序列化推荐的图模型——Selecting Sequences of Items via Submodular Maximization(更新中)
本文介绍一种基于图模型的序列化推荐方法:OMEGA。文章来自AAAI-17,题目为《Selecting Sequences of Items via Submodular Maximization》,作者是来自苏黎世联邦理工学院的Sebastian Tschiatschek,Adish Singla 以及Andreas Krause。
背景
子集选择问题
首先,介绍一下子集选择问题,该问题的目标是优化一个集合函数 f(X) ,使得 |X|≤k 。例如,机器学习中的特征选择、模型选择,推荐中的目标用户选择,深度学习中的网络结构选择,都属于子集选择问题。一般来说,子集选择问题是NP难的,多项式时间内只能得到近似解。
对于子集选择问题,如果目标函数满足 单调Submodular 性质,贪心算法可以达到 1−e−1 的近似率,即,贪心方法得到的解与最优解的比值不小于 1−e−1 。
集合有一个性质,即“无序”,在上述问题中,我们没有考虑到元素顺序时会给目标函数带来的影响,但是实际中,有些问题,不同的选择次序,会影响到目标函数值的大小。
序列化选择问题
在推荐问题中,我们需要考虑用户历史观看记录,此时,它看的顺序会影响我们推荐的结果。
如下图,假设我们要进行视频推荐,用户A先观看了生活大爆炸第一集,然后看了生活大爆炸第二集,这时,我们可能会给A推荐生活大爆炸第三集。另外,A还看了IT狂人,不过,它是先看的第二集,再看的第一集,此时,如果给A推荐第三集,似乎此时推荐成功率就不如推荐生活大爆炸第三集的成功率高。

这个例子表明,在推荐的时候,历史信息的顺序也是很重要的。
此时,我们需要给这类问题下个定义:
模型
那么,如何给这类问题建模呢?
序列化基本概念:

那么,我们的优化目标变为:
注意到,考虑到集合的顺序关系,所以该模型的搜索空间是无序模型的 k! 倍。
本文研究一类特定的函数 f(σ) ,它假设选择的元素及其之间的关系构成了一个图结构 G=(V,E) ,如下图,节点代表元素,元素之间的联系用边来表示。边的含义:节点之间的相互影响。B1到B2有一条边,意思是,如果B1排在B2之前,则B1会对B2产生影响。B2到B1没有边,即如果B2排在B1之前,B2不会对B1产生影响。
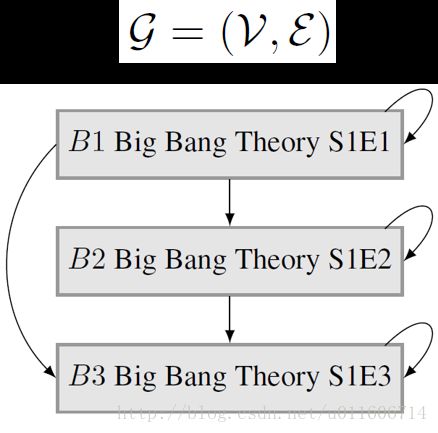
edges(σ) 函数是有序集合到边的映射,对于一个有序集合 σ=(σ1,...,σk) ,对于每个 σj ,我们取出如下的边: {(σi,σj)∈E|i≤j} , edges(σ) 将返回所有这样的边的集合,它是直观含义是,每个元素只会被之前的元素影响,而不会被之后出现的元素影响。 h 是定义在边上的实值函数(本文假设它是单调非负Submodular的)。 我们研究具有 f(σ)=h(edges(σ)) 这样形式的目标函数。
形式化定义如下:

传统贪心策略
传统贪心方法如下图所示,以 l=1 为例,它从空集开始,即 σ=() ,每次选一个使得 f(σ) 增量最大的节点,添加到 σ 的后面。直到节点个数为 k 。

在子集选择问题上,贪心策略有较好的理论保证,但是在序列化选择问题上,贪心策略无法得到常数近似率保证。文中给出了如下定理:

OMEGA方法
本文提出了一种基于边的贪心方法OMEGA,它的基本思想是,每次从图中选择一条边(选了边,其相连的节点也就确定了),使得 f(σ) 的增量最大。如果图是有向无环图,则在具体计算 f(σ) 值的时候,会对 σ 中所有节点进行拓扑排序。


对于OMEGA方法,作者给出了一下理论保证:

实验部分
本文在人造数据集和真实的推荐数据集上做了实验。
人造数据集
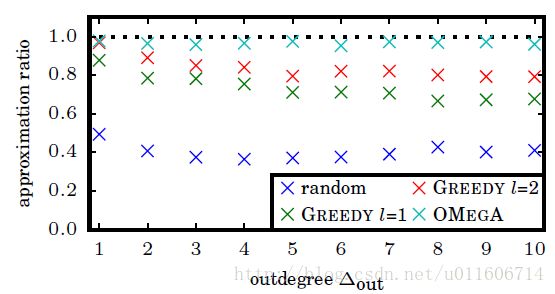
在人造图 G=(V,E) 上, f(σ)=h(edges(σ)) ,文章如下两个 h 函数进行了测试。
h(E)=|E|
实验结果如下,纵坐标是算法得到的解和最优解的比值。
h(E)=∑j∈nodes(E)[1−Π(i,j)∈E(1−wi,j)] ,这里 wi,j 是边的权重。
实验结果如下,纵坐标是算法得到的解和最优解的比值。

真实数据集
另外,文章在Movielens 1M数据集上做了实验。数据集包含了6040个用户对3706部电影的共1000208条评分。评分从1~5分不等,并且记录了评分的时间。平均每个用户有165.6条评分,每部电影收到了269.9条评分。
文章的实验不是预测评分,而是根据用户的历史记录,预测用户将会看哪些电影。
这里,将每个用户的观看记录看作一个序列 σi , D={σ1,...,σn} 。其中, σi={σi1,σi2,...} , σij 代表第i个用户对第他观看过的第j部电影的评分。将用户分为 Dtrain 和 Dtest , 其中 |Dtest|=500 。
那么,我们该如何构造图 G=(V,E) 呢?文章中按照如下方式构造:每个结点表示一部电影,结点 i 到结点 j 之间的边的含义为,用户先看电影 i 再看电影 j 的概率,结点 i 到自己的边的含义为,第 i 部电影出现的频率。这些数值是在训练集上统计出来的。
该实验,选取的目标函数是: h(E)=∑j∈nodes(E)[1−Π(i,j)∈E(1−pi,j)] ,它表示 E 出现的后验概率。
由于实验做的事一个预测问题,故有一个评估函数,定义为:
Prec@k:=1k|Dtest|∑σ∈Dtest|nodes(σft)∩Pk(σpr)| ,其中, Pk(σpr) 是根据 σpr 预测的 k 个元素, σft 是用户真实观看的电影序列。
对比方法:FREQ和BG

实验结果:
