python 爬虫学习过程剖析

目录
一 python简介
二 Python爬虫过程图和学习路线
三 爬虫过程代码
四 解析库
1.JSON解析
2.网页解析
五 33个爬虫项目实战
六 总结
参考资料
一 python简介
Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言。
创始人Guido van Rossum是BBC出品英剧Monty Python’s Flying Circus(中文:蒙提·派森的飞行马戏团)的狂热粉丝,因而将
自己创造的这门编程语言命名为Python。
二 Python爬虫过程图和学习路线
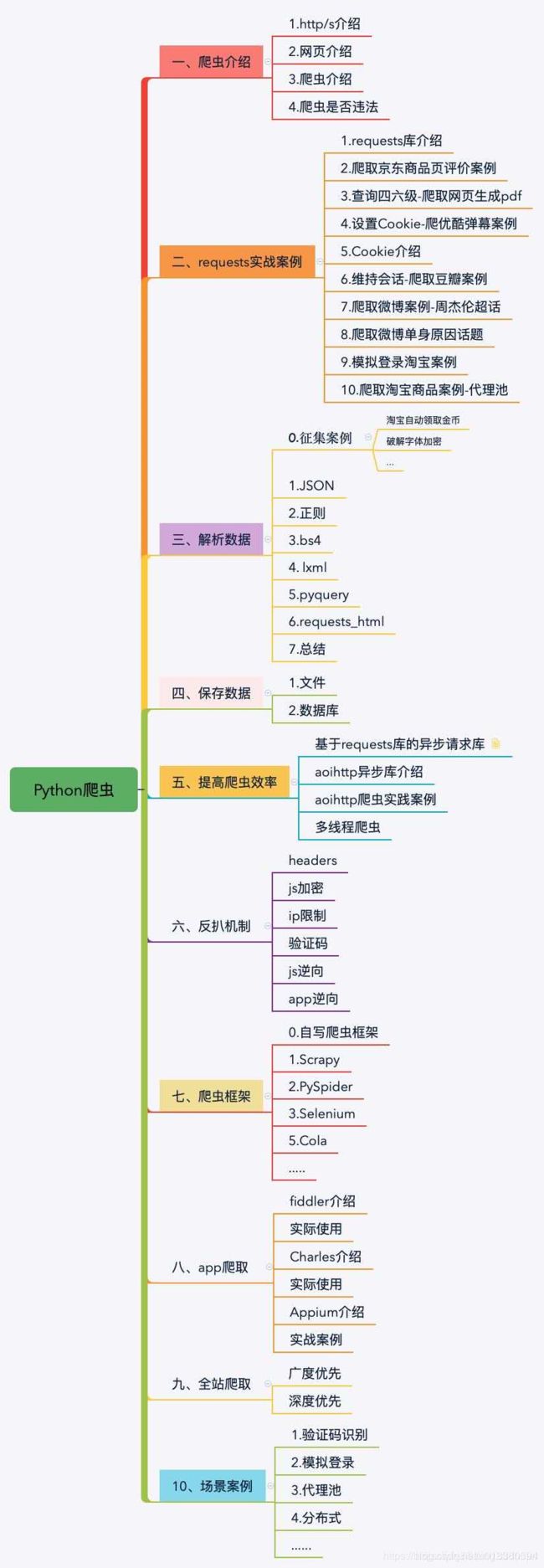
三 爬虫过程代码
init.py
# -*- coding: UTF-8 -*-
# import need manager module
import MongoUtil
import FileUtil
import conf_dev
import conf_test
import scratch_airport_name
import scratch_flight_number
import scratch_movie_name
import scratch_train_number
import scratch_train_station
import MainUtil
conf_dev.py
# -*- coding: UTF-8 -*-
# the configuration file of develop environment
# path configure
data_root_path = 'E:/test/smart/data'
# mongodb configure
user = "cby"
pwd = "123456"
server = "localhost"
port = "27000"
db_name = "testdb"
将更新的内容插入mongodb中
MongoUtil.py
# -*- coding: UTF-8 -*-
import platform
from pymongo import MongoClient
from datetime import datetime, timedelta, timezone
import conf_dev
import conf_test
# configure Multi-confronment
platform_os = platform.system()
config = conf_dev
if (platform_os == 'Linux'):
config = conf_test
# mongodb
uri = 'mongodb://' + config.user + ':' + config.pwd + '@' + config.server + ':' + config.port + '/' + config.db_name
# 将数据写入mongodb
# @author chenmc
# @param uri connect to mongodb
# @path save mongodb field
# @data save mongodb field
# @operation save mongodb field default value 'append'
# @date 2017/12/07 16:30
# 先在mongodb中插入一条自增数据 db.sequence.insert({ "_id" : "version","seq" : 1})
def insert(path, data, operation='append'):
client = MongoClient(uri)
resources = client.smartdb.resources
sequence = client.smartdb.sequence
seq = sequence.find_one({"_id": "version"})["seq"] #获取自增id
sequence.update_one({"_id": "version"}, {"$inc": {"seq": 1}}) #自增id+1
post_data = {"_class": "com.gionee.smart.domain.entity.Resources", "version": seq, "path": path,
"content": data, "status": "enable", "operation": operation,
"createtime": datetime.now(timezone(timedelta(hours=8)))}
resources.insert(post_data) #插入数据
下面真正的执行方法来了,这五个py分别表示爬取五种信息:机场名、航班号、电影名、列车号、列车站。他们的结构都差不多,如下:
第一部分:定义查找的url;
第二部分:获取并与旧数据比较,返回新数据;
第三部分:main方法,执行写入新数据到文件和mongodb中;
scratch_airport_name.py:爬取全国机场
# -*- coding: UTF-8 -*-
import requests
import bs4
import json
import MainUtil
resources_file_path = '/resources/airplane/airportNameList.ini'
scratch_url_old = 'https://data.variflight.com/profiles/profilesapi/search'
scratch_url = 'https://data.variflight.com/analytics/codeapi/initialList'
get_city_url = 'https://data.variflight.com/profiles/Airports/%s'
#传入查找网页的url和旧数据,然后本方法会比对原数据中是否有新的条目,如果有则不加入,如果没有则重新加入,最后返回新数据
def scratch_airport_name(scratch_url, old_airports):
new_airports = []
data = requests.get(scratch_url).text
all_airport_json = json.loads(data)['data']
for airport_by_word in all_airport_json.values():
for airport in airport_by_word:
if airport['fn'] not in old_airports:
get_city_uri = get_city_url % airport['id']
data2 = requests.get(get_city_uri).text
soup = bs4.BeautifulSoup(data2, "html.parser")
city = soup.find('span', text="城市").next_sibling.text
new_airports.append(city + ',' + airport['fn'])
return new_airports
#main方法,执行这个py,默认调用main方法,相当于java的main
if __name__ == '__main__':
MainUtil.main(resources_file_path, scratch_url, scratch_airport_name)
scratch_flight_number.py:爬取全国航班号
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import bs4
import MainUtil
resources_file_path = '/resources/airplane/flightNameList.ini'
scratch_url = 'http://www.variflight.com/sitemap.html?AE71649A58c77='
def scratch_flight_number(scratch_url, old_flights):
new_flights = []
data = requests.get(scratch_url).text
soup = bs4.BeautifulSoup(data, "html.parser")
a_flights = soup.find('div', class_='list').find_all('a', recursive=False)
for flight in a_flights:
if flight.text not in old_flights and flight.text != '国内航段列表':
new_flights.append(flight.text)
return new_flights
if __name__ == '__main__':
MainUtil.main(resources_file_path, scratch_url, scratch_flight_number)
scratch_movie_name.py:爬取最近上映的电影
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
import requests
import bs4
import json
import MainUtil
# 相对路径,也是需要将此路径存入数据库
resources_file_path = '/resources/movie/cinemaNameList.ini'
scratch_url = 'http://theater.mtime.com/China_Beijing/'
# scratch data with define url
def scratch_latest_movies(scratch_url, old_movies):
data = requests.get(scratch_url).text
soup = bs4.BeautifulSoup(data, "html.parser")
new_movies = []
new_movies_json = json.loads(
soup.find('script', text=re.compile("var hotplaySvList")).text.split("=")[1].replace(";", ""))
coming_movies_data = soup.find_all('li', class_='i_wantmovie')
# 上映的电影
for movie in new_movies_json:
move_name = movie['Title']
if move_name not in old_movies:
new_movies.append(movie['Title'])
# 即将上映的电影
for coming_movie in coming_movies_data:
coming_movie_name = coming_movie.h3.a.text
if coming_movie_name not in old_movies and coming_movie_name not in new_movies:
new_movies.append(coming_movie_name)
return new_movies
if __name__ == '__main__':
MainUtil.main(resources_file_path, scratch_url, scratch_latest_movies)
scratch_train_number.py:爬取全国列车号
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import bs4
import json
import MainUtil
resources_file_path = '/resources/train/trainNameList.ini'
scratch_url = 'http://www.59178.com/checi/'
def scratch_train_number(scratch_url, old_trains):
new_trains = []
resp = requests.get(scratch_url)
data = resp.text.encode(resp.encoding).decode('gb2312')
soup = bs4.BeautifulSoup(data, "html.parser")
a_trains = soup.find('table').find_all('a')
for train in a_trains:
if train.text not in old_trains and train.text:
new_trains.append(train.text)
return new_trains
if __name__ == '__main__':
MainUtil.main(resources_file_path, scratch_url, scratch_train_number)
scratch_train_station.py:爬取全国列车站
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import bs4
import random
import MainUtil
resources_file_path = '/resources/train/trainStationNameList.ini'
scratch_url = 'http://www.smskb.com/train/'
def scratch_train_station(scratch_url, old_stations):
new_stations = []
provinces_eng = (
"Anhui", "Beijing", "Chongqing", "Fujian", "Gansu", "Guangdong", "Guangxi", "Guizhou", "Hainan", "Hebei",
"Heilongjiang", "Henan", "Hubei", "Hunan", "Jiangsu", "Jiangxi", "Jilin", "Liaoning", "Ningxia", "Qinghai",
"Shandong", "Shanghai", "Shanxi", "Shanxisheng", "Sichuan", "Tianjin", "Neimenggu", "Xianggang", "Xinjiang",
"Xizang",
"Yunnan", "Zhejiang")
provinces_chi = (
"安徽", "北京", "重庆", "福建", "甘肃", "广东", "广西", "贵州", "海南", "河北",
"黑龙江", "河南", "湖北", "湖南", "江苏", "江西", "吉林", "辽宁", "宁夏", "青海",
"山东", "上海", "陕西", "山西", "四川", "天津", "内蒙古", "香港", "新疆", "西藏",
"云南", "浙江")
for i in range(0, provinces_eng.__len__(), 1):
cur_url = scratch_url + provinces_eng[i] + ".htm"
resp = requests.get(cur_url)
data = resp.text.encode(resp.encoding).decode('gbk')
soup = bs4.BeautifulSoup(data, "html.parser")
a_stations = soup.find('left').find('table').find_all('a')
for station in a_stations:
if station.text not in old_stations:
new_stations.append(provinces_chi[i] + ',' + station.text)
return new_stations
if __name__ == '__main__':
MainUtil.main(resources_file_path, scratch_url, scratch_train_station)
下面这个main方法控制着执行流程,其他的执行方法调用这个main方法
MainUtil.py
# -*- coding: UTF-8 -*-
import sys
from datetime import datetime
import MongoUtil
import FileUtil
# @param resources_file_path 资源文件的path
# @param base_url 爬取的连接
# @param scratch_func 爬取的方法
def main(resources_file_path, base_url, scratch_func):
old_data = FileUtil.read(resources_file_path) #读取原资源
new_data = scratch_func(base_url, old_data) #爬取新资源
if new_data: #如果新数据不为空
date_new_data = "//" + datetime.now().strftime('%Y-%m-%d') + "\n" + "\n".join(new_data) + "\n" #在新数据前面加上当前日期
FileUtil.append(resources_file_path, date_new_data) #将新数据追加到文件中
MongoUtil.insert(resources_file_path, date_new_data) #将新数据插入到mongodb数据库中
else: #如果新数据为空,则打印日志
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), '----', getattr(scratch_func, '__name__'), ": nothing to update ")
下面文件是一个util文件,主要是读取原文件的内容,还有将新内容写入原文件。
FileUtil.py
# -*- coding: UTF-8 -*-
import conf_dev
import conf_test
import platform
# configure Multi-confronment
# 判断当前系统,并引入相对的配置文件
platform_os = platform.system()
config = conf_dev
if (platform_os == 'Linux'):
config = conf_test
# path
data_root_path = config.data_root_path
# load old data
def read(resources_file_path, encode='utf-8'):
file_path = data_root_path + resources_file_path
outputs = []
for line in open(file_path, encoding=encode):
if not line.startswith("//"):
outputs.append(line.strip('\n').split(',')[-1])
return outputs
# append new data to file from scratch
def append(resources_file_path, data, encode='utf-8'):
file_path = data_root_path + resources_file_path
with open(file_path, 'a', encoding=encode) as f:
f.write(data)
f.close
到此结束。
从过以上例子主要让大家能理解爬虫整个实战过程。
四 解析库
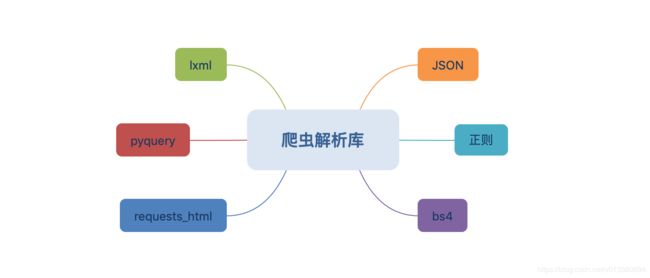
1.JSON解析
一般情况下,网站会有纯数据的接口和返回网页的接口之分。因为前后端分离的流行,所以越来越多的纯数据接口了。纯数据接口解析起来也会比网页要简单很多,所以猪哥建议我们在爬取数据的时候优先考虑是否有纯数据接口。
前些年Web数据传输格式更多的可能是XML (eXtensible Markup Language),但是现在JSON(Javascript Object Notation) 已成为Web数据传输的首选,因为JSON相比XML容易阅读、解析更快、占用空间更少、对前端友好。

而且纯JSON数据相对于网页来说解析更加简单,从json开始讲起。
2.网页解析
除了纯JSON数据之外,更多的是返回网页,所以网页解析是一个重要的知识点。
网页解析的库非常多,但是常用的也就那几个,所以猪哥就重点讲几个吧:
-
正则:正则匹配网页内容,但是效率低,局限性大。
-
beautifulsoup4:美味汤,简单易于上手,很多人学的第一个解析库。
-
lxml:XPath标准的实现库,据说解析速度很快。
-
pyquery:听名字就知道语法和jquery相似,对熟悉jquery的同学会是个不错的选择。
-
requests_html:有些同学可能还没听过,这是2018年新出的一个解析库,是requests库作者开发的,很多人相信它会成为主流解析库。
常用解析库大概就这几个,如果你觉得还有其他的好用解析库也欢留言!
五 33个爬虫项目实战
WechatSogou [1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。
DouBanSpider [2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1000的高分书籍;可依据不同的主题存储到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。
zhihu_spider [3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo
bilibili-user [4]- Bilibili用户爬虫。总数据数:20119918,抓取字段:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取之后生成B站用户数据报告。
SinaSpider [5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登录,可通过多账号登录来防止新浪的反扒。主要使用 scrapy 爬虫框架。
distribute_crawler [6]- 小说下载分布式爬虫。使用scrapy,Redis, MongoDB,graphite实现的一个分布式网络爬虫,底层存储MongoDB集群,分布式使用Redis实现,爬虫状态显示使用graphite实现,主要针对一个小说站点。
CnkiSpider [7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据存储在/data目录下,每个数据文件的第一行为字段名称。
LianJiaSpider [8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登录代码。
scrapy_jingdong [9]- 京东爬虫。基于scrapy的京东网站爬虫,保存格式为csv。
QQ-Groups-Spider [10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每个漏洞的文本内容存在MongoDB中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概需要10G空间、2小时(10M电信带宽);爬取全部知识库,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为前端。
spider[12]- hao123网站爬虫。以hao123为入口页面,滚动爬取外链,收集网址,并记录网址上的内链和外链数目,记录title等信息,windows7 32位上测试,目前每24个小时,可收集数据为10万左右
findtrip [13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国内两大机票网站(去哪儿 + 携程)。
163spider [14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫
doubanspiders[15]- 豆瓣电影、书籍、小组、相册、东西等爬虫集 writen by Python
QQSpider [16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。
baidu-music-spider [17]- 百度mp3全站爬虫,使用redis支持断点续传。
tbcrawler[18]- 淘宝和天猫的爬虫,可以根据搜索关键词,物品id来抓去页面的信息,数据存储在mongodb。
stockholm [19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选定的日期范围抓取所有沪深两市股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。
BaiduyunSpider[20]-百度云盘爬虫。
Spider[21]-社交数据爬虫。支持微博,知乎,豆瓣。
proxy pool[22]-Python爬虫代理IP池(proxy pool)。
music-163[23]-爬取网易云音乐所有歌曲的评论。
jandan_spider[24]-爬取煎蛋妹纸图片。
CnblogsSpider[25]-cnblogs列表页爬虫。
spider_smooc[26]-爬取慕课网视频。
CnkiSpider[27]-中国知网爬虫。
knowsecSpider2[28]-知道创宇爬虫题目。
aiss-spider[29]-爱丝APP图片爬虫。
SinaSpider[30]-动态IP解决新浪的反爬虫机制,快速抓取内容。
csdn-spider[31]-爬取CSDN上的博客文章。
ProxySpider[32]-爬取西刺上的代理IP,并验证代理可用性
2018.8.2更新:
webspider[33]-本系统是一个主要使用python3, celery和requests来爬取职位数据的爬虫,实现了定时任务,出错重试,日志记录,自动更改Cookies等的功能,并使用ECharts + Bootstrap 来构建前端页面,来展示爬取到的数据。
六 总结
1 该文章主要讲解python爬虫内容,代码分析,借鉴了其它很好的python帖子。
2 python 和爬虫的学习要不断尝试,逐步进步。
3 python 和爬虫的学习也应该多理解其中的原理,为己所用。
4 该帖子有很多不完善的地方欢迎留言。
参考资料
- https://www.jb51.net/article/164829.htm
- python爬虫项目设置一个中断重连的程序的实现
- 详解python3 + Scrapy爬虫学习之创建项目
- Python即时网络爬虫项目启动说明详解
- Python网络爬虫项目:内容提取器的定义
- python小项目之五子棋游戏
- Python 项目转化为so文件实例
- 解决python web项目意外关闭,但占用端口的问题
- python+Django+pycharm+mysql 搭建首个web项目详解
- 三个python爬虫项目实例代码
- https://blog.csdn.net/u014044812/article/details/78894108