《电子商务网站用户行为分析及服务推荐》第一节:数据探索
关键词:
《Python数据分析与挖掘实战》,第12章电子商务网站用户行为分析及服务推荐
运行环境:
iMac电脑 macOS Mojave系统 版本10.14.1,python3.7 ,mariaDB数据库,PyCharm集成开发工具
需要注意的地方:
运行前要先启动数据库
mac上启动mariaDB mysql.server start
mac上关闭mariaDB mysql.server stop
传送门:源码下载 (ps:满意的话 轻轻动您的金指star一下)
数据探索分析
1.1 网页类型分析
下面的每个文件都需要引入头文件,我这里只写一次
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# fullURLId 网址类型 然后分类统计个数
counts = [i['fullURLId'].value_counts() for i in sql]
# 合并统计结果,把相同的统计项合并(即按index分组并求和)
counts = pd.concat(counts).groupby(level=0).sum()
# 重置index索引 生成一个新的DataFrame返回 注意与它counts.to_frame()的区别 具体区别请查看官方文档
counts = counts.reset_index()
# 重置列名
counts.columns = ['index', 'num']
# 在增加一列 提取前三个数字作为类别id
counts['type'] = counts['index'].str.extract('(\d{3})')
# 按类别分组求和合并统计
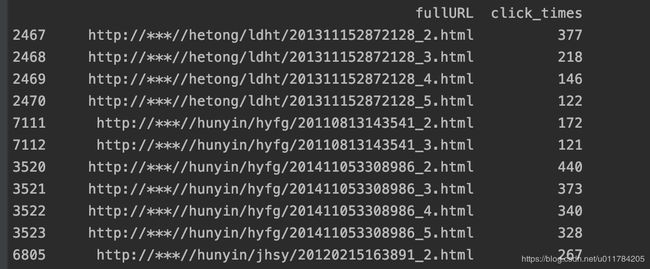
counts_ = counts.groupby(by='type').sum()
counts_ = counts_.sort_values(by=['num'], ascending=False)
counts_ = counts_.reset_index()
counts_['percent'] = (counts_['num'] / counts_['num'].sum()) * 100
运行结果如下:

1.2 各个类别类型具体分析
代码参考网站
def count107(j):
"""
107类型具体分析
:param j:
:return:
"""
# 找出类别包含107的网址 [fullURL数组(1138 * 1)][bool值数组]
j = j[['fullURL']][j['fullURLId'].str.contains('107')].copy()
j['type'] = None # 添加空列
j['type'][j['fullURL'].str.contains('info/.+?/')] = u'知识首页'
j['type'][j['fullURL'].str.contains('info/.+?/.+?')] = u'知识列表页'
j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')] = u'知识内容页'
return j['type'].value_counts()
def count101(p):
"""
101类型具体分析
:param j:
:return:
"""
p = p[['fullURLId']][p['fullURLId'].str.startswith('101')].copy()
p['type'] = None # 添加空列
p['type'][p['fullURLId'].str.endswith('001')] = '101001'
p['type'][p['fullURLId'].str.endswith('002')] = '101002'
p['type'][p['fullURLId'].str.endswith('003')] = '101003'
p['type'][~p['fullURLId'].str.contains('(001|002|003)')] = u'其他'
return p['type'].value_counts()
def count_ask(p):
"""
网址中带有?的具体分析
:param j:
:return:
"""
p = p[['fullURLId']][p['fullURL'].str.contains('?', regex=False)].copy()
return p['fullURLId'].value_counts()
def count_199(p):
"""
199类型具体分析
:param j:
:return:
"""
p = p[['fullURLId', 'pageTitle']][p['fullURL'].str.contains('?', regex=False)].copy()
p = p[['pageTitle']][p['fullURLId'].str.contains('1999001')].copy()
# p['type'] = None # 添加空列
# p['type'][p['pageTitle'].str.contains('法律快车-律师助手', na=False, regex=True)] = u'快车-法律助手'
# p['type'][p['pageTitle'].str.contains('免费发布法律咨询', na=False, regex=True)] = u'免费发布法律咨询'
# p['type'][p['pageTitle'].str.contains('咨询发布成功', na=False, regex=True)] = u'咨询发布成功'
# p['type'][p['pageTitle'].str.contains('法律快搜', na=False, regex=True)] = u'法律快搜'
# p['type'][~p['pageTitle'].str.contains('(法律快车-律师助手|免费发布法律咨询|咨询发布成功|法律快搜)', na=False, regex=True)] = u'其他类型'
# 下面这个方法比上面那个更好一点
p['type'] = 1 # 添加空列
p.loc[p['pageTitle'].str.contains('法律快车-律师助手', na=False, regex=True), 'type'] = u'快车-法律助手'
p.loc[p['pageTitle'].str.contains('免费发布法律咨询', na=False, regex=True), 'type'] = u'免费发布法律咨询'
p.loc[p['pageTitle'].str.contains('咨询发布成功', na=False, regex=True), 'type'] = u'咨询发布成功'
p.loc[p['pageTitle'].str.contains('法律快搜', na=False, regex=True), 'type'] = u'法律快搜'
p.loc[p['type'] == 1, 'type'] = u'其他类型'
return p['type'].value_counts()
def wandering(p):
"""
瞎逛用户具体分析
:param j:
:return:
"""
# 取出不以.html的数据
p = p[['fullURLId']][~p['fullURL'].str.endswith('.html')].copy()
return p['fullURLId'].value_counts()
接下来开始调用上面的方法
# 需要注意的一点是:因为sql是一个生成器类型,所以在使用过一次以后,就不能继续使用了。必须要重新执行一次读取。
1.2.1 107类型具体分析
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# fullURLId 网址类型 然后分类统计个数
count_107 = [count107(i) for i in sql]
count_107 = pd.concat(count_107).groupby(level=0).sum()
count_107 = count_107.reset_index()
count_107.columns = ['type', 'num']
count_107['percent'] = count_107['num'] / count_107['num'].sum() * 100
print(count_107)
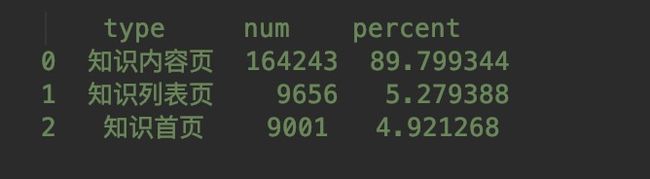
1.2.2 101类型具体分析
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# 咨询类别内部统计 101开头的
count_101 = [count101(m) for m in sql]
count_101 = pd.concat(count_101).groupby(level=0).sum()
count_101 = count_101.reset_index()
count_101.columns = ['type', 'num']
count_101 = count_101.sort_values(by=['num'], ascending=False)
count_101['percent'] = count_101['num'] / count_101['num'].sum() * 100
print(count_101)
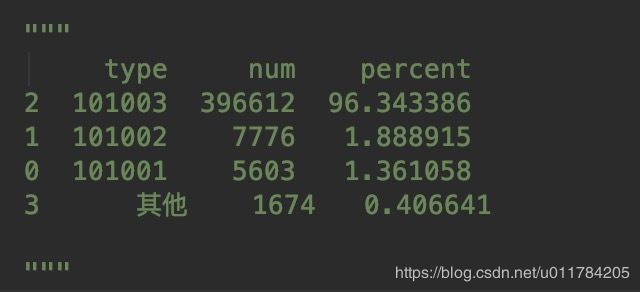
1.2.3 其他具体类型统计
我只写了2个,eg:带问号的类型统计统计;带有问号的网址中,其他(1999001)类型统计;闲逛用户统计;
我就不在一一罗列,只是更换掉这个方法即可,具体参考我的源码
# count_ask = [count_ask(m) for m in sql]
1.3 用户点击次数统计
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize=10000)
# 分块统计各个IP的点击次数
result = [i['realIP'].value_counts() for i in sql]
result = pd.concat(result).groupby(level=0).sum()
result = pd.DataFrame(result)
# 增加一列1 方便用户点击次数的统计
result[1] = 1
# 各个IP的点击次数
click_count = result.groupby(by=['realIP']).sum()
# 将索引也变成其中的一列
click_count = click_count.reset_index()
click_count.columns = [u'点击次数', u'用户数']
click_count[u'用户百分比'] = click_count[u'用户数'] / click_count[u'用户数'].sum() * 100
# 记录百分比等于各个层上用户数乘以点击次数与所有的点击次数之比
click_count[u'记录百分比'] = click_count[u'用户数'] * click_count[u'点击次数'] / result['realIP'].sum() * 100
# 取出前8个数据
# 后面加copy消除警告
# A value is trying to be set on a copy of a slice from a DataFrame.
# Try using .loc[row_indexer,col_indexer] = value instead
click_count_8 = click_count.iloc[:8, :].copy()
click_count_8.loc[7, u'点击次数'] = u'7次以上'
click_count_8.loc[7, u'用户数'] = click_count.iloc[8:, 1].sum()
click_count_8.loc[7, u'用户百分比'] = click_count.iloc[8:, 2].sum()
click_count_8.loc[7, u'记录百分比'] = click_count.iloc[8:, 3].sum()
print(click_count_8)
# 接下来统计7次以上 用户的分布情况
# 本来想着这样操作来统计 有部分的数据不对 弃用
# bins = [7, 100, 1000, 50000]
# temp_count = click_count.iloc[8:, :]
# click_count_cut = pd.cut(temp_count[u'点击次数'], bins=bins, right=True,)
# print(click_count_cut)
"""
301 (100, 1000]
302 (100, 1000]
303 (100, 1000]
304 (1000, 50000]
305 (1000, 50000]
306 (1000, 50000]
307 (1000, 50000]
"""
# click_count_8 = click_count.copy()
result_data = pd.DataFrame()
result_data[u'点击次数'] = pd.Series(['8~100', '101~1000', '1000以上'])
# 这样筛选出来的数据不对
# value1 = click_count.iloc[:, 1][8:101].sum()
# # value1 = click_count[u'用户数'][8:101].sum()
# value2 = click_count.iloc[:, 1][101:1001].sum()
# value3 = click_count.iloc[:, 1][1001:].sum()
value1 = click_count.loc[click_count[u'点击次数'].isin(range(8, 101)), u'用户数'].sum()
value2 = click_count.loc[click_count[u'点击次数'].isin(range(101, 1001)), u'用户数'].sum()
value3 = click_count.loc[click_count[u'点击次数'] > 1000, u'用户数'].sum()
result_data[u'用户数'] = [value1, value2, value3]
print(result_data)

1.3 浏览一次用户的行为分析和点击一次用户浏览网页统计
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# 分块统计各个IP的点击次数
result = [i['realIP'].value_counts() for i in sql]
click_count = pd.concat(result).groupby(level=0).sum()
click_count = click_count.reset_index()
click_count.columns = ['realIP', 'times']
# 筛选出来点击一次的数据
click_one_data = click_count[click_count['times'] == 1]
# 这里只能再次读取数据 因为sql是一个生成器类型,所以在使用过一次以后,就不能继续使用了。必须要重新执行一次读取。
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# 取出这三列数据
data = [i[['fullURLId', 'fullURL', 'realIP']] for i in sql]
data = pd.concat(data)
# 和并数据 我以click_one_data为基准 按照realIP合并过来,目的方便查看点击一次的网页和realIP
merge_data = pd.merge(click_one_data, data, on='realIP', how='left')
# 点击一次的数据统计 写入数据库 以方便读取 校准无误 写入后就可以注释掉此句代码
# merge_data.to_sql('click_one_count', engine, if_exists='append')
# print(merge_data)
"""
realIP times fullURLId fullURL
0 95502 1 101003 http://www.lawtime.cn/ask/question_7882607.html
1 103182 1 101003 http://www.lawtime.cn/ask/question_7174864.html
2 136206 1 101003 http://www.lawtime.cn/ask/question_8246285.html
3 140151 1 107001 http://www.lawtime.cn/info/gongsi/slbgfgs/2011...
4 155761 1 101003 http://www.lawtime.cn/ask/question_5951952.html
5 159758 1 101003 http://www.lawtime.cn/ask/question_1909224.html
6 213105 1 101003 http://www.lawtime.cn/ask/question_1586269.html
"""
# 网页类型ID统计
fullURLId_count = merge_data['fullURLId'].value_counts()
fullURLId_count = fullURLId_count.reset_index()
fullURLId_count.columns = ['fullURLId', 'count']
fullURLId_count['percent'] = fullURLId_count['count'] / fullURLId_count['count'].sum() * 100
print('*****' * 10)
print(fullURLId_count)
"""
fullURLId count percent
0 101003 102560 77.626988
1 107001 19443 14.716279
2 1999001 9381 7.100417
3 301001 515 0.389800
4 102001 70 0.052983
5 103003 45 0.034060
"""
# 用户点击一次 浏览的网页统计
fullURL_count = merge_data['fullURL'].value_counts()
fullURL_count = fullURL_count.reset_index()
fullURL_count.columns = ['fullURL', 'count']
fullURL_count['percent'] = fullURL_count['count'] / fullURL_count['count'].sum() * 100
print('*****' * 10)
print(fullURL_count)
"""
fullURL count percent
0 http://www.lawtime.cn/info/shuifa/slb/20121119... 1013 0.766733
1 http://www.lawtime.cn/info/hunyin/lhlawlhxy/20... 501 0.379204
2 http://www.lawtime.cn/ask/question_925675.html 423 0.320166
3 http://www.lawtime.cn/info/shuifa/slb/20121119... 367 0.277780
4 http://www.lawtime.cn/ask/exp/13655.html 301 0.227825
5 http://www.lawtime.cn/ask/exp/8495.html 241 0.182411
6 http://www.lawtime.cn/ask/exp/13445.html 199 0.150622
7 http://www.lawtime.cn/guangzhou 177 0.133970
"""
1.4 网页排名
def handle_data(p):
p = p[['fullURL', 'fullURLId', 'realIP']][p['fullURL'].str.contains('\.html')].copy()
return p
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
result = [handle_data(i) for i in sql]
click_count = pd.concat(result)
# 网页统计
web_count = click_count['fullURL'].value_counts()
web_count = web_count.reset_index()
web_count.columns = ['fullURL', 'click_times', ]
print(web_count)
# 类型点击
click_count['fullURLId'] = click_count['fullURLId'].str.extract('(\d{3})')
type_count = pd.merge(web_count, click_count, on='fullURL', how='left')
# temp_type_count['flag'] = 1
# 统计各个类型的点击次数
type_count_result = type_count.copy()
# 统计fullURLId对应的总点击数
type_count_result = type_count_result.drop_duplicates(subset='fullURL', keep='first')
# 删除无效数据 删除fullURL,realIP这两列数据
del type_count_result['fullURL']
del type_count_result['realIP']
# 计算各个fullURLId下总的点击数
type_count_result = type_count_result.groupby(by=['fullURLId']).sum()
type_count_result = type_count_result.reset_index()
# 接下来统计各个fullURLId总用户数
temp_type_count = type_count.copy()
temp_type_count = temp_type_count.groupby(by=['fullURLId', 'realIP']).sum()
temp_type_count = temp_type_count.reset_index()
# 把用户的realIP置位1 方便用户数统计计数
temp_type_count['realIP'] = 1
# 删除无效数据
del temp_type_count['click_times']
temp_type_count = temp_type_count.groupby(by='fullURLId').sum()
temp_type_count = temp_type_count.reset_index()
# temp_type_count与type_count_result开始合并
type_count_result = pd.merge(type_count_result, temp_type_count, on='fullURLId', how='left')
# print(type_count_result)
type_count_result.columns = [u'网页类型', u'总点击数', u'用户数']
type_count_result[u'平均点击率'] = type_count_result[u'总点击数'] / type_count_result[u'用户数']
type_count_result = type_count_result.sort_values(by=[u'平均点击率'], ascending=False)
print(type_count_result)
# 翻页网页统计
# _数字 后面代表页码,我是简单匹配1到100页的数据
web_page_count = web_count[web_count['fullURL'].str.contains('_\d{1,2}\.html')]
# 把'_数字.html'替换成'.html'
web_page_count['tempURL'] = web_page_count['fullURL'].str.replace('_\d{0,2}\.html', '.html')
# 这样做的目的为了一会过滤出个数大于1的网址 个数大于1才有翻页的可能
temp_web_page_count = web_page_count['tempURL'].value_counts()
temp_web_page_count = temp_web_page_count.reset_index()
temp_web_page_count.columns = ['tempURL', u'出现次数']
temp_web_page_count = temp_web_page_count[temp_web_page_count[u'出现次数'] > 1]
temp_web_page_count = temp_web_page_count.sort_values(by=u'出现次数', ascending=False)
# 合并数据 以temp_web_page_count为基准
temp_web_page_count = pd.merge(temp_web_page_count, web_page_count, on='tempURL', how='left')
# 以'http://***/'替换'http://www.域名.cn/info' 方便数据查看 我的正则比较简单粗暴
temp_web_page_count['tempURL'] = temp_web_page_count['tempURL'].str.replace('(.*)/info', 'http://***/',
regex=True)
temp_web_page_count['fullURL'] = temp_web_page_count['fullURL'].str.replace('(.*)/info', 'http://***/',
regex=True)
# 过滤掉tempURL出现一次的数据 因为翻页的话tempURL出现的次数要大于1次
temp_web_page_count = temp_web_page_count[temp_web_page_count[u'出现次数'] > 1]
# 删除这一列 因为它的使命已经完成
del temp_web_page_count['出现次数']
# 打印出来数据较多 因此在过滤到点击次数大于100的数据
temp_web_page_count = temp_web_page_count[temp_web_page_count[u'click_times'] > 100]
temp_web_page_count = temp_web_page_count.sort_values(by=['fullURL'], ascending=True)
del temp_web_page_count['tempURL']
# 因为打印显示不完全再次替换
temp_web_page_count['fullURL'] = temp_web_page_count['fullURL'].str.replace('hunyinfagui/', 'hyfg/',
regex=True)
temp_web_page_count['fullURL'] = temp_web_page_count['fullURL'].str.replace('jihuashengyu/', 'jhsy/',
regex=True)
temp_web_page_count['fullURL'] = temp_web_page_count['fullURL'].str.replace('jiaotong/', 'jt/',
regex=True)
temp_web_page_count['fullURL'] = temp_web_page_count['fullURL'].str.replace('laodong/', 'ld/',
regex=True)
print(temp_web_page_count)
web_count图片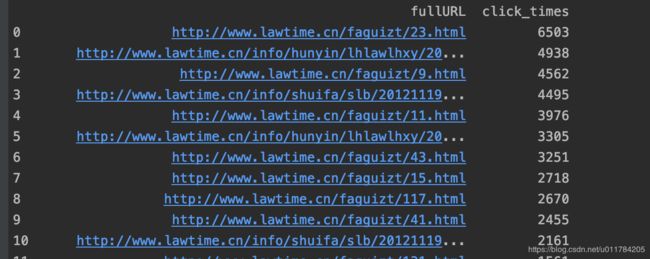
type_count_result结果图片 类型点击数统计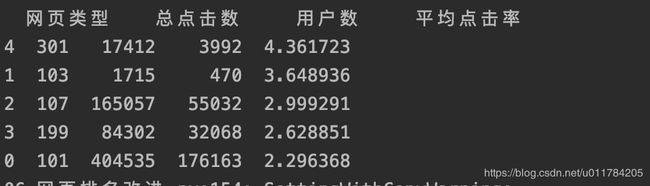
翻页网页统计表