论文笔记:EAST: an Efficient and Accuracy Scene Text detection pipeline
EAST: an Efficient and Accuracy Scene Text detection pipeline
直接在整张图像上回归目标和它的几何轮廓,模型是全卷积神经网络,每个像素位置都输出密集的文字预测。排除了生成候选目标,生成文字区域,字母分割(candidate proposal, text region formation, word partition)等中间过程。后续过程仅包含thresholding和 NMS。
large words: need features from late-stage of a neural network,
small word regions : need low-level information in early stages.
Merging a large number of channels on large feature maps would significantly increase the computation
overhead for later stages. So we adopt the idea from U-shape to merge feature maps gradually,
网络结构:
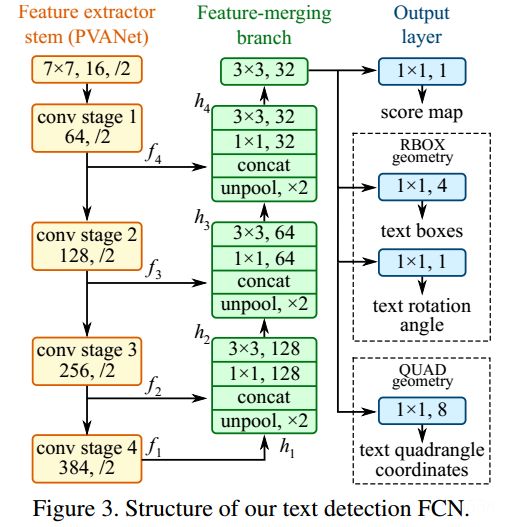
整体网络结构分为3个部分
(1) 特征提取层:
使用的基础网络结构是PVANet,分别从stage1,stage2,stage3,stage4抽出特征,一种FPN(feature pyramid network)的思想。
(2) 特征融合层:
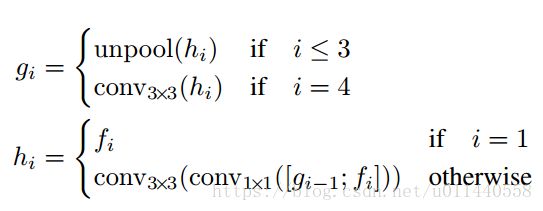
4个feature maps,记为fi,尺寸分别是输入图像尺寸的1/32,1/16,1/8,1/4
gi is the merge base
hi is the merged feature map
i=1:
g1=conv33(h1)=conv33(f1)
h1=f1
i=2:
g2=unpool(h2)
h2=conv33(conv11([g1;f2]))
i=3:
g3=unpool(h3)
h3=conv33(conv11([g2;f3]))
i=4:
g4=conv33(h4)
h4=conv33(conv1*1([g3;f4]))
将上一层feature map上采样尺寸放大一倍,再与当前层feature map 融合;
使用conv11减少通道数和计算量;
使用conv33融合信息;
再最后的融合操作中,使用一个conv3*3产生最终融合后的feature map,并传入输出层。
(3)输出层:
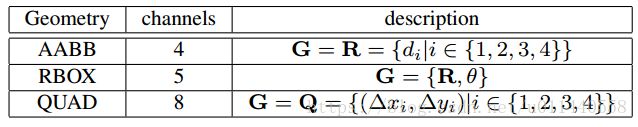
对于旋转矩形预测, R 的4个通道表示每个像素到对应的预测框top, right, bottom, left边界的距离。
标签生成过程:

(a) 中黄色的为人工标注的框,绿色为对黄色框进行0.3倍边长的缩放后的框,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
(b) 为根据(a)中绿色框生成的label信息
© 中先生成一个(b)中白色区域的最小外接矩,然后算每一个(b)中白色的点到粉色最小外接矩的距离,即生成(d),然后生成粉色的矩形和水平方向的夹角,即生成角度信息(e)
损失函数:
![]()
Loss for Score Map
交叉熵H(p,q): 通过概率分布q来表达概率分布p的困难程度
为了解决imbalanced distribution of target objects问题,使用class balanced cross-entropy

Loss for Geometries
文本检测中,文本的尺寸变化极大,直接使用L1/ L2损失做回归 会导致loss偏向于尺寸大和长的文本区域。 回归损失需要具有尺度不变性(scale-invariant)。
因此,RBOX regression采用IoU loss ,QUAD regression采用scale-normalized smoothed-L1。
RBOX :IoU loss具有尺度不变性
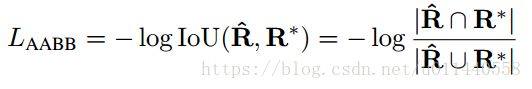
重叠部分的矩形
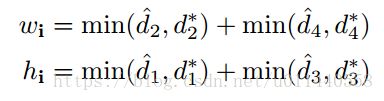
d1, d2, d3, d4 分别表示一个像素距离所对应的旋转矩形的四条边的距离
the loss of rotation angle

geometry loss等于 AABB loss 与angle loss的和:

计算LAABB的时候忽略了旋转角度,虽然是初略估计,实际上在训练过程中是可行的。
损失函数由分类的损失Ls和回归的损失Lg组成。
其中分类Ls采用class balanced cross-entrop loss
回归由AABB位置回归和角度回归组成
Locality-Aware NMS:

就是先对输出的框中IOU大于某个阈值的框进行合并,然后再进行标准的NMS操作。
Reference:
https://arxiv.org/abs/1704.03155
https://blog.csdn.net/qq_14845119/article/details/78986449