Deep Learning-TensorFlow (6) CNN卷积神经网络_Word2vec及NCE
环境:Win8.1 TensorFlow1.0.1
软件:Anaconda3 (集成Python3及开发环境)
TensorFlow安装:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
参考文档:
1. TensorFlow 官方文档中文版——字词的向量表示
2. peghoty@CSDN——word2vec 中的数学原理详解(五)基于 Negative Sampling 的模型
3. multiangle@CSDN——tensorflow笔记:使用tf来实现word2vec
完整代码参考 multiangle,修改部分 API 可在 @DiamonJoy下载
1. Word2vec
本文将解析建立 TensorFlow 模型 word2vec 学习文字的向量表示即 词嵌套(word embedding)。
关于 word embedding 的基本介绍可查看参考文档1,学习目标总结为将离散符号组成的词汇嵌套于一个连续的向量空间,且语义近似的词汇被映射为相邻的数据点。同时,学习模型还依赖于分布式假设,其核心思想为出现于上下文情景中的词汇都有相类似的语义,因此预测方法则试图直接从某词汇的邻近词汇对其进行预测,在此过程中利用已经学习到的小型且稠密的嵌套向量。
Word2vec 是一种可以进行高效率词嵌套学习的预测模型。其两种变体分别为:连续词袋模型(CBOW)及Skip-Gram 模型。CBOW 根据源词上下文词汇('the cat sits on the')来预测目标词汇(例如,‘mat’),而 Skip-Gram 模型做法相反,它通过目标词汇来预测源词汇。相比之下,Skip-Gram 模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。本文基于 Skip-Gram 建立 TensorFlow 模型。
2. 噪声对比估计(NCE)
神经概率化语言模型通常使用极大似然法 (ML) 进行训练,其中通过 softmax function 来最大化当提供前一个单词 h (代表 "history"),后一个单词的概率 w_t (代表 "target"),
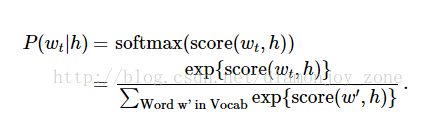
当 score(w_t,h) 计算了文字 w_t 和 上下文 h 的相容性(通常使用向量积)。使用对数似然函数来训练训练集的最大值,比如通过:
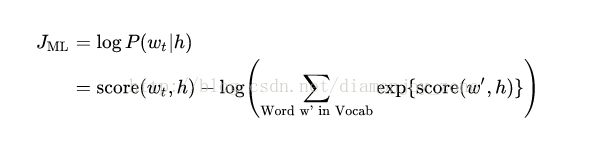
下左图是一个解决语言概率模型的合适的通用方法,然而这个方法实际执行起来开销非常大,因为在每一步训练迭代中需要去计算并正则化当前上下文环境 h 中所有其他 V 单词 w' 的概率得分。

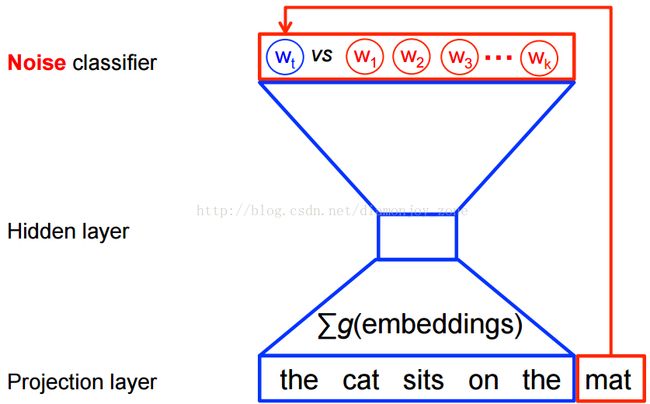
事实上,当使用 word2vec 模型时,并不需要对概率模型中的所有特征进行学习。而 CBOW 模型和 Skip-Gram 模型为了避免这种情况发生,使用一个二分类器(逻辑回归)在同一个上下文环境里从k 虚构的 (噪声) 单词 区分出真正的目标单词 。此时对每个样本的优化目标变为,
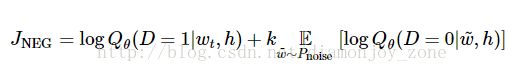
显然目标函数要到达最大值,真实的目标单词需要被分配到较高的概率,同时噪声单词的概率很低。从技术层面来说,这种方法叫做 负抽样(Negative Sampling),使用挑选出来的 k 个 噪声单词,而没有使用整个语料库 V,加速了训练。这方法是基于 noise-contrastive estimation (NCE) ,且在TensorFlow中已经封装了一个很便捷的函数tf.nn.nce_loss(),后面会详细介绍。
3. 模型建立
首先模型的输入是数据集下的词汇,输出为具有上下文关系的目标词汇,在完成预测模型的同时,也完成了 word embedding。例如数据集 【the quick brown fox jumped over the lazy dog】,在 CBOW 中把目标单词左边的内容当做一个‘上下文’,使用大小为1的窗口,这样就得到这样一个由 (上下文, 目标单词) 组成的输入序列:
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
而在 Skip-Gram 中用单个词汇预测它的上下文词汇,因此就变成由 (输入, 输出) 组成的:
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
这里每一个词汇使用它唯一的 id 表示,定义训练输入和标签:
self.train_inputs = tf.placeholder(tf.int32, shape=[self.batch_size])
self.train_labels = tf.placeholder(tf.int32, shape=[self.batch_size, 1])随机初始化一个与词汇 id 一一对应的嵌套参数矩阵,shape 为 [vocab_size, embedding_size],其中 vocab_size 为词汇种数,embedding_size 为嵌套向量的长度:
# 嵌套向量矩阵,初始时为均匀随机正态分布
self.embedding_dict = tf.Variable(
tf.random_uniform([self.vocab_size,self.embedding_size],-1.0,1.0)
)为了提取输入的 batch id 集对应的嵌套参数,可以使用tf.nn.embedding_lookup(self.embedding_dict, self.train_inputs)。
对噪声比对的损失计算使用一个逻辑回归模型,需要对数据集中的每个词汇定义一个权重值和偏差:
# 模型内部参数矩阵,初始为截断正太分布
self.nce_weight = tf.Variable(tf.truncated_normal([self.vocab_size, self.embedding_size],
stddev=1.0/math.sqrt(self.embedding_size)))
self.nce_biases = tf.Variable(tf.zeros([self.vocab_size]))使用噪声比对估计 loss 和 SGD 训练:
# NCE
self.loss = tf.reduce_mean(
tf.nn.nce_loss(
weights = self.nce_weight, # 权重
biases = self.nce_biases, # 偏差
labels = self.train_labels, # 输入的标签
inputs = embed, # 输入向量
num_sampled = self.num_sampled, # 负采样的个数
num_classes = self.vocab_size # 类别数目
)
)4. nce_loss
nce_loss 的实现逻辑如下:
- _compute_sampled_logits:通过这个函数计算出正样本和采样出的负样本对应的 output 和 label
- sigmoid_cross_entropy_with_logits:通过 sigmoid cross entropy 来计算 output 和 label 的 loss,然后 BP。这个函数把最后的问题转化为了 num_sampled + num_real 个二分类问题,所有分类问题使用交叉熵损失函数。
TensorBoard 里还提供了一个 softmax_cross_entropy_with_logits 的函数,和 sigmoid_cross_entropy_with_logits 有所区别:
- sigmoid_cross_entropy_with_logits 的输入是 logits 和 targets,logits 就是神经网络模型中的 W * X + b ,而 targets 的 shape 和 logits 相同,就是正确的label 值,例如这个模型一次要判断100张图是否包含10种动物,这两个输入的shape都是[100, 10],这里10个分类之间是独立的,但不要求是互斥,这种问题是多目标问题,例如在 word2vec 中,一个词汇可以预测上下文中多个词汇。且它采用标准的 Cross Entropy 算法,对 W * X + b 得到的值进行 sigmoid 激活,保证取值在0到1之间,然后放在交叉熵的函数中计算 Loss。
- 还有一种问题是多分类问题,例如我们对年龄特征分为5段,只允许5个值有且只有1个值为1,这种问题使用 softmax_cross_entropy_with_logits,输入是类似的 logits 和 lables 的 shape 一样,但这里要求分类的结果是互斥的,保证只有一个字段有值,例如之前的 CIFAR-10 中图片只能分一类而不像前面判断是否包含多类动物。为什么会有这样的限制?这个函数传入的 logits 是 unscaled 的,并未进行 sigmoid 激活,在函数内部使用softmax,对于任意的输入经过 softmax 都会变成和为1的概率预测值,这个代入变形的 Cross Entroy 算法 - y * ln(a) 算法可以得到更有意义的 Loss 值。但如果是多目标问题,经过 softmax 得到多个和为1的概率,但 label 有多个1无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。
5. 运行结果
TensorFlow 的官方完整代码可参考 tensorflow/models,注意需要先 g++ 编译 word2vec_ops.so 文件。
这里完善了 multiangle 的 代码,实现过程比较简洁,且在中文小说《斗破苍穹》上进行训练,具有很高的参考价值。在读入文本后,采用了预先定义的断句符进行了句分割,在每个句子中采用结巴(jieba)分词进行分词,选取了词频最高的3000个词汇初始化嵌套矩阵训练,每一次训练输入一个句序列:

根据句序列中的上下文构建 batch,进行训练:

完成我们可以得到 trained 嵌套向量矩阵和根据相似性测试预测:

