mac下hive的安装步骤
1、在安装hive之前要先安装hadoop,具体的安装方法请看:https://blog.csdn.net/sunxiaoju/article/details/86183405
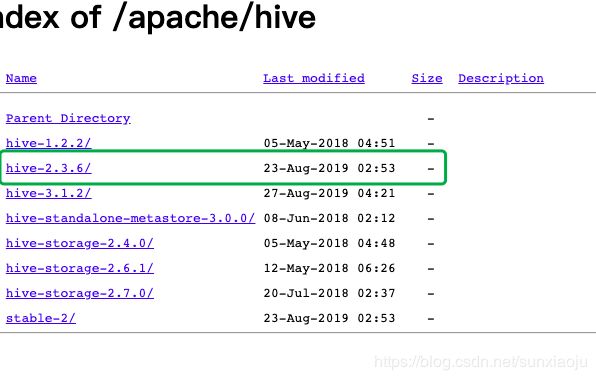
2、从http://mirror.bit.edu.cn/apache/hive/中下载hive,选择2.3.6版本,如下图所示:

3、使用tar -xzvf apache-hive-2.3.6-bin.tar.gz命令解压,如下图所示:

4、使用mv apache-hive-2.3.6-bin hive-2.3.6将原目录更改名称,如下图所示:

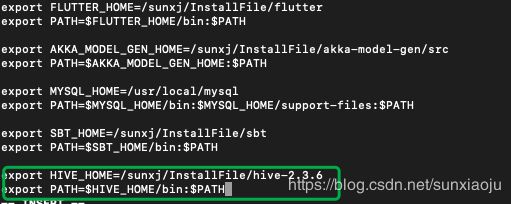
5、修改环境变量,vim /etc/profile,添加环境变量:
export HIVE_HOME=/sunxj/InstallFile/hive-2.3.6
export PATH=$HIVE_HOME/bin:$PATH如下图所示:
6、保存退出,然后执行source /etc/profile,然后执行hive --version查看版本,如下图所示:

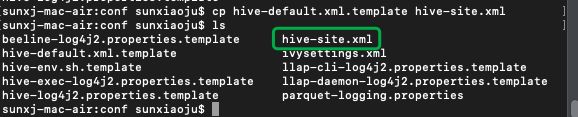
7、修改hive-site.xml,进入到hive的conf目录进行配置,如下图所示:

8、发现没有hive-site.xml,那么只需要通过cp hive-default.xml.template hive-site.xml复制一个即可,如下图所示:
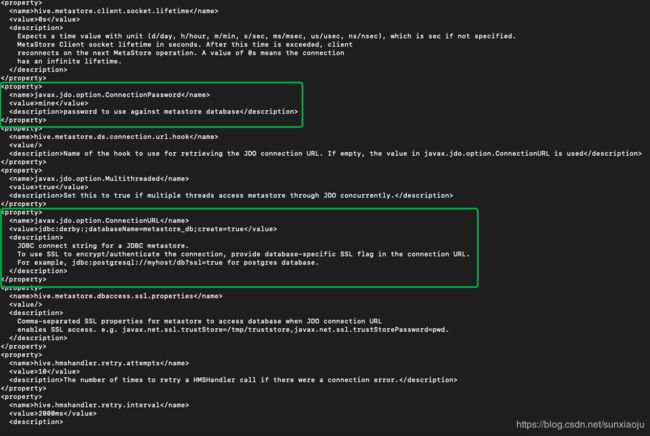
9、开始编辑hive-site.xml,原始文件内容如下:

在property上添加内容如下:

即:
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
javax.jdo.option.ConnectionURL mysql
jdbc:mysql://localhost:3306/hive
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
hive.metastore.schema.verification
false
其中javax.jdo.option.ConnectionUserName表示数据库的用户名
javax.jdo.option.ConnectionPassword表示数据库密码
javax.jdo.option.ConnectionURL表示要连接数据库的url
javax.jdo.option.ConnectionDriverName表示连接数据所用的驱动
这里是以mysql数据库为例
并将以下内容删除:

10、使用命令:cp /sunxj/InstallFile/repo/mvn-repo/mysql/mysql-connector-java/8.0.17/mysql-connector-java-8.0.17.jar lib/ 复制mysql的驱动程序到hive/lib下面。
11、使用mysql -u root -p123456命令进入到mysql中,如下图所示:
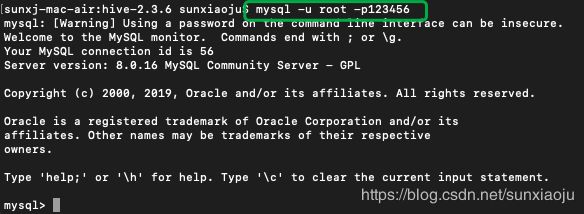
12、在mysql shell中使用create database hive;创建hive数据库,如下图所示:

13、此时hive数据库是空的,如下图所示:

14、然后在终端执行: schematool -dbType mysql -initSchema,如下图所示:

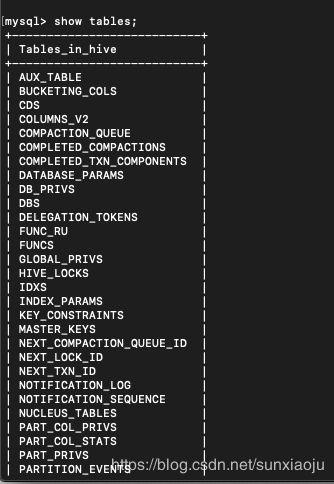
15、此时在mysql数据库中再次执行show tables;即可显示hive初始化信息,如下图所示:
16、然后执行hive,如下图所示:
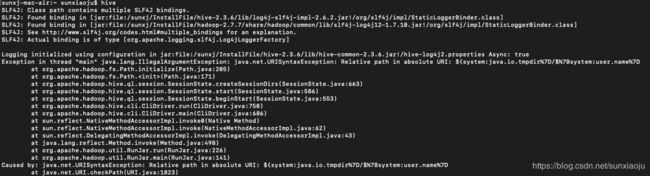
此时会出现如下错误:
Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at org.apache.hadoop.fs.Path.initialize(Path.java:205)
at org.apache.hadoop.fs.Path.(Path.java:171)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:663)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:586)
at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:553)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:750)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:226)
at org.apache.hadoop.util.RunJar.main(RunJar.java:141)
Caused by: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at java.net.URI.checkPath(URI.java:1823)
at java.net.URI.(URI.java:745)
at org.apache.hadoop.fs.Path.initialize(Path.java:202)
... 12 more
17、出现此问题是由于找不到对应的目录,在hive2.6.3目录中创建一个tmp目录,如下图所示:

18、记录目录为:/sunxj/InstallFile/hive-2.3.6/tmp,并修改hive-site.xml文件,将${system:java.io.tmpdir} 全部替换成/sunxj/InstallFile/hive-2.3.6/tmp,将{system:user.name} 替换成{user.name},然后再次执行hive,如下图所示:

19、成功进入hive界面,hive配置完成。
20、通过hadoop fs -lsr /查看hdfs情况,如下图所示:

21、然后在hive shell界面新建一个数据库hive_1,如下图所示:
![]()
22、再次查看hdfs目录情况就会发现多了一个hive_1.db的文件,如下图所示:

23、查看mysql中的hive数据库,如下图所示:

24、由此可见mysql数据库中显示的路径与hdfs显示的相同。
25、在hive_1下创建一个表hive_01,如下图所示:

26、再次查看hdfs目录情况,如下图所示:

27、查看mysql数据库中的信息,如下图所示:

28、打开http://master:50070查看hdfs系统web界面,如下图所示:
29、如果想让spark来读取hive,还必须在hive-site.xml中配置hive.metastore.uris,如下图所示:

30、然后使用hive --service metastore &启动即可,然后就可以访问了。
如果出现以下错误就表示没有启动hive --service metastore &或者代码中没有指定:.config("hive.metastore.uris","thrift://master:9083")
错误如下:
2019-10-06 22:52:07 WARN ObjectStore:568 - Failed to get database spark_test, returning NoSuchObjectException
Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: `spark_test`.`student`; line 1 pos 14;
'Project [*]
+- 'UnresolvedRelation `spark_test`.`student`
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:90)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:85)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:127)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:126)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:126)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:126)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.checkAnalysis(CheckAnalysis.scala:85)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:95)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:108)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at SprkSqlOperateHive$.main(SprkSqlOperateHive.scala:14)
at SprkSqlOperateHive.main(SprkSqlOperateHive.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
31、到此配置完成。