带Attention机制的Seq2Seq框架梳理
借着与同事组内分享的机会,根据论文Neural Machine Translation By Jointly Learning to Align and Translate把带Attention机制的Seq2Seq框架Encoder与Decoder部分的流程图画了一下,公式梳理了一遍。
Bi-RNN Encoder
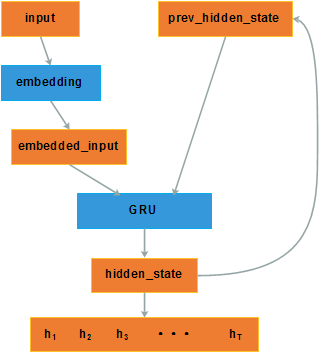
Encoder的流程如上图所示,最终的输出结果是每个时刻的hidden_state h1,h2,h3,...,hT 。
其中的GRU使用的双向的,正向部分的公式如下
反向的同上,最终的 ht 为将正向与反向的结果concat得到的向量。
Attention-Decoder
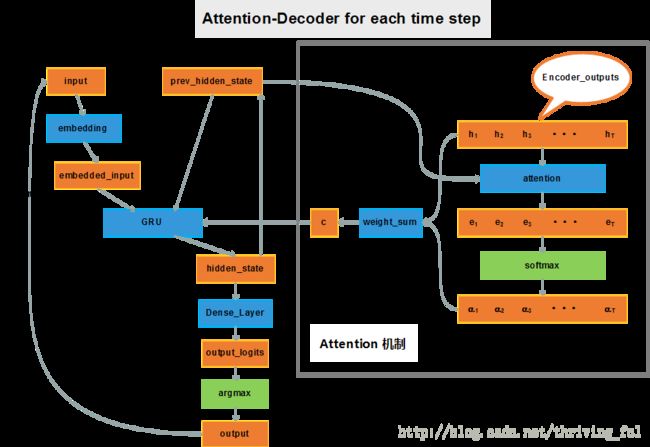
Attention Decoder的流程图如上图所示,与参考论文中不同的一点是,我把hidden_state之后Dense_layer之前的maxout layer去掉了,因为看到google Seq2Seq的实现中也没有maxout layer,与朋友讨论的结果是可能maxout layer会增加更多的计算量。还有就是最后的softmax直接变成argmax了。
上图中拿掉右边方框内的的Attention机制就是一个基本的decoder,基本的decoder与encoder的交互仅在decoder初始的hidden_state上,如将encoder中反向RNN最终的输出状态 h0 作为decoder的初始state s0 。这样对于decoder而言,只能看到源信息的一个总体概要,对于翻译任务,从人的角度来思考, 我们知道这段话的大意, 仅靠大意来进行翻译, 所以我们只能意译。为了翻译的更精准, 我们在知道大意的前提下进行翻译, 还会逐词去匹配, 比如“今天天气真好”翻译完今天之后, 注意力就会在“天气”上,考虑应该将“天气”翻译成什么词。
Attention 机制也就是注意力机制,也称为对齐模型(alignment model), 在翻译阶段, 准备生成每个新的词的时候, 这个机制可以将注意力集中在输入的某个或某几个词上,重点关注这几个词, 可以想象成是将他们与待生成的新词进行对齐,使得翻译更精准。
整个decoding的过程可以拆分为以下几个部分
一、 离散的词ID转换为词向量
与Encoder 中的这个步骤是一样的, 只不过embedding矩阵与Encoder的可能不一样,比如翻译源语言与目标语言需要使用不同的embbedding矩阵,但是如文本摘或是文本风格改写这种就可以使用同一个embedding矩阵。
二、 由encoder的输出结合decoder的prev_hidden_state生成energy
[(h1,h2,h3,...,hT),prev_hidden_state]=>(e1,e2,e3,...,eT)
prev_hidden_state为 si−1 , 由encoder所有时刻的输出 ht 以及decoder的hidden_state si−1 产生能量 e1,e2,...,eT 的过程是Attention的关键步骤。能量 et 的含义也就是对应的源语言输入的词 xt 对即将生成的目标语言的词 yi 的影响力。既然我们需要一个对齐模型, 根据此时每个输入词能量的大小,就可以知道应该使用哪个词与当前的 yi 进行对齐。这样的对齐方式又称为soft alignment, 也就是可以求得梯度, 所以可以与整个模型一起优化。
其中 Uaht 的计算,与decoder的时刻无关,因此可以预先计算好,在每一个时刻将其代入即可。
三、 由energy 到概率
(e1,e2,e3,...,eT)=>(α1,α2,α3,...,αT)
使用attention的目的,是希望得到一个context向量,因此需要将 h1,h2,...,hT 融合在一起,融合若干向量最容易想到的就是加权平均,但是如果直接把能量 e 作为权值,可能会将context向量缩放若干倍,所以需要将 et 转换为概率值 αt ,使得它们的和为1, 同时可以 用来表示输入序列中每个词与当前待生成的词的匹配程度。即
使用softmax求得概率 , 公式如下
四、context 向量合成
[(α1,α2,α3,...,αT),(h1,h2,h3,...,hT)]=>c
得到对输入序列每一时刻的权值 αt 后, 将其与encoder各时刻的输出 ht 加权求和,即得到decoder在当前时刻的context向量 ci ,公式如下
五、prev_hidden_state, 词向量, context向量通过GRU单元生成下一时刻hidden_state
(embedded_input,prev_hidden_state,c)=>hidden_state
decoder本质是一个GRU单元,与GRU不同的在于融合了由attention机制产生的context向量。在decoding的场景,只能用单向的RNN,因为后续时刻的结果在当前时刻是未知的。
将decoder在时刻 i 的hidden_state表示为 si ,prev_hidden_state为 si−1 ,context向量c表示为 ci ,embedded_input表示为 Eyi−1 , 则可由如下公式表示该过程:
其中
六、 使用全连接层将hidden_state映射为vocabulary size的向量
(hidden_state)=>output_logist
生成的hidden_state已经包含了待生成的词的信息了,但是要生成具体的词,我们还需要知道目标语言中每个词的条件概率 p(yi|si) , 如果 si 的维度就是目标语言的词典大小, 那么使用softmax就可以算出每个词的概率, 但是 si 的维度也属于模型的一个参数,通常是不会等于目标语言词典的大小的, 因此再增加一个全连接层, 将 si 映射为维度等于词典大小 L 的向量 vi , 每个维度代表一个词, 使用softmax计算出每个词的概率。