1
Result (3d array): 15 x 3 x 5
以下是不广播的形状示例:
A (1d array): 3
B (1d array): 4 # trailing dimensions do not match
A (2d array): 2 x 1
B (3d array): 8 x 4 x 3 # second from last dimensions mismatched
实践中广播的一个例子:
>>> x = np.arange(4)
>>> xx = x.reshape(4,1)
>>> y = np.ones(5)
>>> z = np.ones((3,4))
>>> x.shape
(4,)
>>> y.shape
(5,)
>>> x + y
ValueError: operands could not be broadcast together with shapes (4,) (5,)
>>> xx.shape
(4, 1)
>>> y.shape
(5,)
>>> (xx + y).shape
(4, 5)
>>> xx + y
array([[ 1., 1., 1., 1., 1.],
[ 2., 2., 2., 2., 2.],
[ 3., 3., 3., 3., 3.],
[ 4., 4., 4., 4., 4.]])
>>> x.shape
(4,)
>>> z.shape
(3, 4)
>>> (x + z).shape
(3, 4)
>>> x + z
array([[ 1., 2., 3., 4.],
[ 1., 2., 3., 4.],
[ 1., 2., 3., 4.]])
广播提供了一种方便的方式来获取两个数组的外积(或任何其他外部操作)。以下示例显示了两个1-d数组的外积操作:
>>> a = np.array([0.0, 10.0, 20.0, 30.0])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a[:, np.newaxis] + b
array([[ 1., 2., 3.],
[ 11., 12., 13.],
[ 21., 22., 23.],
[ 31., 32., 33.]])
这里 newaxis 索引操作符插入一个新轴 a ,使其成为一个二维 4x1 数组。将 4x1 数组与形状为 (3,) 的 b 组合,产生一个4x3数组。
6,字节交换
1)字节排序和ndarrays简介
ndarray是一个为内存中的数据提供python数组接口的对象。
经常发生的情况是,要用数组查看的内存与运行Python的计算机的字节顺序不同。
例如,我可能正在使用带有 little-endian CPU 的计算机 - 例如Intel Pentium,但是我已经从一个由 big-endian计算机 编写的文件中加载了一些数据。假设我已经从Sun(big-endian)计算机写入的文件中加载了4个字节。我知道这4个字节代表两个16位整数。在 big-endian 机器上,首先以最高有效字节(MSB)存储双字节整数,然后存储最低有效字节(LSB)。因此字节按内存顺序排列:
- MSB整数1
- LSB整数1
- MSB整数2
- LSB整数2
假设两个整数实际上是1和770.因为770 = 256 * 3 + 2,内存中的4个字节将分别包含:0,1,3,2。我从文件加载的字节将包含这些内容:
>>> big_end_buffer = bytearray([0,1,3,2])
>>> big_end_buffer
bytearray(b'\x00\x01\x03\x02')
我们可能需要使用 ndarray 来访问这些整数。在这种情况下,我们可以围绕这个内存创建一个数组,并告诉numpy有两个整数,并且它们是16位和Big-endian:
>>> import numpy as np
>>> big_end_arr = np.ndarray(shape=(2,),dtype='>i2', buffer=big_end_buffer)
>>> big_end_arr[0]
1
>>> big_end_arr[1]
770
注意上面的数组dtype > i2。> 表示 big-endian( < 是 Little-endian ),i2 表示‘有符号的2字节整数’。例如,如果我们的数据表示单个无符号4字节小端整数,则dtype字符串将为
事实上,为什么我们不尝试呢?
>>> little_end_u4 = np.ndarray(shape=(1,),dtype=', buffer=big_end_buffer)
>>> little_end_u4[0] == 1 * 256**1 + 3 * 256**2 + 2 * 256**3
True
回到我们的 big_end_arr - 在这种情况下我们的基础数据是big-endian(数据字节序),我们设置dtype匹配(dtype也是big-endian)。但是,有时你需要翻转它们。
警告
标量当前不包含字节顺序信息,因此从数组中提取标量将返回本机字节顺序的整数。因此:
>>> big_end_arr[0].dtype.byteorder == little_end_u4[0].dtype.byteorder
True
2)更改字节顺序
从介绍中可以想象,有两种方法可以影响数组的字节顺序与它所查看的底层内存之间的关系:
- 更改数组dtype中的字节顺序信息,以便将基础数据解释为不同的字节顺序。这是作用
arr.newbyteorder() - 更改基础数据的字节顺序,保留dtype解释。这是做什么的
arr.byteswap()。
您需要更改字节顺序的常见情况是:
- 您的数据和dtype字节顺序不匹配,并且您希望更改dtype以使其与数据匹配。
- 您的数据和dtype字节顺序不匹配,并且您希望交换数据以使它们与dtype匹配
- 您的数据和dtype字节顺序匹配,但您希望交换数据和dtype来反映这一点
数据和dtype字节顺序不匹配,更改dtype以匹配数据
我们制作一些他们不匹配的东西:
>>> wrong_end_dtype_arr = np.ndarray(shape=(2,),dtype=', buffer=big_end_buffer)
>>> wrong_end_dtype_arr[0]
256
这种情况的明显解决方法是更改dtype,以便它给出正确的字节顺序:
>>> fixed_end_dtype_arr = wrong_end_dtype_arr.newbyteorder()
>>> fixed_end_dtype_arr[0]
1
请注意,内存中的数组未更改:
>>> fixed_end_dtype_arr.tobytes() == big_end_buffer
True
数据和类型字节顺序不匹配,更改数据以匹配dtype
如果您需要内存中的数据是某种顺序,您可能希望这样做。例如,您可能正在将内存写入需要特定字节排序的文件。
>>> fixed_end_mem_arr = wrong_end_dtype_arr.byteswap()
>>> fixed_end_mem_arr[0]
1
现在数组 已 在内存中更改:
>>> fixed_end_mem_arr.tobytes() == big_end_buffer
False
数据和dtype字节序匹配,交换数据和dtype
您可能有一个正确指定的数组dtype,但是您需要数组在内存中具有相反的字节顺序,并且您希望dtype匹配以便数组值有意义。在这种情况下,您只需执行上述两个操作:
>>> swapped_end_arr = big_end_arr.byteswap().newbyteorder()
>>> swapped_end_arr[0]
1
>>> swapped_end_arr.tobytes() == big_end_buffer
False
使用ndarray astype方法可以更简单地将数据转换为特定的dtype和字节顺序:
>>> swapped_end_arr = big_end_arr.astype(')
>>> swapped_end_arr[0]
1
>>> swapped_end_arr.tobytes() == big_end_buffer
False
7,结构化数组
1)介绍
结构化数组是ndarray,其数据类型是由一系列命名字段组织的简单数据类型组成。例如:
>>> x = np.array([('Rex', 9, 81.0), ('Fido', 3, 27.0)],
... dtype=[('name', 'U10'), ('age', 'i4'), ('weight', 'f4')])
>>> x
array([('Rex', 9, 81.), ('Fido', 3, 27.)],
dtype=[('name', 'U10'), ('age', '), ('weight', ')])
x 是一个长度为2的一维数组,其数据类型是一个包含三个字段的结构:
- 长度为10或更少的字符串,名为“name”。
- 一个32位整数,名为“age”。
- 一个32位的名为’weight’的float类型。
如果您x在位置1处索引,则会得到一个结构:
>>> x[1]
('Fido', 3, 27.0)
您可以通过使用字段名称建立索引来访问和修改结构化数组的各个字段:
>>> x['age']
array([9, 3], dtype=int32)
>>> x['age'] = 5
>>> x
array([('Rex', 5, 81.), ('Fido', 5, 27.)],
dtype=[('name', 'U10'), ('age', '), ('weight', ')])
结构化数据类型旨在能够模仿C语言中的“结构”,并共享类似的内存布局。它们用于连接C代码和低级操作结构化缓冲区,例如用于解释二进制blob。出于这些目的,它们支持诸如子数组,嵌套数据类型和联合之类的专用功能,并允许控制结构的内存布局。
希望操纵表格数据的用户(例如存储在csv文件中)可能会发现其他更适合的pydata项目,例如xarray,pandas或DataArray。这些为表格数据分析提供了高级接口,并且针对该用途进行了更好的优化。例如,numpy中结构化数组的类似C-struct的内存布局可能导致较差的缓存行为。
2)结构化数据类型
结构化数据类型可以被认为是一定长度的字节序列(结构的项目大小),它被解释为字段集合。每个字段在结构中都有一个名称,一个数据类型和一个字节偏移量。字段的数据类型可以是包括其他结构化数据类型的任何numpy数据类型,也可以是子行数据类型,其行为类似于指定形状的ndarray。字段的偏移是任意的,字段甚至可以重叠。这些偏移量通常由numpy自动确定,但也可以指定。
结构化数据类型创建
可以使用该函数创建结构化数据类型numpy.dtype。有4种不同的规范形式, 其灵活性和简洁性各不相同。这些在 “数据类型对象” 参考页面中进一步记录,总结如下:
-
元组列表,每个字段一个元组
每个元组都具有以下形式
(字段名称、数据类型、形状),其中Shape是可选的。fieldname是字符串(如果使用标题,则为元组,请参见下面的字段标题), datatype 可以是任何可转换为数据类型的对象,而shape是指定子数组形状的整数元组。>>> np.dtype([('x', 'f4'), ('y', np.float32), ('z', 'f4', (2, 2))]) dtype([('x', '如果
fieldname是空字符串'',则将为字段指定格式为f#的默认名称, 其中#是字段的整数索引,从左侧开始从0开始计数:>>> np.dtype([('x', 'f4'), ('', 'i4'), ('z', 'i8')]) dtype([('x', '自动确定结构内字段的字节偏移量和总结构项大小。
-
逗号分隔的数据类型规范字符串
在这个速记符号中,任何 字符串dtype规范 都可以在字符串中使用, 并用逗号分隔。 字段的项目大小和字节偏移是自动确定的,并且字段名称被赋予默认名称
f0、f1等。>>> np.dtype('i8, f4, S3') dtype([('f0', ' -
字段参数组字典
这是最灵活的规范形式,因为它允许控制字段的字节偏移和结构的项目大小。
字典有两个必需键 “names” 和 “format”,以及四个可选键 “offsets”、“itemsize”、“Aligned” 和 “title”。 名称和格式的值应该分别是相同长度的字段名列表和dtype规范列表。 可选的 “offsets” 值应该是整数字节偏移量的列表,结构中的每个字段都有一个偏移量。 如果未给出 “Offsets” ,则自动确定偏移量。可选的 “itemsize” 值应该是一个整数, 描述dtype的总大小(以字节为单位),它必须足够大以包含所有字段。
>>> np.dtype({'names': ['col1', 'col2'], 'formats': ['i4', 'f4']}) dtype([('col1', '可以选择偏移量,使得字段重叠,尽管这将意味着分配给一个字段可能会破坏任何重叠字段的数据。 作为一个例外,numpy.object类型的字段不能与其他字段重叠,因为存在破坏内部对象指针然后取消引用它的风险。
可选的“Aligned”值可以设置为True,以使自动偏移计算使用对齐的偏移量(请参阅自动字节偏移量和对齐), 就好像numpy.dtype的“Align”关键字参数已设置为True一样。
可选的 ‘titles’ 值应该是长度与 ‘names’ 相同的标题列表,请参阅下面的字段标题。
-
字段名称字典 不鼓励使用这种形式的规范,但这里有文档记录,因为较旧的numpy代码可能会使用它。 字典的关键字是字段名称,值是指定类型和偏移量的元组:
>>> np.dtype({'col1': ('i1', 0), 'col2': ('f4', 1)}) dtype([('col1', 'i1'), ('col2', '不鼓励使用这种形式,因为Python字典在Python 3.6之前的Python版本中不保留顺序, 并且结构化dtype中字段的顺序有意义。字段标题可以通过使用3元组来指定,见下文。
操作和显示结构化数据类型
可以names 在dtype对象的属性中找到结构化数据类型的字段名称列表:
>>> d = np.dtype([('x', 'i8'), ('y', 'f4')])
>>> d.names
('x', 'y')
可以通过names使用相同长度的字符串序列分配属性来修改字段名称。
dtype对象还具有类似字典的属性,fields其键是字段名称(和字段标题,见下文), 其值是包含每个字段的dtype和字节偏移量的元组。
>>> d.fields
mappingproxy({'x': (dtype('int64'), 0), 'y': (dtype('float32'), 8)})
对于非结构化数组,names和fields属性都相同None。 测试 dtype 是否结构化的推荐方法是, 如果dt.names不是None 而不是 dt.names ,则考虑具有0字段的dtypes。
如果可能,结构化数据类型的字符串表示形式显示在“元组列表”表单中,否则numpy将回退到使用更通用的字典表单。
自动字节偏移和对齐
Numpy使用两种方法之一自动确定字段字节偏移量和结构化数据类型的总项目大小,具体取决于是否 align=True指定为关键字参数numpy.dtype。
默认情况下(align=False),numpy将字段打包在一起,使得每个字段从前一个字段结束的字节偏移开始,并且字段在内存中是连续的。
>>> def print_offsets(d):
... print("offsets:", [d.fields[name][1] for name in d.names])
... print("itemsize:", d.itemsize)
>>> print_offsets(np.dtype('u1, u1, i4, u1, i8, u2'))
offsets: [0, 1, 2, 6, 7, 15]
itemsize: 17
如果align=True设置了,numpy将以与许多C编译器填充C结构相同的方式填充结构。在某些情况下,对齐结构可以提高性能,但代价是增加了数据类型的大小。在字段之间插入填充字节,使得每个字段的字节偏移量将是该字段对齐的倍数,对于简单数据类型,通常等于字段的字节大小,请参阅PyArray_Descr.alignment。该结构还将添加尾随填充,以使其itemsize是最大字段对齐的倍数。
>>> print_offsets(np.dtype('u1, u1, i4, u1, i8, u2', align=True))
offsets: [0, 1, 4, 8, 16, 24]
itemsize: 32
请注意,尽管默认情况下几乎所有现代C编译器都以这种方式填充,但C结构中的填充依赖于C实现,因此不能保证此内存布局与C程序中相应结构的内容完全匹配。为了获得确切的对应关系,可能需要在numpy侧或C侧进行一些工作。
如果使用offsets基于字典的dtype规范中的可选键指定了偏移量,则设置align=True将检查每个字段的偏移量是其大小的倍数,并且itemsize是最大字段大小的倍数,如果不是,则引发异常。
如果结构化数组的字段和项目大小的偏移满足对齐条件,则数组将具有该ALIGNED flag集合。
便捷函数numpy.lib.recfunctions.repack_fields将对齐的dtype或数组转换为打包的dtype或数组,反之亦然。它需要一个dtype或结构化的ndarray作为参数,并返回一个带有字段重新打包的副本,带或不带填充字节。
字段标题
除了字段名称之外,字段还可以具有关联的标题,备用名称,有时用作字段的附加说明或别名。标题可用于索引数组,就像字段名一样。
要在使用dtype规范的list-of-tuples形式时添加标题,可以将字段名称指定为两个字符串的元组而不是单个字符串,它们分别是字段的标题和字段名称。例如:
>>> np.dtype([(('my title', 'name'), 'f4')])
dtype([(('my title', 'name'), ')])
当使用第一种形式的基于字典的规范时,标题可以'titles'作为如上所述的额外密钥提供。当使用第二个(不鼓励的)基于字典的规范时,可以通过提供3元素元组而不是通常的2元素元组来提供标题:(datatype, offset, title)
>>> np.dtype({'name': ('i4', 0, 'my title')})
dtype([(('my title', 'name'), ')])
该dtype.fields字典将包含标题作为键,如果使用任何头衔。这有效地表示具有标题的字段将在字典字典中表示两次。这些字段的元组值还将具有第三个元素,即字段标题。因此,并且因为names属性保留了字段顺序而fields 属性可能没有,所以建议使用dtype的names属性迭代dtype的字段,该属性不会列出标题,如:
>>> for name in d.names:
... print(d.fields[name][:2])
(dtype('int64'), 0)
(dtype('float32'), 8)
联合类型
默认情况下,结构化数据类型在numpy中实现为基本类型 numpy.void, 但是可以使用 数据类型对象中 中描述的dtype规范的 (base_dtype, dtype) 形式将其他 numpy 类型解释为结构化类型。 这里,base_dtype 是所需的底层 dtype,字段和标志将从dtype复制。此 dtype 类似于 C 中的“Union”。
3)索引和分配给结构化数组
将数据分配给结构化数组
有许多方法可以为结构化数组赋值:使用python元组,使用标量值或使用其他结构化数组。
从Python本机类型(元组)分配
为结构化数组赋值的最简单方法是使用python元组。每个赋值应该是一个长度等于数组中字段数的元组,而不是列表或数组,因为它们将触发numpy的广播规则。元组的元素从左到右分配给数组的连续字段:
>>> x = np.array([(1, 2, 3), (4, 5, 6)], dtype='i8, f4, f8')
>>> x[1] = (7, 8, 9)
>>> x
array([(1, 2., 3.), (7, 8., 9.)],
dtype=[('f0', '), ('f1', '), ('f2', ')])
Scalars的赋值
分配给结构化元素的标量将分配给所有字段。将标量分配给结构化数组时,或者将非结构化数组分配给结构化数组时,会发生这种情况:
>>> x = np.zeros(2, dtype='i8, f4, ?, S1')
>>> x[:] = 3
>>> x
array([(3, 3., True, b'3'), (3, 3., True, b'3')],
dtype=[('f0', '), ('f1', '), ('f2', '?'), ('f3', 'S1')])
>>> x[:] = np.arange(2)
>>> x
array([(0, 0., False, b'0'), (1, 1., True, b'1')],
dtype=[('f0', '), ('f1', '), ('f2', '?'), ('f3', 'S1')])
结构化数组也可以分配给非结构化数组,但前提是结构化数据类型只有一个字段:
>>> twofield = np.zeros(2, dtype=[('A', 'i4'), ('B', 'i4')])
>>> onefield = np.zeros(2, dtype=[('A', 'i4')])
>>> nostruct = np.zeros(2, dtype='i4')
>>> nostruct[:] = twofield
Traceback (most recent call last):
...
TypeError: Cannot cast scalar from dtype([('A', '), ('B', ')]) to dtype('int32') according to the rule 'unsafe'
来自其他结构化数组的赋值
两个结构化数组之间的分配就像源元素已转换为元组然后分配给目标元素一样。也就是说,源数组的第一个字段分配给目标数组的第一个字段,第二个字段同样分配,依此类推,而不管字段名称如何。具有不同数量的字段的结构化数组不能彼此分配。未包含在任何字段中的目标结构的字节不受影响。
>>> a = np.zeros(3, dtype=[('a', 'i8'), ('b', 'f4'), ('c', 'S3')])
>>> b = np.ones(3, dtype=[('x', 'f4'), ('y', 'S3'), ('z', 'O')])
>>> b[:] = a
>>> b
array([(0., b'0.0', b''), (0., b'0.0', b''), (0., b'0.0', b'')],
dtype=[('x', '), ('y', 'S3'), ('z', 'O')])
涉及子数组的分配
分配给子数组的字段时,首先将指定的值广播到子数组的形状。
索引结构化数组
访问单个字段
可以通过使用字段名称索引数组来访问和修改结构化数组的各个字段。
>>> x = np.array([(1, 2), (3, 4)], dtype=[('foo', 'i8'), ('bar', 'f4')])
>>> x['foo']
array([1, 3])
>>> x['foo'] = 10
>>> x
array([(10, 2.), (10, 4.)],
dtype=[('foo', '), ('bar', ')])
生成的数组是原始数组的视图。它共享相同的内存位置,写入视图将修改原始数组。
>>> y = x['bar']
>>> y[:] = 11
>>> x
array([(10, 11.), (10, 11.)],
dtype=[('foo', '), ('bar', ')])
此视图与索引字段具有相同的dtype和itemsize,因此它通常是非结构化数组,但嵌套结构除外。
>>> y.dtype, y.shape, y.strides
(dtype('float32'), (2,), (12,))
如果访问的字段是子数组,则子数组的维度将附加到结果的形状:
>>> x = np.zeros((2, 2), dtype=[('a', np.int32), ('b', np.float64, (3, 3))])
>>> x['a'].shape
(2, 2)
>>> x['b'].shape
(2, 2, 3, 3)
访问多个字段
可以索引并分配具有多字段索引的结构化数组,其中索引是字段名称列表。
警告
多字段索引的行为从Numpy 1.15变为Numpy 1.16。
使用多字段索引进行索引的结果是原始数组的视图,如下所示:
>>> a = np.zeros(3, dtype=[('a', 'i4'), ('b', 'i4'), ('c', 'f4')])
>>> a[['a', 'c']]
array([(0, 0.), (0, 0.), (0, 0.)],
dtype={'names':['a','c'], 'formats':[','], 'offsets':[0,8], 'itemsize':12})
对视图的赋值会修改原始数组。视图的字段将按其索引的顺序排列。请注意,与单字段索引不同,视图的dtype与原始数组具有相同的项目大小,并且具有与原始数组相同的偏移量的字段,并且仅缺少未编入索引的字段。
警告
在Numpy 1.15中,使用多字段索引索引数组会返回上面结果的副本,但字段在内存中打包在一起,就像通过一样numpy.lib.recfunctions.repack_fields。
从Numpy 1.16开始的新行为导致在未编制索引的位置处的额外“填充”字节与1.15相比。您需要更新任何依赖于具有“打包”布局的数据的代码。例如代码如:
>>> a[['a', 'c']].view('i8') # Fails in Numpy 1.16
Traceback (most recent call last):
File "" , line 1, in <module>
ValueError: When changing to a smaller dtype, its size must be a divisor of the size of original dtype
需要改变。FutureWarning自从Numpy 1.12以来,这段代码已经提出了类似的代码,FutureWarning自1.7 以来也提出了类似的代码。
在1.16中,numpy.lib.recfunctions模块中引入了许多功能, 以帮助用户解释此更改。这些是 numpy.lib.recfunctions.repack_fields。numpy.lib.recfunctions.structured_to_unstructured,numpy.lib.recfunctions.unstructured_to_structured,numpy.lib.recfunctions.apply_along_fields,numpy.lib.recfunctions.assign_fields_by_name,和numpy.lib.recfunctions.require_fields。
该函数numpy.lib.recfunctions.repack_fields始终可用于重现旧行为,因为它将返回结构化数组的打包副本。例如,上面的代码可以替换为:
>>> from numpy.lib.recfunctions import repack_fields
>>> repack_fields(a[['a', 'c']]).view('i8') # supported in 1.16
array([0, 0, 0])
此外,numpy现在提供了一个新功能numpy.lib.recfunctions.structured_to_unstructured,对于希望将结构化数组转换为非结构化数组的用户来说,这是一种更安全,更有效的替代方法,因为上面的视图通常不符合要求。此功能允许安全地转换为非结构化类型,并考虑填充,通常避免复制,并且还根据需要转换数据类型,这与视图不同。代码如:
>>> b = np.zeros(3, dtype=[('x', 'f4'), ('y', 'f4'), ('z', 'f4')])
>>> b[['x', 'z']].view('f4')
array([0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
可以通过替换为:更安全
>>> from numpy.lib.recfunctions import structured_to_unstructured
>>> structured_to_unstructured(b[['x', 'z']])
array([0, 0, 0])
使用多字段索引分配数组会修改原始数组:
>>> a[['a', 'c']] = (2, 3)
>>> a
array([(2, 0, 3.), (2, 0, 3.), (2, 0, 3.)],
dtype=[('a', '), ('b', '), ('c', ')])
这遵循上述结构化数组分配规则。例如,这意味着可以使用适当的多字段索引交换两个字段的值:
>>> a[['a', 'c']] = a[['c', 'a']]
使用整数进行索引以获得结构化标量
索引结构化数组的单个元素(带有整数索引)将返回结构化标量:
>>> x = np.array([(1, 2., 3.)], dtype='i, f, f')
>>> scalar = x[0]
>>> scalar
(1, 2., 3.)
>>> type(scalar)
<class 'numpy.void'>
与其他numpy标量不同,结构化标量是可变的,并且像原始数组中的视图一样,因此修改标量将修改原始数组。结构化标量还支持按字段名称进行访问和分配:
>>> x = np.array([(1, 2), (3, 4)], dtype=[('foo', 'i8'), ('bar', 'f4')])
>>> s = x[0]
>>> s['bar'] = 100
>>> x
array([(1, 100.), (3, 4.)],
dtype=[('foo', '), ('bar', ')])
与元组类似,结构化标量也可以用整数索引:
>>> scalar = np.array([(1, 2., 3.)], dtype='i, f, f')[0]
>>> scalar[0]
1
>>> scalar[1] = 4
因此,元组可能被认为是本机Python等同于numpy的结构化类型,就像本机python整数相当于numpy的整数类型。结构化标量可以通过调用ndarray.item以下方式转换为元组:
>>> scalar.item(), type(scalar.item())
((1, 4.0, 3.0), <class 'tuple'>)
查看包含对象的结构化数组
为了防止numpy.object类型字段中的clobbering对象指针 ,numpy当前不允许包含对象的结构化数组的视图。
结构比较
如果两个void结构化数组的dtypes相等,则测试数组的相等性将导致具有原始数组的维度的布尔数组,其中元素设置为True相应结构的所有字段相等的位置。如果字段名称,dtypes和标题相同,忽略字节顺序,并且字段的顺序相同,则结构化dtypes是相等的:
>>> a = np.zeros(2, dtype=[('a', 'i4'), ('b', 'i4')])
>>> b = np.ones(2, dtype=[('a', 'i4'), ('b', 'i4')])
>>> a == b
array([False, False])
目前,如果两个void结构化数组的dtypes不相等,则比较失败,返回标量值False。从numpy 1.10开始不推荐使用此行为,并且将来会引发错误或执行元素比较。
在<与>运营商总是返回False比较空洞结构数组时,与算术和位操作不被支持。
4)记录数组
作为一个可选的方便numpy numpy.recarray在numpy.rec子模块中提供了一个ndarray子类, 以及相关的辅助函数 ,它允许按属性而不是仅通过索引访问结构化数组的字段。记录数组也使用特殊的数据类型,numpy.record允许通过属性对从数组中获取的结构化标量进行字段访问。
创建记录数组的最简单方法是numpy.rec.array:
>>> recordarr = np.rec.array([(1, 2., 'Hello'), (2, 3., "World")],
... dtype=[('foo', 'i4'),('bar', 'f4'), ('baz', 'S10')])
>>> recordarr.bar
array([ 2., 3.], dtype=float32)
>>> recordarr[1:2]
rec.array([(2, 3., b'World')],
dtype=[('foo', '), ('bar', '), ('baz', 'S10')])
>>> recordarr[1:2].foo
array([2], dtype=int32)
>>> recordarr.foo[1:2]
array([2], dtype=int32)
>>> recordarr[1].baz
b'World'
numpy.rec.array 可以将各种参数转换为记录数组,包括结构化数组:
>>> arr = np.array([(1, 2., 'Hello'), (2, 3., "World")],
... dtype=[('foo', 'i4'), ('bar', 'f4'), ('baz', 'S10')])
>>> recordarr = np.rec.array(arr)
该numpy.rec模块提供了许多其他便利函数来创建记录数组,请参阅记录数组创建例程。
可以使用适当的视图获取结构化数组的记录数组表示:
>>> arr = np.array([(1, 2., 'Hello'), (2, 3., "World")],
... dtype=[('foo', 'i4'),('bar', 'f4'), ('baz', 'a10')])
>>> recordarr = arr.view(dtype=np.dtype((np.record, arr.dtype)),
... type=np.recarray)
为方便起见,将ndarray视为类型np.recarray将自动转换为np.record数据类型,因此dtype可以不在视图之外:
>>> recordarr = arr.view(np.recarray)
>>> recordarr.dtype
dtype((numpy.record, [('foo', '), ('bar', '), ('baz', 'S10')]))
要返回普通的ndarray,必须重置dtype和type。以下视图是这样做的,考虑到recordarr不是结构化类型的异常情况:
>>> arr2 = recordarr.view(recordarr.dtype.fields or recordarr.dtype, np.ndarray)
如果字段具有结构化类型,则返回由index或by属性访问的记录数组字段作为记录数组,否则返回普通ndarray。
>>> recordarr = np.rec.array([('Hello', (1, 2)), ("World", (3, 4))],
... dtype=[('foo', 'S6'),('bar', [('A', int), ('B', int)])])
>>> type(recordarr.foo)
<class 'numpy.ndarray'>
>>> type(recordarr.bar)
<class 'numpy.recarray'>
请注意,如果字段与ndarray属性具有相同的名称,则ndarray属性优先。这些字段将无法通过属性访问,但仍可通过索引访问。
5)Recarray Helper 函数
用于操作结构化数组的实用程序的集合。
大多数这些功能最初由 John Hunter 为 matplotlib 实现。为方便起见,它们已被重写和扩展。
-
numpy.lib.recfunctions.append_fields(base, names, data, dtypes=None, fill_value=-1, usemask=True, asrecarray=False)[点击查看源码]
将新字段添加到现有数组。
字段的名称使用 names 参数给出,相应的值使用 data 参数。如果追加单个字段,则 names、data 和 dtypes 不必是列表,只是值。
参数表:
参数名 数据类型 描述 base array 要扩展的输入数组。 names string, sequence 对应于新字段名称的字符串或字符串序列。 data array or sequence of arrays 存储要添加到基数的字段的数组或数组序列。 dtypes sequence of datatypes, optional 数据类型或数据类型序列。如果没有填写,则从数据自动推断数据类型。 fill_value {float}, optional 用于填充较短数组上缺少的数据的填充值。 usemask {False, True}, optional 是否返回掩码数组。 asrecarray {False, True}, optional 是否返回recarray(MaskedRecords)。 -
numpy.lib.recfunctions.apply_along_fields(func, arr)[点击查看源码]
将函数“func”简单的应用于结构化数组的各个字段的。
这类似于 apply_along_axis,但将结构化数组的字段视为额外轴。这些字段首先被转换为类型提升规则后
numpy.result_type应用于字段的dtypes 的公共类型。参数表:
参数名 数据类型 描述 func function 要应用于“field”维度的函数。此函数必须支持轴参数,如np.mean、np.sum 等。 arr ndarray 要应用func的结构化数组。 返回值:
参数名 数据类型 描述 out ndarray 恢复操作的结果 示例:
>>> from numpy.lib import recfunctions as rfn >>> b = np.array([(1, 2, 5), (4, 5, 7), (7, 8 ,11), (10, 11, 12)], ... dtype=[('x', 'i4'), ('y', 'f4'), ('z', 'f8')]) >>> rfn.apply_along_fields(np.mean, b) array([ 2.66666667, 5.33333333, 8.66666667, 11. ]) >>> rfn.apply_along_fields(np.mean, b[['x', 'z']]) array([ 3. , 5.5, 9. , 11. ]) -
numpy.lib.recfunctions.assign_fields_by_name(dst, src, zero_unassigned=True)[点击查看源码]
通过字段名称将值从一个结构化数组分配到另一个结构化数组。
通常在numpy>=1.14中,将一个结构化数组分配给另一个结构化数组会 “按位置” 复制字段,这意味着来自src的第一个字段被复制到DST的第一个字段,依此类推,与字段名称无关。
此函数改为复制 “按字段名”,以便从src中的同名字段分配DST中的字段。这对嵌套结构递归适用。这就是在 numpy>=1.6 到 <=1.13 中结构赋值的工作方式。
参数表:
参数名 数据类型 描述 dst ndarray 略 src ndarray 分配期间的源数组和目标数组。 zero_unassigned bool,可选 如果为 True,则用值0(零)填充dst中src中没有匹配字段的字段。这是numpy<=1.13的行为。如果为false,则不修改这些字段。 -
numpy.lib.recfunctions.drop_fields(base, drop_names, usemask=True, asrecarray=False)[点击查看源码]
返回一个新数组,其中 drop_names 中的字段已删除。
支持嵌套字段。
参数名 数据类型 描述 base array 输入的数组 drop_names string or sequence 与要删除的字段名称对应的字符串或字符串序列。 usemask {False, True}, optional 是否返回掩码数组。 asrecarray string or sequence, optional 是返回recarray还是mrecarray(asrecarray=True),还是返回具有灵活dtype的普通ndarray或掩码数组。默认值为false。 示例:
>>> from numpy.lib import recfunctions as rfn >>> a = np.array([(1, (2, 3.0)), (4, (5, 6.0))], ... dtype=[('a', np.int64), ('b', [('ba', np.double), ('bb', np.int64)])]) >>> rfn.drop_fields(a, 'a') array([((2., 3),), ((5., 6),)], dtype=[('b', [('ba', ' -
numpy.lib.recfunctions.find_duplicates(a, key=None, ignoremask=True, return_index=False)[点击查看源码]
沿给定键查找结构化数组中的重复项。
参数表:
参数名 数据类型 描述 a array-like 输入的数组 key {string, None}, optional 要检查重复项的字段的名称。如果没有,则按记录执行搜索 ignoremask {True, False}, optional 是否应丢弃淹码数据或将其视为重复数据。 return_index {False, True}, optional 是否返回重复值的索引。 示例:
>>> from numpy.lib import recfunctions as rfn >>> ndtype = [('a', int)] >>> a = np.ma.array([1, 1, 1, 2, 2, 3, 3], ... mask=[0, 0, 1, 0, 0, 0, 1]).view(ndtype) >>> rfn.find_duplicates(a, ignoremask=True, return_index=True) (masked_array(data=[(1,), (1,), (2,), (2,)], mask=[(False,), (False,), (False,), (False,)], fill_value=(999999,), dtype=[('a', ' -
numpy.lib.recfunctions.flatten_descr(ndtype)[点击查看源码]
展平结构化数据类型描述。
示例:
>>> from numpy.lib import recfunctions as rfn >>> ndtype = np.dtype([('a', ' -
numpy.lib.recfunctions.get_fieldstructure(adtype, lastname=None, parents=None)[点击查看源码]
返回一个字典,其中的字段索引其父字段的列表。
此函数用于简化对嵌套在其他字段中的字段的访问。
参数表:
参数名 数据类型 描述 adtype np.dtype 传入数据类型 lastname optional 上次处理的字段名称(在递归过程中内部使用)。 parents dictionary 父字段的字典(在递归期间间隔使用)。 示例:
>>> from numpy.lib import recfunctions as rfn >>> ndtype = np.dtype([('A', int), ... ('B', [('BA', int), ... ('BB', [('BBA', int), ('BBB', int)])])]) >>> rfn.get_fieldstructure(ndtype) ... # XXX: possible regression, order of BBA and BBB is swapped {'A': [], 'B': [], 'BA': ['B'], 'BB': ['B'], 'BBA': ['B', 'BB'], 'BBB': ['B', 'BB']} -
numpy.lib.recfunctions.get_names(adtype)[点击查看源码]
以元组的形式返回输入数据类型的字段名称。
参数表:
参数名 数据类型 描述 adtype dtype 输入数据类型 示例:
>>> from numpy.lib import recfunctions as rfn >>> rfn.get_names(np.empty((1,), dtype=int)) Traceback (most recent call last): ... AttributeError: 'numpy.ndarray' object has no attribute 'names'>>> rfn.get_names(np.empty((1,), dtype=[('A',int), ('B', float)])) Traceback (most recent call last): ... AttributeError: 'numpy.ndarray' object has no attribute 'names' >>> adtype = np.dtype([('a', int), ('b', [('ba', int), ('bb', int)])]) >>> rfn.get_names(adtype) ('a', ('b', ('ba', 'bb'))) -
numpy.lib.recfunctions.get_names_flat(adtype)[点击查看源码]
以元组的形式返回输入数据类型的字段名称。嵌套结构预先展平。
参数表:
参数名 数据类型 描述 adtype dtype 输入数据类型 示例:
>>> from numpy.lib import recfunctions as rfn >>> rfn.get_names_flat(np.empty((1,), dtype=int)) is None Traceback (most recent call last): ... AttributeError: 'numpy.ndarray' object has no attribute 'names' >>> rfn.get_names_flat(np.empty((1,), dtype=[('A',int), ('B', float)])) Traceback (most recent call last): ... AttributeError: 'numpy.ndarray' object has no attribute 'names' >>> adtype = np.dtype([('a', int), ('b', [('ba', int), ('bb', int)])]) >>> rfn.get_names_flat(adtype) ('a', 'b', 'ba', 'bb') -
numpy.lib.recfunctions.join_by(key, r1, r2, jointype=‘inner’, r1postfix=‘1’, r2postfix=‘2’, defaults=None, usemask=True, asrecarray=False)[点击查看源码]
在键(key)上加入数组 r1 和 r2。
键应该是字符串或与用于连接数组的字段相对应的字符串序列。如果在两个输入数组中找不到键字段,则会引发异常。r1 和 r2 都不应该有任何沿着 键 的重复项:重复项的存在将使输出相当不可靠。请注意,算法不会查找重复项。
参数表:
参数名 数据类型 描述 key {string, sequence} 与用于比较的字段相对应的字符串或字符串序列。 r1, r2 arrays 结构化数组。 jointype {‘inner’, ‘outer’, ‘leftouter’}, optional 如果是’inner’,则返回r1和r2共有的元素。 如果是’outer’,则返回公共元素以及不在r2中的r1元素和不在r2中的元素。 如果是’leftouter’,则返回r1中的公共元素和r1的元素。 r1postfix string, optional 附加到r1的字段名称的字符串,这些字段存在于r2中但没有键。 r2postfix string, optional 附加到r1字段名称的字符串,这些字段存在于r1中但没有键。 defaults {dictionary}, optional 字典将字段名称映射到相应的默认值。 usemask {True, False}, optional 是否返回MaskedArray(或MaskedRecords是asrecarray == True)或ndarray。 asrecarray {False, True}, optional 是否返回重新排列(如果usemask == True则返回MaskedRecords)或仅返回灵活类型的ndarray。 提示
- 输出按 key 排序。
- 通过删除不在两个数组的键中的字段并连接结果来形成临时数组。然后对该数组进行排序,并选择公共条目。 通过用所选条目填充字段来构造输出。如果存在一些重复的…,则不保留匹配
-
numpy.lib.recfunctions.merge_arrays(seqarrays, fill_value=-1, flatten=False, usemask=False, asrecarray=False)[点击查看源码]
按字段合并数组。
参数表:
参数名 数据类型 描述 seqarrays sequence of ndarrays 数组序列 fill_value {float}, optional 填充值用于填充较短的数组上的缺失数据。 flatten {False, True}, optional 是否折叠嵌套字段。 usemask {False, True}, optional 是否返回掩码数组。 asrecarray {False, True}, optional 是否返回重新排列(MaskedRecords)。 提示
- 如果没有掩码,将使用某些内容填充缺少的值,具体取决于其对应的类型:
-1对于整数-1.0对于浮点数'-'对于字符'-1'对于字符串True对于布尔值-1对于整数-1.0对于浮点数'-'对于字符'-1'对于字符串True对于布尔值
- XXX: 我只是凭经验获得这些值
示例:
>>> from numpy.lib import recfunctions as rfn >>> rfn.merge_arrays((np.array([1, 2]), np.array([10., 20., 30.]))) array([( 1, 10.), ( 2, 20.), (-1, 30.)], dtype=[('f0', '>>> rfn.merge_arrays((np.array([1, 2], dtype=np.int64), ... np.array([10., 20., 30.])), usemask=False) array([(1, 10.0), (2, 20.0), (-1, 30.0)], dtype=[('f0', ' - 如果没有掩码,将使用某些内容填充缺少的值,具体取决于其对应的类型:
-
numpy.lib.recfunctions.rec_append_fields(base, names, data, dtypes=None)[点击查看源码]
向现有数组添加新字段。
字段的名称使用 names 参数给出,相应的值使用 data 参数。如果追加单个字段,则 names、data 和 dtypes 不必是列表,值就行。
参数表:
参数名 数据类型 描述 base array 要扩展的输入数组。 names string, sequence 与新字段名称对应的字符串或字符串序列。 data array or sequence of arrays 存储要添加到基础的字段的数组或数组序列。 dtypes sequence of datatypes, optional 数据类型或数据类型序列。 如果为None,则根据数据估计数据类型。 返回值:
参数名 数据类型 描述 appended_array np.recarray 略 另见
append_fields -
numpy.lib.recfunctions.rec_drop_fields(base, drop_names)[点击查看源码]
返回一个新的 numpy.recarray,其中 drop_names 中的字段已删除。
-
numpy.lib.recfunctions.rec_join(key, r1, r2, jointype=‘inner’, r1postfix=‘1’, r2postfix=‘2’, defaults=None)[点击查看源码]
在键上加入数组 r1 和 r2。join_by的替代方法,它总是返回一个 np.recarray。
另见
join_by -
numpy.lib.recfunctions.recursive_fill_fields(input, output)[点击查看源码]
使用输入中的字段填充输出中的字段,并支持嵌套结构。
参数表:
参数名 数据类型 描述 input ndarray 输入的数组 output ndarray 输出的数组 提示
- 输出应至少与输入的大小相同
示例:
>>> from numpy.lib import recfunctions as rfn >>> a = np.array([(1, 10.), (2, 20.)], dtype=[('A', np.int64), ('B', np.float64)]) >>> b = np.zeros((3,), dtype=a.dtype) >>> rfn.recursive_fill_fields(a, b) array([(1, 10.), (2, 20.), (0, 0.)], dtype=[('A', ' -
numpy.lib.recfunctions.rename_fields(base, namemapper)[点击查看源码]
重命名来自灵活数据类型 ndarray 或 recarray 的字段。
支持嵌套字段。
参数表:
参数名 数据类型 描述 base ndarray 必须修改其字段的输入数组。 namemapper dictionary 将旧字段名映射到新版本的字典对象。 示例:
>>> from numpy.lib import recfunctions as rfn >>> a = np.array([(1, (2, [3.0, 30.])), (4, (5, [6.0, 60.]))], ... dtype=[('a', int),('b', [('ba', float), ('bb', (float, 2))])]) >>> rfn.rename_fields(a, {'a':'A', 'bb':'BB'}) array([(1, (2., [ 3., 30.])), (4, (5., [ 6., 60.]))], dtype=[('A', ' -
numpy.lib.recfunctions.repack_fields(a, align=False, recurse=False)[点击查看源码]
在内存中重新打包结构化数组或dtype的字段。
结构化数据类型的内存布局允许任意字节偏移的字段。这意味着字段可以通过填充字节来分隔,它们的偏移量可以是非单调增加的,并且它们可以重叠。
此方法删除所有重叠并重新排序内存中的字段,使它们具有增加的字节偏移量,并根据 align选项添加或删除填充字节,该选项的行为类似于
np.dtype的 align 选项。如果 align=False,则此方法生成“压缩”内存布局,其中每个字段从前一个字段结束的字节开始,并删除所有填充字节。
如果 align=True,则此方法通过根据需要添加填充字节来生成 “对齐” 内存布局,其中每个字段的偏移量是其对齐方式的倍数,而总项目大小是最大对齐方式的倍数。
参数表:
参数名 数据类型 描述 a ndarray or dtype 要重新打包字段的数组或数据类型。 align boolean 如果为真,则使用“对齐”内存布局,否则使用“打包”布局。 recurse boolean 如果为True,还会重新打包嵌套结构。 返回值:
参数名 数据类型 描述 repacked ndarray or dtype 带字段重新打包的副本,如果不需要重新打包,则副本本身。 示例:
>>> from numpy.lib import recfunctions as rfn >>> def print_offsets(d): ... print("offsets:", [d.fields[name][1] for name in d.names]) ... print("itemsize:", d.itemsize) ... >>> dt = np.dtype('u1, -
numpy.lib.recfunctions.require_fields(array, required_dtype)[点击查看源码]
使用字段名赋值将结构化数组强制转换为新的dtype。
此函数按名称从旧数组分配到新数组,因此输出数组中字段的值是源数组中具有相同名称的字段的值。这具有创建新的ndarray的效果,该ndarray仅包含Required_dtype“必需”的字段。
如果在输入数组中不存在Required_dtype中的字段名称,则会在输出数组中创建该字段并将其设置为0。
参数表:
参数名 数据类型 描述 a ndarray 要强制转换的数组 required_dtype dtype 输出数组的数据类型 Returns:
参数名 数据类型 描述 out ndarray 具有新dtype的数组,具有从具有相同名称的输入数组中的字段复制的字段值 示例:
>>> from numpy.lib import recfunctions as rfn >>> a = np.ones(4, dtype=[('a', 'i4'), ('b', 'f8'), ('c', 'u1')]) >>> rfn.require_fields(a, [('b', 'f4'), ('c', 'u1')]) array([(1., 1), (1., 1), (1., 1), (1., 1)], dtype=[('b', ' -
numpy.lib.recfunctions.stack_arrays(arrays, defaults=None, usemask=True, asrecarray=False, autoconvert=False)[点击查看源码]
按字段叠加数组字段
参数表:
参数名 数据类型 描述 arrays array or sequence 输入数组序列。 defaults dictionary, optional 字典将字段名称映射到相应的默认值。 usemask {True, False}, optional 是否返回MaskedArray(或MaskedRecords为asrecarray=True)或ndarray。 asrecarray {False, True}, optional 是返回一个recarray(如果usemask=True则返回MaskedRecords),还是只返回一个灵活类型的ndarray。 autoconvert {False, True}, optional 是否自动将字段类型强制转换为最大值。 示例:
>>> from numpy.lib import recfunctions as rfn >>> x = np.array([1, 2,]) >>> rfn.stack_arrays(x) is x True >>> z = np.array([('A', 1), ('B', 2)], dtype=[('A', '|S3'), ('B', float)]) >>> zz = np.array([('a', 10., 100.), ('b', 20., 200.), ('c', 30., 300.)], ... dtype=[('A', '|S3'), ('B', np.double), ('C', np.double)]) >>> test = rfn.stack_arrays((z,zz)) >>> test masked_array(data=[(b'A', 1.0, --), (b'B', 2.0, --), (b'a', 10.0, 100.0), (b'b', 20.0, 200.0), (b'c', 30.0, 300.0)], mask=[(False, False, True), (False, False, True), (False, False, False), (False, False, False), (False, False, False)], fill_value=(b'N/A', 1.e+20, 1.e+20), dtype=[('A', 'S3'), ('B', ' -
numpy.lib.recfunctions.structured_to_unstructured(arr, dtype=None, copy=False, casting=‘unsafe’)[点击查看源码]
将和n-D结构化数组转换为(n+1)-D非结构化数组。
新的数组将具有新的最后一个维度,其大小等于输入数组的字段元素的数量。如果未提供,则根据应用于所有字段数据类型的numpy类型提升规则确定输出数据类型。
嵌套字段以及任何子数组字段的每个元素都算作单个字段元素。
参数表:
参数名 数据类型 描述 arr ndarray 要转换的结构化数组或数据类型。不能包含对象数据类型。 dtype dtype, optional 输出非结构化数组的数据类型。 copy bool, optional 请参见将参数复制到ndarray.astype。如果为true,则始终返回副本。如果为false,并且满足dtype要求,则返回视图。 casting {‘no’, ‘equiv’, ‘safe’, ‘same_kind’, ‘unsafe’}, optional 请参见转换ndarray.astype的参数。控制可能发生的数据转换类型。 返回值:
参数名 数据类型 描述 unstructured ndarray 多一维的非结构化数组。 示例:
>>> from numpy.lib import recfunctions as rfn >>> a = np.zeros(4, dtype=[('a', 'i4'), ('b', 'f4,u2'), ('c', 'f4', 2)]) >>> a array([(0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.])], dtype=[('a', '>>> b = np.array([(1, 2, 5), (4, 5, 7), (7, 8 ,11), (10, 11, 12)], ... dtype=[('x', 'i4'), ('y', 'f4'), ('z', 'f8')]) >>> np.mean(rfn.structured_to_unstructured(b[['x', 'z']]), axis=-1) array([ 3. , 5.5, 9. , 11. ]) -
numpy.lib.recfunctions.unstructured_to_structured(arr, dtype=None, names=None, align=False, copy=False, casting=‘unsafe’)[点击查看源码]
将n-D非结构化数组转换为(n-1)-D结构化数组。
输入数组的最后一维被转换为结构,字段元素的数量等于输入数组的最后一维的大小。默认情况下,所有输出字段都具有输入数组的dtype,但是可以提供具有相等数量的field-element的输出结构化dtype。
嵌套字段以及任何子数组字段的每个元素都计入字段元素的数量。
参数表:
参数名 数据类型 描述 arr ndarray 要转换的非结构化数组或数据类型。 dtype dtype, optional 输出数组的结构化数据类型。 names list of strings, optional 如果未提供dtype,则按顺序指定输出dtype的字段名称。字段dtype将与输入数组相同。 align boolean, optional 是否创建对齐的内存布局。 copy bool, optional 请参见将参数复制到ndarray.astype。如果为true,则始终返回副本。如果为false,并且满足dtype要求,则返回视图。 casting {‘no’, ‘equiv’, ‘safe’, ‘same_kind’, ‘unsafe’}, optional 请参见转换ndarray.astype的参数。控制可能发生的数据转换类型。 返回值:
参数名 数据类型 描述 structured ndarray 维数较少的结构化数组。 示例:
>>> from numpy.lib import recfunctions as rfn >>> dt = np.dtype([('a', 'i4'), ('b', 'f4,u2'), ('c', 'f4', 2)]) >>> a = np.arange(20).reshape((4,5)) >>> a array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19]]) >>> rfn.unstructured_to_structured(a, dt) array([( 0, ( 1., 2), [ 3., 4.]), ( 5, ( 6., 7), [ 8., 9.]), (10, (11., 12), [13., 14.]), (15, (16., 17), [18., 19.])], dtype=[('a', '
8,编写自定义数组容器
NumPy 的分派机制(在numpy版本v1.16中引入)是编写与numpy API兼容并提供numpy功能的自定义实现的自定义N维数组容器的推荐方法。 应用包括 dask 数组(分布在多个节点上的N维数组) 和 cupy 数组(GPU上的N维数组)。
为了获得编写自定义数组容器的感觉,我们将从一个简单的示例开始,该示例具有相当狭窄的实用程序,但说明了所涉及的概念。
>>> import numpy as np
>>> class DiagonalArray:
... def __init__(self, N, value):
... self._N = N
... self._i = value
... def __repr__(self):
... return f"{self.__class__.__name__}(N={self._N}, value={self._i})"
... def __array__(self):
... return self._i * np.eye(self._N)
...
我们的自定义数组可以实例化,如下所示:
>>> arr = DiagonalArray(5, 1)
>>> arr
DiagonalArray(N=5, value=1)
我们可以使用 numpy.array 或 numpy.asarray, 转换为numpy数组,这将调用它的 __array__ 方法来获得标准 numpy.ndarray。
>>> np.asarray(arr)
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
如果我们使用 numpy 函数对 arr 进行操作,numpy 将再次使用 __array__接口将其转换为数组,然后以通常的方式应用该函数。
>>> np.multiply(arr, 2)
array([[2., 0., 0., 0., 0.],
[0., 2., 0., 0., 0.],
[0., 0., 2., 0., 0.],
[0., 0., 0., 2., 0.],
[0., 0., 0., 0., 2.]])
注意,返回类型是标准 numpy.ndarray。
>>> type(arr)
numpy.ndarray
我们如何通过此函数传递我们的自定义数组类型?Numpy允许类指示它希望通过交互 __array_ufunc__ 和 __array_function__ 以自定义方式处理计算。 让我们一次拿一个,从 __array_ufunc__ 开始。 此方法涵盖 Universal functions (ufunc), 这是一类函数,包括例如 numpy.multiply 和 numpy.sin。
_array_ufunc_ 获得:
ufunc, 一个类似numpy.multiply的函数method,一个字符串,区分numpy.multiply(...)。 以及numpy.multiy.outer、numpy.multiy.accumate等变体。对于常见情况,numpy.multiply(...),method='__call__'。inputs, 可能是不同类型的混合kwargs, 传递给函数的关键字参数
对于这个例子,我们将只处理方法 '__call__。
>>> from numbers import Number
>>> class DiagonalArray:
... def __init__(self, N, value):
... self._N = N
... self._i = value
... def __repr__(self):
... return f"{self.__class__.__name__}(N={self._N}, value={self._i})"
... def __array__(self):
... return self._i * np.eye(self._N)
... def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
... if method == '__call__':
... N = None
... scalars = []
... for input in inputs:
... if isinstance(input, Number):
... scalars.append(input)
... elif isinstance(input, self.__class__):
... scalars.append(input._i)
... if N is not None:
... if N != self._N:
... raise TypeError("inconsistent sizes")
... else:
... N = self._N
... else:
... return NotImplemented
... return self.__class__(N, ufunc(*scalars, **kwargs))
... else:
... return NotImplemented
...
现在让我们的自定义数组类型通过numpy的函数。
>>> arr = DiagonalArray(5, 1)
>>> np.multiply(arr, 3)
DiagonalArray(N=5, value=3)
>>> np.add(arr, 3)
DiagonalArray(N=5, value=4)
>>> np.sin(arr)
DiagonalArray(N=5, value=0.8414709848078965)
此时 arr + 3 不起作用。
>>> arr + 3
TypeError: unsupported operand type(s) for *: 'DiagonalArray' and 'int'
为了支持它,我们需要定义Python接口 __add__, __lt__ 等,以便调度到相应的ufunc。 我们可以通过继承mixin NDArrayOperatorsMixin 来方便地实现这一点。
>>> import numpy.lib.mixins
>>> class DiagonalArray(numpy.lib.mixins.NDArrayOperatorsMixin):
... def __init__(self, N, value):
... self._N = N
... self._i = value
... def __repr__(self):
... return f"{self.__class__.__name__}(N={self._N}, value={self._i})"
... def __array__(self):
... return self._i * np.eye(self._N)
... def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
... if method == '__call__':
... N = None
... scalars = []
... for input in inputs:
... if isinstance(input, Number):
... scalars.append(input)
... elif isinstance(input, self.__class__):
... scalars.append(input._i)
... if N is not None:
... if N != self._N:
... raise TypeError("inconsistent sizes")
... else:
... N = self._N
... else:
... return NotImplemented
... return self.__class__(N, ufunc(*scalars, **kwargs))
... else:
... return NotImplemented
...
>>> arr = DiagonalArray(5, 1)
>>> arr + 3
DiagonalArray(N=5, value=4)
>>> arr > 0
DiagonalArray(N=5, value=True)
现在让我们来解决 __array_function__。 我们将创建将 numpy 函数映射到我们的自定义变体的 dict。
>>> HANDLED_FUNCTIONS = {}
>>> class DiagonalArray(numpy.lib.mixins.NDArrayOperatorsMixin):
... def __init__(self, N, value):
... self._N = N
... self._i = value
... def __repr__(self):
... return f"{self.__class__.__name__}(N={self._N}, value={self._i})"
... def __array__(self):
... return self._i * np.eye(self._N)
... def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
... if method == '__call__':
... N = None
... scalars = []
... for input in inputs:
... # In this case we accept only scalar numbers or DiagonalArrays.
... if isinstance(input, Number):
... scalars.append(input)
... elif isinstance(input, self.__class__):
... scalars.append(input._i)
... if N is not None:
... if N != self._N:
... raise TypeError("inconsistent sizes")
... else:
... N = self._N
... else:
... return NotImplemented
... return self.__class__(N, ufunc(*scalars, **kwargs))
... else:
... return NotImplemented
... def __array_function__(self, func, types, args, kwargs):
... if func not in HANDLED_FUNCTIONS:
... return NotImplemented
... # Note: this allows subclasses that don't override
... # __array_function__ to handle DiagonalArray objects.
... if not all(issubclass(t, self.__class__) for t in types):
... return NotImplemented
... return HANDLED_FUNCTIONS[func](*args, **kwargs)
...
一个便捷的模式是定义一个可用于向 HANDLED_FUNCTIONS 添加函数的装饰器 实现。
>>> def implements(np_function):
... "Register an __array_function__ implementation for DiagonalArray objects."
... def decorator(func):
... HANDLED_FUNCTIONS[np_function] = func
... return func
... return decorator
...
现在我们为 DiagonalArray 编写numpy函数的实现。 为了完整性,为了支持使用 arr.sum(), 添加一个调用 numpy.sum(self) 的方法 sum,对于 mean 来说也是一样的。
>>> @implements(np.sum)
... def sum(a):
... "Implementation of np.sum for DiagonalArray objects"
... return arr._i * arr._N
...
>>> @implements(np.mean)
... def sum(a):
... "Implementation of np.mean for DiagonalArray objects"
... return arr._i / arr._N
...
>>> arr = DiagonalArray(5, 1)
>>> np.sum(arr)
5
>>> np.mean(arr)
0.2
如果用户尝试使用 HANDLED_FUNCTIONS 中未包含的任何numpy函数, 则numpy将引发 TypeError,表示不支持此操作。 例如,连接两个 DiagonalArrays 不会产生另一个对角线数组,因此不支持它。
>>> np.concatenate([arr, arr])
TypeError: no implementation found for 'numpy.concatenate' on types that implement __array_function__: [<class '__main__.DiagonalArray'>]
另外,我们的 sum 和 mean 实现不接受numpy实现的可选参数。
>>> np.sum(arr, axis=0)
TypeError: sum() got an unexpected keyword argument 'axis'
用户总是可以选择使用 numpy.asarray 转换为普通的 numpy.asarray,并使用标准的numpy。
>>> np.concatenate([np.asarray(arr), np.asarray(arr)])
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
有关自定义数组容器的更完整工作示例,请参阅dask源代码和cupy源代码。
另外可以看一下 NEP 18。
9,子类化ndarray
1)介绍
子类化ndarray相对简单,但与其他Python对象相比,它有一些复杂性。在这个页面上,我们解释了允许你子类化ndarray的机制,以及实现子类的含义。
ndarrays和对象创建
ndarray的子类化很复杂,因为ndarray类的新实例可以以三种不同的方式出现。这些是:
- 显式构造函数调用 - 如
MySubClass(params)。这是Python实例创建的常用途径。 - 查看转换 - 将现有的ndarray转换为给定的子类
- 模板中的新内容 - 从模板实例创建新实例。示例包括从子类化数组返回切片,从ufuncs创建返回类型以及复制数组。有关更多详细信息,请参阅 从模板创建
最后两个是ndarrays的特性 - 为了支持数组切片之类的东西。子类化ndarray的复杂性是由于numpy必须支持后两种实例创建路径的机制。
2)视图投影
视图投影 是标准的ndarray机制,通过它您可以获取任何子类的ndarray,并将该数组的视图作为另一个(指定的)子类返回:
>>> import numpy as np
>>> # create a completely useless ndarray subclass
>>> class C(np.ndarray): pass
>>> # create a standard ndarray
>>> arr = np.zeros((3,))
>>> # take a view of it, as our useless subclass
>>> c_arr = arr.view(C)
>>> type(c_arr)
<class 'C'>
3)从模板创建
当numpy发现它需要从模板实例创建新实例时,ndarray子类的新实例也可以通过与视图投影非常相似的机制来实现。 这个情况的最明显的时候是你正为子类数组切片的时候。例如:
>>> v = c_arr[1:]
>>> type(v) # the view is of type 'C'
<class 'C'>
>>> v is c_arr # but it's a new instance
False
切片是原始 c_arr 数据的 视图 。因此,当我们从ndarray中获取视图时,我们返回一个同一类的新ndarray,它指向原始数据。
在使用ndarrays时还有其它要点,我们需要这样的视图,例如复制数组(c_arr.copy()),创建ufunc输出数组(参见__array_wrap__用于ufuncs和其他函数), 以及减少方法(如c_arr.mean()。
4)视图投影与从模板创建的关系
这些路径都使用相同的机器。我们在这里进行区分,因为它们会为您的方法带来不同的输入。具体来说, 视图投影意味着您已从ndarray的任何潜在子类创建了数组类型的新实例。 从模板创建意味着您已从预先存在的实例创建了类的新实例,例如,允许您跨特定于您的子类的属性进行复制。
5)子类化的含义
如果我们将 ndarray 子类化,我们不仅需要处理数组类型的显式构造,还需要处理视图投影或 从模板创建。NumPy有这样的机制,这种机制使子类化略微不标准。
ndarray用于支持视图和子类中的从模板创建的机制有两个方面。
第一种是使用该ndarray.__new__方法进行对象初始化的主要工作,而不是更常用的__init__方法。第二个是使用该__array_finalize__方法在模板创建视图和新实例后允许子类清理。
**一个简短的Python入门__new__和__init__**
__new__是一个标准的Python方法,如果存在,__init__在我们创建类实例之前调用它。 有关更多详细信息,请参阅python new 文档。
例如,请考虑以下Python代码:
class C(object):
def __new__(cls, *args):
print('Cls in __new__:', cls)
print('Args in __new__:', args)
# The `object` type __new__ method takes a single argument.
return object.__new__(cls)
def __init__(self, *args):
print('type(self) in __init__:', type(self))
print('Args in __init__:', args)
它的意思是我们将会得到:
>>> c = C('hello')
Cls in __new__: <class 'C'>
Args in __new__: ('hello',)
type(self) in __init__: <class 'C'>
Args in __init__: ('hello',)
当我们调用时C('hello'),该__new__方法获得自己的类作为第一个参数,并传递参数,即字符串 'hello'。在python调用之后__new__,它通常(见下文)调用我们的__init__方法,输出__new__为第一个参数(现在是一个类实例),以及后面传递的参数。
如您所见,对象可以在__new__ 方法或__init__方法中初始化,或者两者兼而有之,实际上ndarray没有__init__方法,因为所有初始化都是在__new__方法中完成的。
为什么要使用__new__而不仅仅是平常__init__?因为在某些情况下,对于ndarray,我们希望能够返回其他类的对象。考虑以下:
class D(C):
def __new__(cls, *args):
print('D cls is:', cls)
print('D args in __new__:', args)
return C.__new__(C, *args)
def __init__(self, *args):
# we never get here
print('In D __init__')
意思是:
>>> obj = D('hello')
D cls is: <class 'D'>
D args in __new__: ('hello',)
Cls in __new__: <class 'C'>
Args in __new__: ('hello',)
>>> type(obj)
<class 'C'>
定义C与之前相同,但是,对于D,该 __new__方法返回类的实例C而不是 D。请注意,该__init__方法D不会被调用。通常,当__new__方法返回类的对象而不是定义__init__ 它的类时,不调用该类的方法。
这就是ndarray类的子类如何能够返回保留类类型的视图。在进行视图时,标准的ndarray机器会创建新的ndarray对象,例如:
obj = ndarray.__new__(subtype, shape, ...
subdtype子类在哪里。因此,返回的视图与子类属于同一类,而不是类ndarray。
这解决了返回相同类型的视图的问题,但是现在我们有了一个新的问题。 ndarray的机制可以这样设置类,在其用于获取视图的标准方法中, 但是ndarray __new__ 方法不知道我们在自己的 __new__ 方法中为了设置属性所做的任何事情, 等等。(抛开-为什么不调用 obj = subdtype._new_(... 然后?。因为我们可能没有具有相同调用签名的 __new__ 方法)。
__array_finalize__ 的作用
__array_finalize__ 是numpy提供的机制,允许子类处理创建新实例的各种方法。
请记住,子类实例可以通过以下三种方式实现:
- 显式的调用构造函数(
obj = MySubClass(params))。 这将调用MySubClass.__ new__的常用序列,然后(如果存在)MySubClass.__init__。 - 视图投影
- 从模板创建
我们的 MySubClass.__new__ 方法只在显式构造函数调用的情况下被调用, 所以我们不能依赖 MySubClass.__new__ 或 MySubClass.__init__ 来处理视图转换和从模板创建。事实证明,MySubClass.__array_finalize__ 确实为对象创建的所有三种方法都被调用,所以这是我们的对象创建内务通常去的地方。
- 对于显式构造函数调用,我们的子类需要创建自己的类的新ndarray实例。 在实践中,这意味着我们作为代码的作者将需要调用
ndarray.__new__(MySubClass,...), 一个类层次结构调用super(MySubClass, cls).__new__(cls, ...), 或者查看现有数组的转换(见下文) - 对于视图转换和从模板创建
ndarray.__new__(MySubClass,...,在C级别调用等效项。
对于上述三种实例创建方法,__array_finalize__ 接收的参数不同。
以下代码允许我们查看调用序列和参数:
import numpy as np
class C(np.ndarray):
def __new__(cls, *args, **kwargs):
print('In __new__ with class %s' % cls)
return super(C, cls).__new__(cls, *args, **kwargs)
def __init__(self, *args, **kwargs):
# in practice you probably will not need or want an __init__
# method for your subclass
print('In __init__ with class %s' % self.__class__)
def __array_finalize__(self, obj):
print('In array_finalize:')
print(' self type is %s' % type(self))
print(' obj type is %s' % type(obj))
现在:
>>> # Explicit constructor
>>> c = C((10,))
In __new__ with class <class 'C'>
In array_finalize:
self type is <class 'C'>
obj type is <type 'NoneType'>
In __init__ with class <class 'C'>
>>> # View casting
>>> a = np.arange(10)
>>> cast_a = a.view(C)
In array_finalize:
self type is <class 'C'>
obj type is <type 'numpy.ndarray'>
>>> # Slicing (example of 从模板创建)
>>> cv = c[:1]
In array_finalize:
self type is <class 'C'>
obj type is <class 'C'>
签名__array_finalize__是:
def __array_finalize__(self, obj):
可以看到进行的super调用 ndarray.__new__传递__array_finalize__了我们自己的class(self)的新对象以及从中获取视图的对象(obj)。从上面的输出可以看出,self它总是一个新创建的子类实例,并且obj 三种实例创建方法的类型不同:
- 从显式构造函数调用时,
obj是None - 从视图转换中调用时,
obj可以是ndarray的任何子类的实例,包括我们自己的子类。 - 在从模板创建中调用时,
obj是我们自己的子类的另一个实例,我们可能会用它来更新新self实例。
因为__array_finalize__是唯一始终看到正在创建新实例的方法,所以在其他任务中填充新对象属性的实例默认值是合理的。
通过一个例子,这可能更清楚。
6)简单示例 —— 向ndarray添加额外属性
import numpy as np
class InfoArray(np.ndarray):
def __new__(subtype, shape, dtype=float, buffer=None, offset=0,
strides=None, order=None, info=None):
# Create the ndarray instance of our type, given the usual
# ndarray input arguments. This will call the standard
# ndarray constructor, but return an object of our type.
# It also triggers a call to InfoArray.__array_finalize__
obj = super(InfoArray, subtype).__new__(subtype, shape, dtype,
buffer, offset, strides,
order)
# set the new 'info' attribute to the value passed
obj.info = info
# Finally, we must return the newly created object:
return obj
def __array_finalize__(self, obj):
# ``self`` is a new object resulting from
# ndarray.__new__(InfoArray, ...), therefore it only has
# attributes that the ndarray.__new__ constructor gave it -
# i.e. those of a standard ndarray.
#
# We could have got to the ndarray.__new__ call in 3 ways:
# From an explicit constructor - e.g. InfoArray():
# obj is None
# (we're in the middle of the InfoArray.__new__
# constructor, and self.info will be set when we return to
# InfoArray.__new__)
if obj is None: return
# From view casting - e.g arr.view(InfoArray):
# obj is arr
# (type(obj) can be InfoArray)
# From 从模板创建 - e.g infoarr[:3]
# type(obj) is InfoArray
#
# Note that it is here, rather than in the __new__ method,
# that we set the default value for 'info', because this
# method sees all creation of default objects - with the
# InfoArray.__new__ constructor, but also with
# arr.view(InfoArray).
self.info = getattr(obj, 'info', None)
# We do not need to return anything
使用该对象如下所示:
>>> obj = InfoArray(shape=(3,)) # explicit constructor
>>> type(obj)
<class 'InfoArray'>
>>> obj.info is None
True
>>> obj = InfoArray(shape=(3,), info='information')
>>> obj.info
'information'
>>> v = obj[1:] # 从模板创建 - here - slicing
>>> type(v)
<class 'InfoArray'>
>>> v.info
'information'
>>> arr = np.arange(10)
>>> cast_arr = arr.view(InfoArray) # view casting
>>> type(cast_arr)
<class 'InfoArray'>
>>> cast_arr.info is None
True
这个类不是很有用,因为它与裸ndarray对象具有相同的构造函数,包括传入缓冲区和形状等等。我们可能更喜欢构造函数能够从通常的numpy调用中获取已经形成的ndarray np.array并返回一个对象。
7)稍微更现实的例子 —— 添加到现有数组的属性
这是一个类,它采用已经存在的标准ndarray,转换为我们的类型,并添加一个额外的属性。
import numpy as np
class RealisticInfoArray(np.ndarray):
def __new__(cls, input_array, info=None):
# Input array is an already formed ndarray instance
# We first cast to be our class type
obj = np.asarray(input_array).view(cls)
# add the new attribute to the created instance
obj.info = info
# Finally, we must return the newly created object:
return obj
def __array_finalize__(self, obj):
# see InfoArray.__array_finalize__ for comments
if obj is None: return
self.info = getattr(obj, 'info', None)
所以:
>>> arr = np.arange(5)
>>> obj = RealisticInfoArray(arr, info='information')
>>> type(obj)
<class 'RealisticInfoArray'>
>>> obj.info
'information'
>>> v = obj[1:]
>>> type(v)
<class 'RealisticInfoArray'>
>>> v.info
'information'
8)__array_ufunc__ 对于ufuncs
版本1.13中的新功能。
子类可以覆盖在通过覆盖默认ndarray.__array_ufunc__方法对其执行numpy ufuncs时发生的情况。执行此方法 而不是 ufunc,并且应该返回操作的结果, 或者NotImplemented如果未执行所请求的操作。
签名 __array_ufunc__ 是:
def __array_ufunc__(ufunc, method, *inputs, **kwargs):
- *ufunc* is the ufunc object that was called.
- *method* is a string indicating how the Ufunc was called, either
``"__call__"`` to indicate it was called directly, or one of its
:ref:`methods<ufuncs.methods>`: ``"reduce"``, ``"accumulate"``,
``"reduceat"``, ``"outer"``, or ``"at"``.
- *inputs* is a tuple of the input arguments to the ``ufunc``
- *kwargs* contains any optional or keyword arguments passed to the
function. This includes any ``out`` arguments, which are always
contained in a tuple.
典型的实现将转换作为一个人自己的类的实例的任何输入或输出,使用所有内容传递给超类super(),并最终在可能的反向转换后返回结果。举例来说,来自测试案例采取test_ufunc_override_with_super在core/tests/test_umath.py,如下。
input numpy as np
class A(np.ndarray):
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
args = []
in_no = []
for i, input_ in enumerate(inputs):
if isinstance(input_, A):
in_no.append(i)
args.append(input_.view(np.ndarray))
else:
args.append(input_)
outputs = kwargs.pop('out', None)
out_no = []
if outputs:
out_args = []
for j, output in enumerate(outputs):
if isinstance(output, A):
out_no.append(j)
out_args.append(output.view(np.ndarray))
else:
out_args.append(output)
kwargs['out'] = tuple(out_args)
else:
outputs = (None,) * ufunc.nout
info = {}
if in_no:
info['inputs'] = in_no
if out_no:
info['outputs'] = out_no
results = super(A, self).__array_ufunc__(ufunc, method,
*args, **kwargs)
if results is NotImplemented:
return NotImplemented
if method == 'at':
if isinstance(inputs[0], A):
inputs[0].info = info
return
if ufunc.nout == 1:
results = (results,)
results = tuple((np.asarray(result).view(A)
if output is None else output)
for result, output in zip(results, outputs))
if results and isinstance(results[0], A):
results[0].info = info
return results[0] if len(results) == 1 else results
所以,这个类实际上并没有做任何有趣的事情:它只是将它自己的任何实例转换为常规的ndarray(否则,我们将获得无限递归!),并添加一个info字典,告诉它转换了哪些输入和输出。因此,例如,
>>> a = np.arange(5.).view(A)
>>> b = np.sin(a)
>>> b.info
{'inputs': [0]}
>>> b = np.sin(np.arange(5.), out=(a,))
>>> b.info
{'outputs': [0]}
>>> a = np.arange(5.).view(A)
>>> b = np.ones(1).view(A)
>>> c = a + b
>>> c.info
{'inputs': [0, 1]}
>>> a += b
>>> a.info
{'inputs': [0, 1], 'outputs': [0]}
请注意,另一种方法是使用 getattr(ufunc,method)(*input,*kwargs) 而不是 super call。 对于本例,结果是相同的,但如果另一个操作数也定义了 __array_ufunc__ ,则会有所不同。 例如,假设我们评估 np.add(a,b),其中b是具有覆盖的另一个类B的实例。 如果在示例中使用super,ndarray.__array_ufunc__ 会注意到b具有覆盖,这意味着它不能计算结果本身。 因此,它将返回 NotImplemented ,我们的类A也将如此。 然后,控制权将传递给 b,b 要么知道如何处理我们并产生结果,要么不知道并返回 NotImplemented,从而引发 TypeError。
相反,如果我们用 getattr(ufunc,method) 替换 super call,我们将有效地执行 np.add(a.view(np.ndarray),b)。 同样,将调用 B.__array_ufunc__,但现在它将 ndarray视为另一个参数。 很可能,它将知道如何处理此问题,并将B类的新实例返回给我们。 我们的示例类没有设置为处理此问题,但如果例如使用 __array_ufunc__ 重新实现 MaskedArray,这可能是最好的方法。
最后要注意:如果 super 路由适合给定的类,使用它的一个优点是它有助于构造类层次结构。 例如,假设我们的其他类B在其 __array_ufunc__ 实现中也使用了 super, 并且我们创建了一个依赖于它们的类 C,即 calss C(A, B)(为简单起见,没有另一个 __array_ufunc__ 覆盖)。 然后,C实例上的任何ufunc都将传递给 A.__ array_ufunc__, A 中的超级调用将转到 B.__ array_ufunc__, 而 B 中的 super call 将转到 ndarray.__array_ufunc__ ,从而允许 A和 B 协作。
9)__array_wrap__用于ufuncs和其他函数
在numpy 1.13之前,ufuncs的行为只能使用 __array_wrap__ 和 __array_prepare__ 来调优。 这两个允许一个更改ufunc的输出类型,但与 __array_ufunc__ 相反,不允许对输入进行任何更改。 希望最终淘汰这些功能,但是其他 numpy 函数和方法也使用 __array_wrap__ ,例如 squeeze,因此目前仍然需要完整的功能。
从概念上讲,__array_wrap__ “包装动作” 的意义是允许子类设置返回值的类型并更新属性和元数据。 让我们用一个例子来说明它是如何工作的。首先,我们返回到更简单的Example子类,但具有不同的名称和一些print语句:
import numpy as np
class MySubClass(np.ndarray):
def __new__(cls, input_array, info=None):
obj = np.asarray(input_array).view(cls)
obj.info = info
return obj
def __array_finalize__(self, obj):
print('In __array_finalize__:')
print(' self is %s' % repr(self))
print(' obj is %s' % repr(obj))
if obj is None: return
self.info = getattr(obj, 'info', None)
def __array_wrap__(self, out_arr, context=None):
print('In __array_wrap__:')
print(' self is %s' % repr(self))
print(' arr is %s' % repr(out_arr))
# then just call the parent
return super(MySubClass, self).__array_wrap__(self, out_arr, context)
我们在新数组的实例上运行ufunc:
>>> obj = MySubClass(np.arange(5), info='spam')
In __array_finalize__:
self is MySubClass([0, 1, 2, 3, 4])
obj is array([0, 1, 2, 3, 4])
>>> arr2 = np.arange(5)+1
>>> ret = np.add(arr2, obj)
In __array_wrap__:
self is MySubClass([0, 1, 2, 3, 4])
arr is array([1, 3, 5, 7, 9])
In __array_finalize__:
self is MySubClass([1, 3, 5, 7, 9])
obj is MySubClass([0, 1, 2, 3, 4])
>>> ret
MySubClass([1, 3, 5, 7, 9])
>>> ret.info
'spam'
注意,ufunc(np.add) 调用了 __array_WRAP__ 方法,参数 self 作为 obj,out_arr作为加法的(ndarray)结果。 反过来,默认 __array_wrap__(ndarray._array_warp__) 已将结果强制转换为类 MySubClass,并调用 __array_finalize__ - 因此复制了info属性。这一切都发生在C级。
但是,我们可以做任何我们想要的事情:
class SillySubClass(np.ndarray):
def __array_wrap__(self, arr, context=None):
return 'I lost your data'
>>> arr1 = np.arange(5)
>>> obj = arr1.view(SillySubClass)
>>> arr2 = np.arange(5)
>>> ret = np.multiply(obj, arr2)
>>> ret
'I lost your data'
因此,通过__array_wrap__为我们的子类定义一个特定的方法,我们可以调整ufuncs的输出。 该__array_wrap__方法需要self,然后是一个参数 - 这是ufunc的结果 - 和一个可选的参数 上下文 。 ufuncs 将此参数作为 3 元素元组返回:( ufunc的名称,ufunc的参数,ufunc的域), 但不是由其他numpy函数设置的。但是,如上所述,可以做其他事情,__array_wrap__应该返回其包含类的实例。 请参阅 masked 数组子类以获取实现。
除了 __array_wrap__ 在ufunc 之外调用之外, 还有一个 __array_prepare__ 方法在创建输出数组之后但在执行任何计算之前调用ufunc。 默认实现除了通过数组之外什么都不做。__array_prepare__ 不应尝试访问数组数据或调整数组大小, 它用于设置输出数组类型,更新属性和元数据,以及根据计算开始之前可能需要的输入执行任何检查。 比如__array_wrap__,__array_prepare__必须返回一个ndarray或其子类或引发错误。
10)额外的坑 —— 自定义的 __del__ 方法和 ndarray.base
ndarray解决的问题之一是跟踪ndarray的内存所有权及其视图。 考虑这样的情况,我们已经创建了ndarray,arr 并使用 v = arr[1:]获取了一个切片。 这两个对象看的是相同的内存。NumPy使用base属性跟踪特定数组或视图的数据来自何处:
>>> # A normal ndarray, that owns its own data
>>> arr = np.zeros((4,))
>>> # In this case, base is None
>>> arr.base is None
True
>>> # We take a view
>>> v1 = arr[1:]
>>> # base now points to the array that it derived from
>>> v1.base is arr
True
>>> # Take a view of a view
>>> v2 = v1[1:]
>>> # base points to the view it derived from
>>> v2.base is v1
True
一般来说,如果数组拥有自己的内存, 就像arr在这种情况下那样, 那么arr.base 将是None - 有一些例外 -—— 请参阅numpy书了解更多细节。
该base属性可用于判断我们是否有视图或原始数组。 如果我们需要知道在删除子类数组时是否进行某些特定的清理,这反过来会很有用。 例如,如果删除原始数组,我们可能只想进行清理,而不是视图。有关如何工作的示例,请查看 numpy.core 中的 memmap 类。
11)子类和下游兼容性
当子类化 ndarray 或创建模仿 ndarray 接口的 duck-types 时, 您的任务是决定您的API与numpy的API将如何对齐。 为方便起见,许多具有相应ndarray方法(例如,sum,mean,take,reshape)的Numpy函数通过检查函数的第一个参数是否具有同名的方法来工作。 如果存在,则调用该方法,而不是将参数强制到numpy数组。
例如,如果您希望子类或 duck-type 与 numpy 的 sum 函数兼容,则此对象sum方法的方法签名应如下所示:
def sum(self, axis=None, dtype=None, out=None, keepdims=False):
...
这是 np.sum 的完全相同的方法签名, 所以现在如果用户在这个对象上调用 np.sum,numpy 将调用该对象自己的 sum 方法, 并在签名中传递上面枚举的这些参数,并且不会引发错误,因为签名彼此完全兼容。
但是,如果您决定偏离此签名并执行以下操作:
def sum(self, axis=None, dtype=None):
...
此对象不再兼容,np.sum因为如果调用np.sum,它将传递意外的参数,out并keepdims导致引发 TypeError。
如果你希望保持与 numpy 及其后续版本(可能添加新的关键字参数)的兼容性, 但又不想显示所有numpy的参数,那么你的函数的签名应该接受**kwargs。例如:
def sum(self, axis=None, dtype=None, **unused_kwargs):
...
__ array_ufunc__, 而 B 中的supercall 将转到ndarray.array_ufunc,从而允许A和B` 协作。
9)__array_wrap__用于ufuncs和其他函数
在numpy 1.13之前,ufuncs的行为只能使用 __array_wrap__ 和 __array_prepare__ 来调优。 这两个允许一个更改ufunc的输出类型,但与 __array_ufunc__ 相反,不允许对输入进行任何更改。 希望最终淘汰这些功能,但是其他 numpy 函数和方法也使用 __array_wrap__ ,例如 squeeze,因此目前仍然需要完整的功能。
从概念上讲,__array_wrap__ “包装动作” 的意义是允许子类设置返回值的类型并更新属性和元数据。 让我们用一个例子来说明它是如何工作的。首先,我们返回到更简单的Example子类,但具有不同的名称和一些print语句:
import numpy as np
class MySubClass(np.ndarray):
def __new__(cls, input_array, info=None):
obj = np.asarray(input_array).view(cls)
obj.info = info
return obj
def __array_finalize__(self, obj):
print('In __array_finalize__:')
print(' self is %s' % repr(self))
print(' obj is %s' % repr(obj))
if obj is None: return
self.info = getattr(obj, 'info', None)
def __array_wrap__(self, out_arr, context=None):
print('In __array_wrap__:')
print(' self is %s' % repr(self))
print(' arr is %s' % repr(out_arr))
# then just call the parent
return super(MySubClass, self).__array_wrap__(self, out_arr, context)
我们在新数组的实例上运行ufunc:
>>> obj = MySubClass(np.arange(5), info='spam')
In __array_finalize__:
self is MySubClass([0, 1, 2, 3, 4])
obj is array([0, 1, 2, 3, 4])
>>> arr2 = np.arange(5)+1
>>> ret = np.add(arr2, obj)
In __array_wrap__:
self is MySubClass([0, 1, 2, 3, 4])
arr is array([1, 3, 5, 7, 9])
In __array_finalize__:
self is MySubClass([1, 3, 5, 7, 9])
obj is MySubClass([0, 1, 2, 3, 4])
>>> ret
MySubClass([1, 3, 5, 7, 9])
>>> ret.info
'spam'
注意,ufunc(np.add) 调用了 __array_WRAP__ 方法,参数 self 作为 obj,out_arr作为加法的(ndarray)结果。 反过来,默认 __array_wrap__(ndarray._array_warp__) 已将结果强制转换为类 MySubClass,并调用 __array_finalize__ - 因此复制了info属性。这一切都发生在C级。
但是,我们可以做任何我们想要的事情:
class SillySubClass(np.ndarray):
def __array_wrap__(self, arr, context=None):
return 'I lost your data'
>>> arr1 = np.arange(5)
>>> obj = arr1.view(SillySubClass)
>>> arr2 = np.arange(5)
>>> ret = np.multiply(obj, arr2)
>>> ret
'I lost your data'
因此,通过__array_wrap__为我们的子类定义一个特定的方法,我们可以调整ufuncs的输出。 该__array_wrap__方法需要self,然后是一个参数 - 这是ufunc的结果 - 和一个可选的参数 上下文 。 ufuncs 将此参数作为 3 元素元组返回:( ufunc的名称,ufunc的参数,ufunc的域), 但不是由其他numpy函数设置的。但是,如上所述,可以做其他事情,__array_wrap__应该返回其包含类的实例。 请参阅 masked 数组子类以获取实现。
除了 __array_wrap__ 在ufunc 之外调用之外, 还有一个 __array_prepare__ 方法在创建输出数组之后但在执行任何计算之前调用ufunc。 默认实现除了通过数组之外什么都不做。__array_prepare__ 不应尝试访问数组数据或调整数组大小, 它用于设置输出数组类型,更新属性和元数据,以及根据计算开始之前可能需要的输入执行任何检查。 比如__array_wrap__,__array_prepare__必须返回一个ndarray或其子类或引发错误。
10)额外的坑 —— 自定义的 __del__ 方法和 ndarray.base
ndarray解决的问题之一是跟踪ndarray的内存所有权及其视图。 考虑这样的情况,我们已经创建了ndarray,arr 并使用 v = arr[1:]获取了一个切片。 这两个对象看的是相同的内存。NumPy使用base属性跟踪特定数组或视图的数据来自何处:
>>> # A normal ndarray, that owns its own data
>>> arr = np.zeros((4,))
>>> # In this case, base is None
>>> arr.base is None
True
>>> # We take a view
>>> v1 = arr[1:]
>>> # base now points to the array that it derived from
>>> v1.base is arr
True
>>> # Take a view of a view
>>> v2 = v1[1:]
>>> # base points to the view it derived from
>>> v2.base is v1
True
一般来说,如果数组拥有自己的内存, 就像arr在这种情况下那样, 那么arr.base 将是None - 有一些例外 -—— 请参阅numpy书了解更多细节。
该base属性可用于判断我们是否有视图或原始数组。 如果我们需要知道在删除子类数组时是否进行某些特定的清理,这反过来会很有用。 例如,如果删除原始数组,我们可能只想进行清理,而不是视图。有关如何工作的示例,请查看 numpy.core 中的 memmap 类。
11)子类和下游兼容性
当子类化 ndarray 或创建模仿 ndarray 接口的 duck-types 时, 您的任务是决定您的API与numpy的API将如何对齐。 为方便起见,许多具有相应ndarray方法(例如,sum,mean,take,reshape)的Numpy函数通过检查函数的第一个参数是否具有同名的方法来工作。 如果存在,则调用该方法,而不是将参数强制到numpy数组。
例如,如果您希望子类或 duck-type 与 numpy 的 sum 函数兼容,则此对象sum方法的方法签名应如下所示:
def sum(self, axis=None, dtype=None, out=None, keepdims=False):
...
这是 np.sum 的完全相同的方法签名, 所以现在如果用户在这个对象上调用 np.sum,numpy 将调用该对象自己的 sum 方法, 并在签名中传递上面枚举的这些参数,并且不会引发错误,因为签名彼此完全兼容。
但是,如果您决定偏离此签名并执行以下操作:
def sum(self, axis=None, dtype=None):
...
此对象不再兼容,np.sum因为如果调用np.sum,它将传递意外的参数,out并keepdims导致引发 TypeError。
如果你希望保持与 numpy 及其后续版本(可能添加新的关键字参数)的兼容性, 但又不想显示所有numpy的参数,那么你的函数的签名应该接受**kwargs。例如:
def sum(self, axis=None, dtype=None, **unused_kwargs):
...
此对象现在再次与 np.sum 兼容,因为任何无关的参数(即不是 axis 或 dtype 的关键字)都将隐藏在 *unused_kwargs 参数中。