TfLite: model Post-training quantization(生成量化模型和部署)
Post-training quantization的方法
tensorflow lite model 的quantization的方法有两种:
“hybrid” post training quantization and post-training integer quantization
“hybrid” post training quantization approach reduced the model size and latency in many cases, but it has the limitation of requiring floating point computation, which may not be available in all hardware accelerators (i.e. Edge TPUs).
post-training integer quantization enables users to take an already-trained floating-point model and fully quantize it to only use 8-bit signed integers (i.e. `int8`). By leveraging this quantization scheme, we can get reasonable quantized model accuracy across many models without resorting to retraining a model with quantization-aware training. With this new tool, models will continue to be 4x smaller, but will see even greater CPU speed-ups. Fixed point hardware accelerators, such as Edge TPUs, will also be able to run these models.
量化的原理
1] 每轴(或每通道)或每张量的权重用int8进行定点量化的可表示范围为[-127,127],且zero-point就是量化值0
2] 每张量的激活值或输入值用int8进行定点量化的可表示范围为[-128,127],其zero-point在[-128,127]内依据公式求得
量化参数:
S: Rmax - Rmin / Qmax - Qmin = Scale: 每个Q单位表示多大的Real value
Z: Zero = Qmax - Rmax / S: Real zero表示多大的Q value
明确权重的量化和激活值的量化方法不同:
1. weight的量化方法是: Real zero 由 Q value 0表示, 而激活值的 Real zero是由 Z = Qmax - Rmax/S 计算得到
2. 定点的范围也不同weight: [-127, 127], active value:[-128, 127]
对量化是阈值的选取计算,这篇文章采用了更简单的方法。
对于权重,使用实际的最大和最小值来决定量化参数。
对于激活输出,使用跨批(batches)的最大和最小值的滑动平均值来决定量化参数。
生成 float tflite model/ hybrid quatization and integer quantization
下面用简单的例子演示怎样生成 float tflite mode(no quantization), hybrid post training quatization and post-training integer quantization.
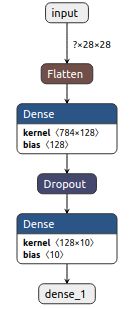
生成简单的mnist模型
使用的tensorfow版本为2.0.0
import tensorflow as tf
import numpy as np
print (tf.__version__)
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
#x_train, x_test = (x_train / 255.0), (x_test / 255.0)
x_train, x_test = (x_train / 255.0).astype(np.float32), (x_test / 255.0).astype(np.float32)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=1)
model.evaluate(x_test, y_test)
保存为 saved_model and h5格式
model.save('saved_model')
model.save('keral_model.h5')
用的竟然是同一个函数save, 可能是从后面的参数 文件夹还是文件区分的
生成tf.lite.TFLiteConverter的方法
在介绍生成quantization之前,先介绍下生成TFLiteConverter的方法。
The Python API for converting TensorFlow models to TensorFlow Lite is tf.lite.TFLiteConverter. TFLiteConverter provides the following classmethods to convert a model based on the original model format:
TFLiteConverter.from_saved_model(): Converts SavedModel directories.TFLiteConverter.from_keras_model(): Convertstf.kerasmodels.TFLiteConverter.from_concrete_functions(): Converts concrete functions.
This document contains example usages of the API, a detailed list of changes in the API between Tensorflow 1 and TensorFlow 2, and instructions on running the different versions of TensorFlow.
和之前1.x的区别是没有了 from_keras_model_file("xxx.h5")
在2.0中没有该函数,怎么从h5文件中得到
keras_model = tf.keras.models.load_model('keras_model.h5') 然后
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
生成float模型
converter = tf.lite.TFLiteConverter.from_keras_model(model)
float_model = converter.convert()
open("float_model.tflite", "wb").write(float_model)
生成hybrid quantization
converter_hybrid = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter_hybrid.optimizations = [tf.lite.Optimize.DEFAULT]
hybrid_quant = converter_hybrid.convert()
open("hybrid_quant.tflite", "wb").write(hybrid_quant)
生成integer quantizaiton
相对float model/ hybrid quantization而言,这个比较麻烦
代表数据generater
需要从训练数据得到 Dataset: 其对应的函数 from_tesnor_slices、batch、take
x_train, x_test = (x_train / 255.0).astype(np.float32), (x_test / 255.0).astype(np.float32)
这里的astype(类型转换是很重要的)
mnist_ds = tf.data.Dataset.from_tensor_slices((x_train)).batch(1)
def representative_data_gen():
for input_value in mnist_ds.take(100):
yield [input_value]
遇到的问题
Traceback (most recent call last):
File "post_training_integer_quantization.py", line 57, in
integer_quant = converter_integer.convert()
File "/usr/local/lib/python2.7/dist-packages/tensorflow_core/lite/python/lite.py", line 450, in convert
constants.FLOAT)
File "/usr/local/lib/python2.7/dist-packages/tensorflow_core/lite/python/lite.py", line 239, in _calibrate_quantize_model
inference_output_type, allow_float)
File "/usr/local/lib/python2.7/dist-packages/tensorflow_core/lite/python/optimize/calibrator.py", line 75, in calibrate_and_quantize
self._calibrator.FeedTensor(calibration_sample)
File "/usr/local/lib/python2.7/dist-packages/tensorflow_core/lite/python/optimize/tensorflow_lite_wrap_calibration_wrapper.py", line 112, in FeedTensor
return _tensorflow_lite_wrap_calibration_wrapper.CalibrationWrapper_FeedTensor(self, input_value)
ValueError: Cannot set tensor: Got tensor of type NOTYPE but expected type FLOAT32 for input 7, name: flatten_input
根据back trace从上到下顺序查看代码对应的代码如下:可知和dataset_gen() 有关,
https://github.com/tensorflow/tensorflow/issues/30861 从这里看到了narray类型转换和narray 转换到tensor
根据建议验证是可以的,其实把narray进行类型转换且不进行narray到tensor的转换也是可以的,问题的关键是要对representative_data_gen的数据进行类型转换,转换为float32类型
train = tf.convert_to_tensor(np.array(train, dtype='float32'))
for calibration_sample in dataset_gen():
448 if self._is_calibration_quantize():
449 result = self._calibrate_quantize_model(result, constants.FLOAT,
450 constants.FLOAT)
233 def _calibrate_quantize_model(self, result, inference_input_type,
234 inference_output_type):
235 allow_float = not self._is_int8_target_required()
236 calibrate_quantize = _calibrator.Calibrator(result)
237 return calibrate_quantize.calibrate_and_quantize(
238 self.representative_dataset.input_gen, inference_input_type,
239 inference_output_type, allow_float)
57 def calibrate_and_quantize(self, dataset_gen, input_type, output_type,
58 allow_float):
59 """Calibrates the model with specified generator and then quantizes it.
60
61 Returns:
62 A quantized model.
63
64 Args:
65 dataset_gen: A generator that generates calibration samples.
66 input_type: A tf.dtype representing the desired real-value input type.
67 output_type: A tf.dtype representing the desired real-value output type.
68 allow_float: A boolean. False if the resulting model cannot perform float
69 computation, useful when targeting an integer-only backend.
70 If False, an error will be thrown if an operation cannot be
71 quantized, otherwise the model will fallback to float ops.
72 """
73 self._calibrator.Prepare()
74 for calibration_sample in dataset_gen():
75 self._calibrator.FeedTensor(calibration_sample)
76 return self._calibrator.QuantizeModel(
77 np.dtype(input_type.as_numpy_dtype()).num,
78 np.dtype(output_type.as_numpy_dtype()).num, allow_float)
111 def FeedTensor(self, input_value):
112 return _tensorflow_lite_wrap_calibration_wrapper.CalibrationWrapper_FeedTensor(self, input_value)
生成integer quantization
mnist_ds = tf.data.Dataset.from_tensor_slices((x_train)).batch(1)
def representative_data_gen():
for input_value in mnist_ds.take(100):
yield [input_value]
converter_integer = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter_integer.optimizations = [tf.lite.Optimize.DEFAULT]
#converter.representative_dataset = representative_data_gen
converter_integer.representative_dataset = tf.lite.RepresentativeDataset(representative_data_gen)
converter_integer.target_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
integer_quant = converter_integer.convert()
open("integer_quan.tflite", "wb").write(integer_quant)
quantization前后的文件大小
-rw-rw-r-- 1 ws ws 408320 1月 2 19:43 float_model.tflite
-rw-rw-r-- 1 ws ws 103664 1月 2 19:43 hybrid_quant.tflite
-rw-rw-r-- 1 ws ws 104144 1月 2 19:43 integer_quan.tflite
-rw-rw-r-- 1 ws ws 1248544 1月 2 19:43 keras_model.h5
-rw-rw-r-- 1 ws ws 104144 1月 2 17:52 post_training_integer_quan.tflite
drwxr-xr-x 4 ws ws 4096 1月 2 10:47 saved_model
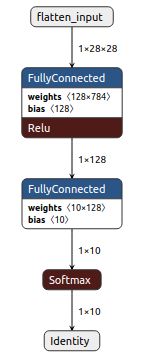
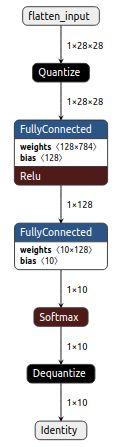
quantization前后的graph图
float_model、hybrid、integer、h5
float_mode\hybrid的图结构一致但其中的参数的数据类型不同(floa/int8), integer quantization在前增加了quantize,在后增加了dequantize.

评估quantization using Python Tensorflow Lite Interpreter
获得测试数据
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = (x_train / 255.0).astype(np.float32), (x_test / 255.0).astype(np.float32)
使用上面的x_test, y_test; 因为推断的结果要和标注比较,构建的Dataset如下:
mnist_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(1)Load the model into the interpreters
Float model::
interpreter = tf.lite.Interpreter(model_path='float_model.tflite')
interpreter.allocate_tensors()
integer quantization model:
interpreter_quant = tf.lite.Interpreter(model_path='integer_quan.tflite')
interpreter_quant.allocate_tensors()
Test the models on one image
float model
for img, label in mnist_ds: #img and label 不想象的是临时变量,后面可以用
break
interpreter.set_tensor(interpreter.get_input_details()[0]["index"], img)
interpreter.invoke()
predictions = interpreter.get_tensor(interpreter.get_output_details()[0]["index"])
integer quantization model
for img, label in mnist_ds:
break
interpreter_quant.set_tensor(
interpreter_quant.get_input_details()[0]["index"], img)
interpreter_quant.invoke()
predictions = interpreter_quant.get_tensor(
interpreter_quant.get_output_details()[0]["index"])
推断后的结果是predictions,数据类型是array, 而label是个tensor,
array是one-hot编码,而lebal是sparse编码,array([7]表示数字 “7”
In [52]: predictions
Out[52]:
array([[0. , 0. , 0. , 0.00390625, 0. ,
0. , 0. , 0.99609375, 0. , 0. ]],
dtype=float32)
In [53]: label
Out[53]:
Evaluate the models
def eval_model(interpreter, mnist_ds):
total_seen = 0
num_correct = 0
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
for img, label in mnist_ds:
total_seen += 1
interpreter.set_tensor(input_index, img)
interpreter.invoke()
predictions = interpreter.get_tensor(output_index)
if np.argmax(predictions) == label.numpy()[0]: #这里是关键
num_correct += 1
if total_seen % 500 == 0:
print("Accuracy after %i images: %f" %
(total_seen, float(num_correct) / float(total_seen)))
return float(num_correct) / float(total_seen)使用同一个测试集用不同interpreter进行验证
# Create smaller dataset for demonstration purposes
mnist_ds_demo = mnist_ds.take(2000)
print(eval_model(interpreter, mnist_ds_demo))
print(eval_model(interpreter_quant, mnist_ds_demo))
In [57]: print(eval_model(interpreter, mnist_ds_demo))
Accuracy after 500 images: 0.974000
Accuracy after 1000 images: 0.961000
Accuracy after 1500 images: 0.954000
Accuracy after 2000 images: 0.951500
Accuracy after 2500 images: 0.946000
Accuracy after 3000 images: 0.947000
Accuracy after 3500 images: 0.949714
Accuracy after 4000 images: 0.945750
Accuracy after 4500 images: 0.945111
Accuracy after 5000 images: 0.945400
Accuracy after 5500 images: 0.949273
Accuracy after 6000 images: 0.950000
Accuracy after 6500 images: 0.951385
Accuracy after 7000 images: 0.952000
Accuracy after 7500 images: 0.954000
Accuracy after 8000 images: 0.955750
Accuracy after 8500 images: 0.957412
Accuracy after 9000 images: 0.959444
Accuracy after 9500 images: 0.960421
Accuracy after 10000 images: 0.959000
0.959
In [58]: print(eval_model(interpreter_quant, mnist_ds_demo))
Accuracy after 500 images: 0.978000
Accuracy after 1000 images: 0.964000
Accuracy after 1500 images: 0.956667
Accuracy after 2000 images: 0.954000
Accuracy after 2500 images: 0.948000
Accuracy after 3000 images: 0.948333
Accuracy after 3500 images: 0.950857
Accuracy after 4000 images: 0.946500
Accuracy after 4500 images: 0.945333
Accuracy after 5000 images: 0.945600
Accuracy after 5500 images: 0.949273
Accuracy after 6000 images: 0.950167
Accuracy after 6500 images: 0.951538
Accuracy after 7000 images: 0.952143
Accuracy after 7500 images: 0.954133
Accuracy after 8000 images: 0.955875
Accuracy after 8500 images: 0.957412
Accuracy after 9000 images: 0.959444
Accuracy after 9500 images: 0.960316
Accuracy after 10000 images: 0.958800
0.9588
从本例来看qantization后略有降低 0.959 -> 0.9588
部署中遇到的问题
生成的模型文件中op的版本由文件由tensorflow/lite/tools/versioning/op_version.cc决定的,因此注册算子的版本也要和这里一致,否则找不到对应的op
// Op versions discussed in this file are enumerated here:
// tensorflow/lite/tools/versioning/op_version.cc
class MicroMutableOpResolver : public OpResolver {
public:
const TfLiteRegistration* FindOp(tflite::BuiltinOperator op,
int version) const override;
const TfLiteRegistration* FindOp(const char* op, int version) const override;
void AddBuiltin(tflite::BuiltinOperator op, TfLiteRegistration* registration,
int min_version = 1, int max_version = 1);
void AddCustom(const char* name, TfLiteRegistration* registration,
int min_version = 1, int max_version = 1);
private:
TfLiteRegistration registrations_[TFLITE_REGISTRATIONS_MAX];
int registrations_len_ = 0;
TF_LITE_REMOVE_VIRTUAL_DELETE
};
all_ops_resolver.cc里的版本信息也不全对,如AVERAGE_POOL_2D
// Register each supported op with:
// AddBuiltin(
AllOpsResolver::AllOpsResolver() {
AddBuiltin(BuiltinOperator_FULLY_CONNECTED, Register_FULLY_CONNECTED(), 1, 4);
AddBuiltin(BuiltinOperator_MAX_POOL_2D, Register_MAX_POOL_2D());
AddBuiltin(BuiltinOperator_SOFTMAX, Register_SOFTMAX());
AddBuiltin(BuiltinOperator_LOGISTIC, Register_LOGISTIC());
AddBuiltin(BuiltinOperator_SVDF, Register_SVDF());
AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D(), 1, 3);
AddBuiltin(BuiltinOperator_CONCATENATION, Register_CONCATENATION(), 1, 3);
AddBuiltin(BuiltinOperator_DEPTHWISE_CONV_2D, Register_DEPTHWISE_CONV_2D(), 1, 3);
AddBuiltin(BuiltinOperator_AVERAGE_POOL_2D, Register_AVERAGE_POOL_2D(), 1, 2);
}
TFLite中量化相关的数据结构
从注释上看TfLiteQuantizationParams将会被TfLiteAffineQuantization取代,但当前TfLiteQuantizationParams还使用,因为有些算子不支持channel quantize, 而实际上TfLiteAffineQuantization是TfLiteQuantizationParams的数组形式
// Legacy. Will be deprecated in favor of TfLiteAffineQuantization.
// If per-layer quantization is specified this field will still be populated in
// addition to TfLiteAffineQuantization.
// Parameters for asymmetric quantization. Quantized values can be converted
// back to float using:
// real_value = scale * (quantized_value - zero_point)
typedef struct {
float scale;
int32_t zero_point;
} TfLiteQuantizationParams;
// Parameters for asymmetric quantization across a dimension (i.e per output
// channel quantization).
// quantized_dimension specifies which dimension the scales and zero_points
// correspond to.
// For a particular value in quantized_dimension, quantized values can be
// converted back to float using:
// real_value = scale * (quantized_value - zero_point)
typedef struct {
TfLiteFloatArray* scale;
TfLiteIntArray* zero_point;
int32_t quantized_dimension;
} TfLiteAffineQuantization;

从下面可以看出input/output/active value的zero_point不是0,而权重、bias的 zero_point是0但是多通道的,而activate总是单通道。
<<----------------------------------------------------------------
quantization: -8.117244720458984 ≤ 0.07573700696229935 * (q - -21) ≤ 11.19569206237793
--- tensor name: depthwise_conv2d_input_int8 ---
quantization: scale: 0.075737, zero_point: -21
channels: 1
quantization: scale: 0.075737, zero_point: -21
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/depthwise_conv2d/depthwise/ReadVariableOp ---
quantization: scale: 0.003461, zero_point: 0
channels: 8
quantization: scale: 0.003461, zero_point: 0
quantization: scale: 0.003643, zero_point: 0
quantization: scale: 0.004665, zero_point: 0
quantization: scale: 0.003722, zero_point: 0
quantization: scale: 0.002931, zero_point: 0
quantization: scale: 0.003288, zero_point: 0
quantization: scale: 0.003704, zero_point: 0
quantization: scale: 0.003462, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/depthwise_conv2d/depthwise_bias ---
quantization: scale: 0.000262, zero_point: 0
channels: 8
quantization: scale: 0.000262, zero_point: 0
quantization: scale: 0.000276, zero_point: 0
quantization: scale: 0.000353, zero_point: 0
quantization: scale: 0.000282, zero_point: 0
quantization: scale: 0.000222, zero_point: 0
quantization: scale: 0.000249, zero_point: 0
quantization: scale: 0.000281, zero_point: 0
quantization: scale: 0.000262, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/depthwise_conv2d/Relu ---
quantization: scale: 0.033231, zero_point: -128
channels: 1
quantization: scale: 0.033231, zero_point: -128
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/average_pooling2d/AvgPool ---
quantization: scale: 0.033231, zero_point: -128
channels: 1
quantization: scale: 0.033231, zero_point: -128
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/conv2d/Conv2D/ReadVariableOp ---
quantization: scale: 0.005083, zero_point: 0
channels: 16
quantization: scale: 0.005083, zero_point: 0
quantization: scale: 0.006344, zero_point: 0
quantization: scale: 0.005207, zero_point: 0
quantization: scale: 0.003689, zero_point: 0
quantization: scale: 0.004211, zero_point: 0
quantization: scale: 0.005478, zero_point: 0
quantization: scale: 0.010819, zero_point: 0
quantization: scale: 0.004262, zero_point: 0
quantization: scale: 0.010639, zero_point: 0
quantization: scale: 0.004018, zero_point: 0
quantization: scale: 0.009138, zero_point: 0
quantization: scale: 0.003741, zero_point: 0
quantization: scale: 0.005365, zero_point: 0
quantization: scale: 0.003906, zero_point: 0
quantization: scale: 0.004800, zero_point: 0
quantization: scale: 0.004889, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/conv2d/Conv2D_bias ---
quantization: scale: 0.000169, zero_point: 0
channels: 16
quantization: scale: 0.000169, zero_point: 0
quantization: scale: 0.000211, zero_point: 0
quantization: scale: 0.000173, zero_point: 0
quantization: scale: 0.000123, zero_point: 0
quantization: scale: 0.000140, zero_point: 0
quantization: scale: 0.000182, zero_point: 0
quantization: scale: 0.000360, zero_point: 0
quantization: scale: 0.000142, zero_point: 0
quantization: scale: 0.000354, zero_point: 0
quantization: scale: 0.000134, zero_point: 0
quantization: scale: 0.000304, zero_point: 0
quantization: scale: 0.000124, zero_point: 0
quantization: scale: 0.000178, zero_point: 0
quantization: scale: 0.000130, zero_point: 0
quantization: scale: 0.000160, zero_point: 0
quantization: scale: 0.000162, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/conv2d/Relu ---
quantization: scale: 0.012436, zero_point: -128
channels: 1
quantization: scale: 0.012436, zero_point: -128
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/average_pooling2d_1/AvgPool ---
quantization: scale: 0.012436, zero_point: -128
channels: 1
quantization: scale: 0.012436, zero_point: -128
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense/MatMul/ReadVariableOp/transpose ---
quantization: scale: 0.009346, zero_point: 0
channels: 1
quantization: scale: 0.009346, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense/MatMul_bias ---
quantization: scale: 0.000116, zero_point: 0
channels: 1
quantization: scale: 0.000116, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense/Relu ---
quantization: scale: 0.047351, zero_point: -128
channels: 1
quantization: scale: 0.047351, zero_point: -128
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense_1/MatMul/ReadVariableOp/transpose ---
quantization: scale: 0.009934, zero_point: 0
channels: 1
quantization: scale: 0.009934, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense_1/MatMul_bias ---
quantization: scale: 0.000470, zero_point: 0
channels: 1
quantization: scale: 0.000470, zero_point: 0
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: StatefulPartitionedCall/sequential/dense_1/BiasAdd ---
quantization: scale: 0.079378, zero_point: 28
channels: 1
quantization: scale: 0.079378, zero_point: 28
----------------------------------------------------------------->>
<<----------------------------------------------------------------
--- tensor name: Identity_int8 ---
quantization: scale: 0.003906, zero_point: -128
channels: 1
quantization: scale: 0.003906, zero_point: -128
----------------------------------------------------------------->>