不合理超时设置带来的“坑”
在后台服务的实现中,我们通过基于TCP/UDP协议封装起来的RPC机制实现了跟不同系统的通信,进而协同各个系统完成一系列业务流程和功能的执行,在这个过程中,每个参与合作的子系统都有自己的能力描述,如并发能力,响应速度,接口稳定性和安全级别等。并发能力是其中非常关键的一个指标,我们常用TPS等指标进行描述,表示单位时间内能够处理的事务数量。
在多进程模型中:假如系统启用了n个处理进程,处理单个请求的耗时是xms,那么,每个进程在1s内能够处理的请求数:
单进程1s内处理数量 = 1000/x
则n个处理进程总的大概并发能力:
TPS = n * 1000/x (1)
从式子(1)可以看到:要提升整体系统的并发能力,要么增加处理进程数量,要么减少单个请求的处理时间。
一个方法是单机内增加处理进程,在某种程度能够优化或者缓解整体的并发能力。但当单机进程数量大到某个数量后,简单的增加进程数反而会增加不同进程之间的切换成本,如果存在锁竞争,则效果会更打折扣;另外一种办法是scan out,增加更多的机器,这是一个不错的方案,目前很多的架构优化都是基于某种规则进行打散后分布到更多的机器进行处理,但前提是架构能够支持scan out能力。
另外一个方法是减少单个请求的处理时间。在单机极限性能优化中,这个是关键点,需要深刻挖掘影响处理的各个耗时,对某个具体的用户来说,前面的增加进程数或者scan out并不能很明显的提升单个用户的体验,该用户在某次的请求中的耗时仍然没有优化。在高可用架构和追求极致体验的设计和实现中,我们需要关注每次请求本身的耗时,尽量减少耗时,同时也尽可能的确保服务的稳定性。
减少耗时比较容易理解,但稳定性怎么说?举一个例子:你打开某个网站,如果你能够打开的话,发现速度很快,基本都是1s以内可以返回,但你在这个网站浏览,总是时不时的出现500或者服务异常,那我们说,虽然速度快,但服务是不稳定的。如何提升单次请求或者服务的稳定性呢?由于每次请求都会对多个系统有依赖,比如支付流程,每次支付都有对应的底层100+次的调用,如果其中只要某个调用超时或者异常,则整体服务也是异常的,那么我们认为某个调用或者依赖是关键路径。
因此,关键原则是:要提升稳定性,就必须要解决好关键路径的设计和实现。
根据可用性乘法原理:假设一条关键路径上有N个节点,每个的故障率为r,则按照乘法原理,整体的路径稳定性:(1-r)的N次方,显然优化方法:减少N,减少 r。
一个好的办法就是减少依赖的节点数,即我们常说的弱化关键路径,或者把关键路径变为非关键路径,一旦变为非关键路径,则该节点失败或者异常,对整体服务有一定的降级影响,但不是致命的影响。
到目前为止,我们目前已经能够得出一个非常重要的可用性价值观:弱化关键路径。通过对业务流程的深入分析,把对下游依赖系统的调用进行分级,根据是否对最终用户体验的影响程度划分为关键路径和非关键路径。
- 关键路径:一旦出问题,必定会影响最终用户的体验,因此必须花足够的冗余资源进行设计和实现,确保高可用和高稳定性;
- 非关键路径:一旦出问题,对用户没有致命的影响,因此在实现上考虑进行旁路化—即调用该接口一旦出问题,则忽视它,继续执行下面流程。
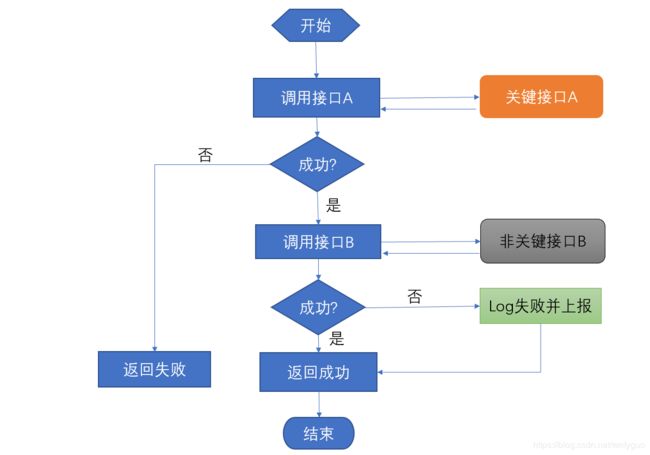
图 1-1 非关键路径的实现
从图1-1可见,对关键接口A的调用,如果失败,则最终结果返回失败,因此,关键接口A需要有足够好的健壮性和稳定性设计;而对非关键接口B的调用,如果失败,只是简单记录Log和上报监控,不影响最终的结果,最终结果还是返回成功给服务调用方。举个例子:在民生应用乘车码中,用户每次是否能够成功拉码非常关键,但如果该用户有欠费行为,则需要先进行还款后才能出码,然而欠费行为的判断需要依赖更多的全局服务,稳定性和全局依赖性更强,为了让拉码流程更短,我们把欠费查询作为非关键路径进行设计,即如果该接口故障,系统会自动绕开,认为用户没有欠费继续给用户先出码,优先保障该用户的本次出行体验。
上面的实现从原理上看是没有太大问题的,我们进一步的剖析具体实现的细节,这次加入了各个接口调用的超时设置。
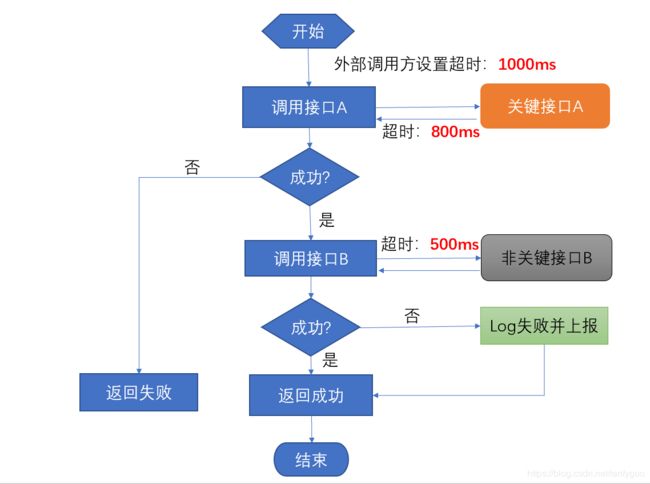
图1-2,加入超时设置的实现路径
图1-2中,我们添加了各个接口的超时设置,假设外面服务调用方设置总体超时是1000ms,
Case 1:在调用第一个关键接口A的时候实际用了300ms,调用非关键接口B的时候,由于该服务挂死无法及时返回,等到超时500ms后才返回,那么总体该流程的耗时是300ms+500ms=800ms < 1000ms,可以正常返回。
Case2:如果在调用关键接口A的时候实际用了600ms,调用非关键接口B的时候需要等到超时500ms才返回,那么总体该流程的耗时是600ms + 500ms = 1100ms > 1000ms,但此时外部调用方已经等不及了,超过1000ms会返回超时,因此此时,该服务的处理对外部服务来说是没有意义的,总体该流程还是失败,虽然A关键接口成功了。
从case 2 的情况可以看到,如果超时设置不合理,哪怕实现上认为是旁路的非关键路径,但在实际场景中,仍然会对最终的服务造成影响,本质是:服务返回虽然是可旁路的,但该接口调用的时间资源是无法旁路的,每个旁路接口的调用都会耗费一定的时间资源,然而总体的时间资源是有限的(等于外部服务调用方设置的总体超时,表示外部服务能够等待的最大耐心)。
问题是:我们有什么好的优化手段吗?
方案A: 设置更合理的超时时间。
一个比较简单的手段就是合理设置各个接口的超时,最好的方式是各个接口的超时相加小于等于外部接口设置的总体超时,旁路接口尽量设置更短的超时,如50ms超时,而把更多的时间资源给到关键接口的调用。 当然,我们需要关注此超时下旁路接口能够成功返回的占比;若是多个旁路接口的情况,则需要更加注意上面的超时关系设置,一个优化手段是合并接口,把多个旁路调用聚合成一个旁路调用(其实就是给到总体旁路接口一个总的时间资源,由他们自己内部竞争,避免多个旁路接口跟外部的关键接口进行时间资源的抢夺);
方案B: 从串行调用改成并行调用。
并行调用的一个好处是时间资源的放大效应,如果我们并行调用各个旁路接口,只要最慢的那个不超过总体超时,则不会对最终结果有挤出影响,当然各个关键接口的调用如果能够并行(考虑前后依赖情况),也遵循同样的时间设置原则,并行关键接口或者串行关键接口超时之和均不超过总体超时,则都是有效的策略,如图1.-3所示。
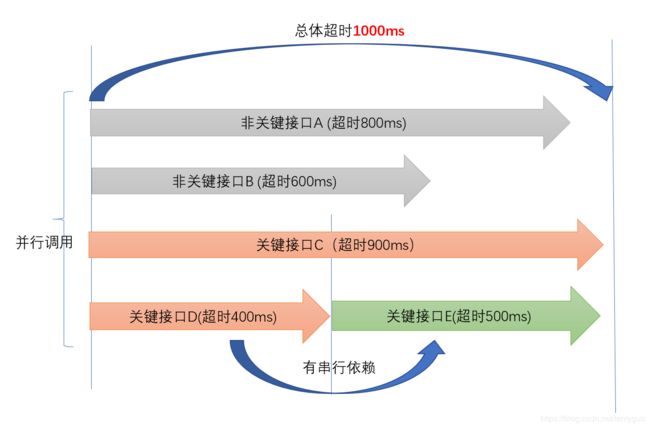
图1-3,并行调用超时设置