爬虫学习
目的
虽然现在流行用python写爬虫方便很多,但还是想巩固一下自己的知识,所以用c++在linux环境中开发并测试。
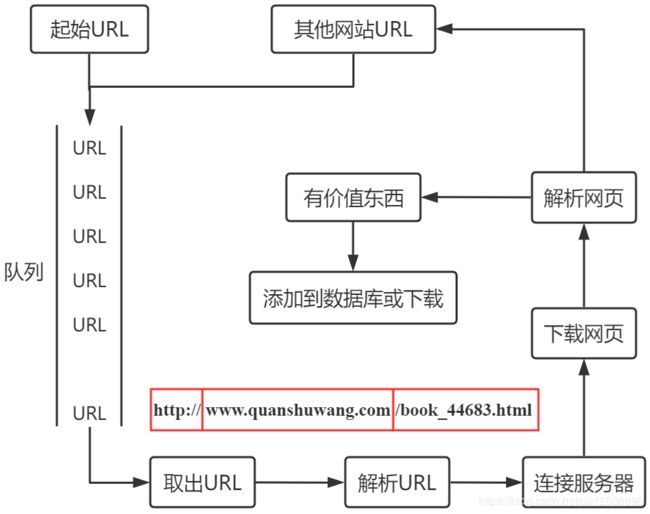
逻辑图
代码
https://github.com/ucasxzzzh/spider.git
编写逻辑
【解析URL函数】
解析过程中用 str.find()函数 判断输入的 url 中是否存在 http:// 或 https://,再从其后找第一个 / 的位置,从而得到主机名和资源路径,用substr切分字符串。
【网络相关】
首先新建socket,然后利用 gethostbyname函数 解析得到服务器ip,设定sockaddr_in后connect到服务器。
【获取网页源代码】
用字符串拼接模拟发送HTTP GET请求到服务器,send发送recv接收,接收的时候可以一个字符一个字符接收,再将所有字符累加起来展示。
【解析网页源代码中的图片】
采用正则表达式 http://[^\\s'\"<>(){}]+ 获取带jpg的URL,具体利用循环regex_search查找符合条件的字符串,在去除带http://www.w3.org/的URL后将每一个URL加入之前写好的队列中,进行迭代式的查找。
参考:https://blog.csdn.net/qq_34802416/article/details/79307102
【拿到图片URL后下载】
相当于再发送一次GET请求,需要新建对象,fopen打开文件后用fwrite写入文件即可。
编程过程中注意事项
1、模拟HTTP请求时换行要用\r\n
正常来讲linux中 \n 就可以表示换行了,windows才是 \r\n 表示换行(其实是回车+换行),mac是 \r 表示换行,这里不知道为什么一定要用 \r\n 才可以。
2、大部分url中带http的网站貌似会自动重定向到https的url,导致报 301 Removed Permanently,后续处理方法还需研究!
3、写正则表达式的时候,发现regex貌似需要c++11版本,故在makefile中加 -std=c++11。
4、可以新建一个vector存放本次URL查询时所收集到的URL,可用如下代码去重后再下载。
sort(vecImage.begin(),vecImage.end());
auto it = unique(vecImage.begin(), vecImage.end());
vecImage.erase(it, vecImage.end());5、打开文件时的路径名是拼接而成,获取当前执行文件路径代码如下,文件名则是URL中最后一个 / 后边的部分。
#include
char buf[256] = {0};
getcwd(buf, 256);
string currentPath = buf; 6、下载的内容中包括http头信息,图片可能无法显示,可以写如下循环当找到两个换行的时候再开始写文件。
char ch = 0;
while(recv(m_socket,&ch,sizeof(ch),0))
{
if(ch == '\r')
{
recv(m_socket,&ch,sizeof(ch),0);
if(ch == '\n')
{
recv(m_socket,&ch,sizeof(ch),0);
if(ch == '\r')
{
recv(m_socket,&ch,sizeof(ch),0);
if(ch == '\n')
{
break;
}
}
}
}
}同样遇到1的问题,如果是删除连续两个\n图片依旧无法显示。
7、遇到segmentation fault,ulimit - c unlimited 开启coredump功能,参考:https://www.linuxidc.com/Linux/2015-09/123099.htm 查看报错位置。具体方法为:
- 编译命令中加入 -g
- 运行可执行文件
- 生成core.*文件
- gdb -q [可执行文件名] core.*
- 找到报错位置
8、报错的原因为fp为空导致后面的文件写入出了问题,竟然是把代码写成了 if(fp = NULL) 。
提醒:以后代码一定要写成 if(NULL == fp),这样如果不小心写成了 if(NULL = fp) 会在程序编译时报错!
9、每次git push时都要输入一遍用户名和密码?
需要使用SSH的方式添加的远程仓库,而不是https的方式,参考:https://www.toodyao.com/?p=1156
10、通过函数新建文件夹
#include
#include
int isCreate = mkdir((currentPath+"/img/").c_str(),S_IRUSR | S_IWUSR | S_IXUSR | S_IRWXG | S_IRWXO);
if(-1 == isCreate)
{
cout<<"new folder error!!!"< 待补充~
参考B站 @C语言编程爱好者 up主视频,自学用,侵删!