基于U-Net的眼底图像血管分割实例
【英文说明】https://github.com/orobix/retina-unet#retina-blood-vessel-segmentation-with-a-convolution-neural-network-u-net
【更新】针对Python3版本对此部分代码做了优化,已上传到我的GitHub:点击打开链接
【注意事项】
1.运行run_training.py或run_testing.py如果出错,可以尝试将src/retinaNN_training.py或src/retinaNN_predict.py拷贝到工程根目录下运行。(代码目前已更新至根目录下)
2.针对模型Unet的可视化代码在training的111、112行中,如果不需要模型可视化可以注释掉。如果可视化过程出错,可以参考CSDN博客进行修改。
3.如果出现提示test文件夹下的不存在的问题,请先在工程目录下新建test文件夹。
4.大体流程:数据处理→训练→预测生成
1 介绍
为了能够更好的对眼部血管等进行检测、分类等操作,我们首先要做的就是对眼底图像中的血管进行分割,保证最大限度的分割出眼部的血管。从而方便后续对血管部分的操作。
DRIVE数据集下载:百度网盘 (密码:4l7v)
这部分代码选用的数据集是DRIVE数据集,包括训练集和测试集两部分。眼底图像数据如图1所示。

图1 DRIVE数据集的训练集眼底图像
DRIVE数据集的优点是:不仅有已经手工分好的的血管图像(在manual文件夹下,如图2所示),而且还包含有眼部轮廓的图像(在mask文件夹下,如图3所示)。
图2 DRIVE数据集的训练集手工标注血管图像

图3 DRIVE数据集的训练集眼部轮廓图像
DRIVE数据集的缺点是:显而易见,从上面的图片中可以看出,训练集只有20幅图片,可见数据量实在是少之又少。。。
所以,为了得到更好的分割效果,我们需要对这20幅图像进行预处理从而增大其数据量
2 依赖的库
【2020.03.24注】因版本不一可能会导致某些不可预期的错误,现将包的版本固定(我的机器可以运行)
- numpy == 1.16.4
- Keras == 2.2.5
- Tensorflow == 1.13.1
- Pillow == 5.0.0
- opencv-python == 4.1.1.26
- h5py == 2.7.1
- configparser == 3.5.0
- scikit-learn == 0.19.1
3 数据读取与保存
数据集中训练集和测试集各只有20幅眼底图像(tif格式)。首先要做的第一步就是对生成数据文件,方便后续的处理。所以这里我们需要对数据集中的眼底图像、人工标注的血管图像、眼部轮廓生成数据文件。这里使用的是hdf5文件。有关hdf5文件的介绍,请参考CSDN博客(HDF5快速上手全攻略)。
数据处理重要代码部分(prepare_datasets_DRIVE.py):
def get_datasets(imgs_dir,groundTruth_dir,borderMasks_dir,train_test="null"):
imgs = np.empty((Nimgs,height,width,channels))
groundTruth = np.empty((Nimgs,height,width))
border_masks = np.empty((Nimgs,height,width))
for path, subdirs, files in os.walk(imgs_dir): #list all files, directories in the path
for i in range(len(files)):
#original
print("original image: " +files[i])
img = Image.open(imgs_dir+files[i])
imgs[i] = np.asarray(img)
#corresponding ground truth
groundTruth_name = files[i][0:2] + "_manual1.gif"
print("ground truth name: " + groundTruth_name)
g_truth = Image.open(groundTruth_dir + groundTruth_name)
groundTruth[i] = np.asarray(g_truth)
#corresponding border masks
border_masks_name = ""
if train_test=="train":
border_masks_name = files[i][0:2] + "_training_mask.gif"
elif train_test=="test":
border_masks_name = files[i][0:2] + "_test_mask.gif"
else:
print("specify if train or test!!")
exit()
print("border masks name: " + border_masks_name)
b_mask = Image.open(borderMasks_dir + border_masks_name)
border_masks[i] = np.asarray(b_mask)
print("imgs max: " +str(np.max(imgs)))
print("imgs min: " +str(np.min(imgs)))
assert(np.max(groundTruth)==255 and np.max(border_masks)==255)
assert(np.min(groundTruth)==0 and np.min(border_masks)==0)
print("ground truth and border masks are correctly withih pixel value range 0-255 (black-white)")
#reshaping for my standard tensors
imgs = np.transpose(imgs,(0,3,1,2))
assert(imgs.shape == (Nimgs,channels,height,width))
groundTruth = np.reshape(groundTruth,(Nimgs,1,height,width))
border_masks = np.reshape(border_masks,(Nimgs,1,height,width))
assert(groundTruth.shape == (Nimgs,1,height,width))
assert(border_masks.shape == (Nimgs,1,height,width))
return imgs, groundTruth, border_masks
4 训练
4.1 数据预处理
训练过程,我们首先对眼底图像数据进行数据预处理。调用lib/pre_processing.py下的my_PreProc()完成数据预处理相关工作。
预处理包括:灰度变换、标准化、对比度受限的自适应直方图均衡化(CLAHE)以及伽马变换。有关对比度受限的自适应直方图均衡化可以参考CSDN博客,有关伽马变换可以参考CSDN博客。
下面是对比度受限的自适应直方图均衡化代码:
# CLAHE (Contrast Limited Adaptive Histogram Equalization)
#adaptive histogram equalization is used. In this, image is divided into small blocks called "tiles" (tileSize is 8x8 by default in OpenCV). Then each of these blocks are histogram equalized as usual. So in a small area, histogram would confine to a small region (unless there is noise). If noise is there, it will be amplified. To avoid this, contrast limiting is applied. If any histogram bin is above the specified contrast limit (by default 40 in OpenCV), those pixels are clipped and distributed uniformly to other bins before applying histogram equalization. After equalization, to remove artifacts in tile borders, bilinear interpolation is applied
def clahe_equalized(imgs):
assert (len(imgs.shape)==4) #4D arrays
assert (imgs.shape[1]==1) #check the channel is 1
#create a CLAHE object (Arguments are optional).
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
imgs_equalized = np.empty(imgs.shape)
for i in range(imgs.shape[0]):
imgs_equalized[i,0] = clahe.apply(np.array(imgs[i,0], dtype = np.uint8))
return imgs_equalized下面是伽马变换的代码:
def adjust_gamma(imgs, gamma=1.0):
assert (len(imgs.shape)==4) #4D arrays
assert (imgs.shape[1]==1) #check the channel is 1
# build a lookup table mapping the pixel values [0, 255] to
# their adjusted gamma values
invGamma = 1.0 / gamma
table = np.array([((i / 255.0) ** invGamma) * 255 for i in np.arange(0, 256)]).astype("uint8")
# apply gamma correction using the lookup table
new_imgs = np.empty(imgs.shape)
for i in range(imgs.shape[0]):
new_imgs[i,0] = cv2.LUT(np.array(imgs[i,0], dtype = np.uint8), table)
return new_imgs4.2 数据扩增
深度学习需要大量的数据来拟合模型参数,针对只有20张眼底图像的DRIVE数据集,我们采用随机切片的方式来对数据进行扩增。调用lib/extract_patches.py下的extract_random()来对数据进行切片。
每个尺寸为48*48的贴片是通过在整个图像内随机选择其中心获得的。此外,选择部分可能完全在视野(FOV)之外的斑块,通过这种方式,神经网络可以学习如何区分FOV边界与血管。
通过以下代码完成随机切片,扩充数据:
for i in range(full_imgs.shape[0]): #loop over the full images
k=0
while k 通过在20个DRIVE训练图像中的每一个中随机提取9500个patches来获得一组190000个patches。尽管贴片重叠,即不同的贴片可以包含原始图像的相同部分,但是不执行进一步的数据增强。然后对数据进行分布,前90%的数据集用于训练(171000个patches),而最后10%用于验证(19000个patches)。
4.3 搭建网络模型
神经网络架构源自U-Net架构(参见论文)。损失函数是交叉熵,随机梯度下降用于优化。每个卷积层之后的激活函数是整流器线性单元(ReLU),并且在两个连续卷积层之间使用0.2的dropout。
这一部分用keras便可轻松完成,U-Net的结构代码如下:
#Define the neural network
def get_unet(n_ch,patch_height,patch_width):
inputs = Input(shape=(n_ch,patch_height,patch_width))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
#
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
#
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3)
up1 = concatenate([conv2,up1],axis=1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4)
#
up2 = UpSampling2D(size=(2, 2))(conv4)
up2 = concatenate([conv1,up2], axis=1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5)
#
conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5)
conv6 = core.Reshape((2,patch_height*patch_width))(conv6)
conv6 = core.Permute((2,1))(conv6)
conv7 = core.Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7)
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.3, nesterov=False)
model.compile(optimizer='sgd', loss='categorical_crossentropy',metrics=['accuracy'])
return model4.4 执行训练
通过model.fit执行训练,对在训练过程中随时保存模型就可以了。
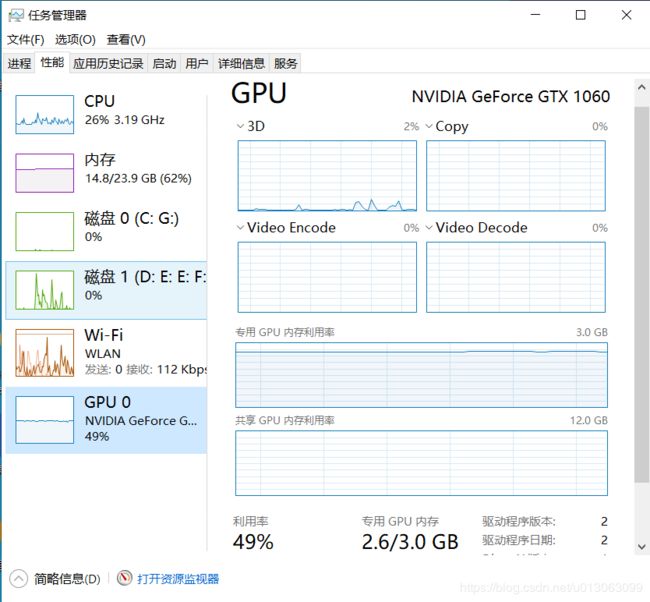
训练过程的我电脑信息如下,占用内存还是挺高的。Windows10,内存一共24GB(一块8GB,一块16GB)。GPU使用的是GTX 1060(阉割版,显存3GB)。
5 预测生成
5.1 准备数据
与训练过程一样,准备预测的数据。
5.2 读取保存好的模型权重
在训练过程中,会判断当前模型权重是否最好,最好则会进行保存。预测时,读取保存的权重。
model.load_weights(path_experiment+name_experiment + '_'+best_last+'_weights.h5')5.3 预测
通过model.predict执行预测。
5.4 预测结果对比
通过代码,将预测图像与原图像拼接起来,进行可视化对比。
5.5 计算评价结果
此部分预测的结果评价标准由准确率、召回率、AUC/ROC曲线进行评价。相关内容学习请见CSDN博客。
最后在test文件夹下,会有预测之后的结果图,以及AUC/ROC曲线、准确率/召回率曲线等。