Improved Techniques for Training GANs翻译与理解
参考博客:https://blog.csdn.net/zijin0802034/article/details/58643889
https://blog.csdn.net/shenxiaolu1984/article/details/75736407
paper:Improved Techniques for Training GANs
code:Theano实现
摘要
我们提出了一些新的结构特征和训练过程可以用到GAN上。我们关注两点应用:半监督学习和生成视觉上真实的图像。我们的主要目标不是训练一个模型给测试数据赋值最大似然,也不要求模型能不用任何标签学得很好。使用我们的方法,可以在MNIST,CIFAR10,SVHN上达到最好的半监督效果。生成图像有很高的质量:生成的MNIST人眼无法区分,CIFAR10错误率21.3%。在ImageNet高分辨率样本上显示了我们的方法可以让模型学到可识别的特征。
1、介绍
GAN是基于博弈论的生成模型方法。GAN训练一个生成网络来生成尽可能真实的图像,一个判别网络尽可能区分真是图像和生成图像。
训练GAN要求找到在连续高维参数下非凸博弈的纳什均衡。但是通常GAN用梯度下降方法去寻找损失函数的最小值,而不是纳什均衡。
本文,我们介绍了几个方法去鼓励GAN博弈的收敛。这些方法的灵感来源于非凸问题的启发式理解。可以帮助提升半监督学习性能和提升采样生成。
2、相关工作
我们结合了最近一些关于稳定训练和提升样本质量的工作,例如使用了DCGAN。
我们的方法之一,特征匹配(feature matching),在本质上类似于使用最大平均偏差(maximum mean discrepancy)。另一个方法,小批量特征(minibatch features),基于批量标准化的部分思想,我们提出的虚拟批量标准化(virtual batch normalization) 是批量标准化的直接扩展。
我们工作的主要目标是提升生成对抗网络在半监督学习上的效果(在这种情况下,通过学习额外的未标记的例子来提高监督任务的性能,在这里是分类)。
3、模型改进
假设![]() 是判别网络的损失函数,
是判别网络的损失函数,![]() 是生成网络的损失函数。纳什均衡点就是参数空间的点
是生成网络的损失函数。纳什均衡点就是参数空间的点![]() ,
, 对于
对于![]() 取得最小值,
取得最小值, 对于
对于![]() 取得最小值。对抗网络中,
取得最小值。对抗网络中,![]() 的更新减少了,但是同时又增加了,
的更新减少了,但是同时又增加了,![]() 的更新减少了,同样又增加了。例如下面的例子,一个网络想要通过修改
的更新减少了,同样又增加了。例如下面的例子,一个网络想要通过修改 来最小化
来最小化![]() ,另一个网络想要通过修改
,另一个网络想要通过修改 来最小化
来最小化![]() ,使用梯度下降的方法会进入一个稳定的轨道中,并不会收敛到(0,0)(0,0)点。
,使用梯度下降的方法会进入一个稳定的轨道中,并不会收敛到(0,0)(0,0)点。
对抗网络的目的需要在高维非凸的参数空间中,找到一个纳什均衡。但是GAN网络使用梯度下降的方法只会找到低的损失,不能找到真正的纳什均衡。本论文中,作者通过引入了一些方法,提高网络的收敛。
3.1 特征匹配(feature matching)
原始的GAN网络的目标函数需要最大化判别网络的输出。作者提出了新的目标函数,motivation就是让生成网络产生的图片,经过判别网络后的中间层的feature 和真实图片经过判别网络的feature尽可能相同。假定 为判别网络中间层输出的feature map。生成网络的目标函数定义如下:
为判别网络中间层输出的feature map。生成网络的目标函数定义如下:
![]()
判别网络按照原来的方式训练。相比原先的方式,生成网络G产生的数据更符合数据的真实分布。尽管不能保证到达均衡点,不过收敛的稳定性应该是有所提高。
3.2 小批量的训练判别器(minibatch discrimination)
判别网络如果每次只看单张图片,如果判断为真的话,那么生成网络就会认为这里一个优化的目标,导致生成网络会快速收敛到当前点。作者使用了minibatch的方法,每次判别网络输入一批数据进行判断。
minibatch disrimination通过计算一个minibath中样本D网络中某一层特征图之间的差异信息,作为D网络中下一层的额外输出,达到每个样本之间的信息交互目的。具体的,假设样本 在D网络中某一层的特征向量为
在D网络中某一层的特征向量为![]() ,然后将
,然后将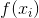 乘以一个张量
乘以一个张量![]() 得到张量
得到张量 ![]() 。然后对每个样本之间的M的行向量计算L1距离,得到
。然后对每个样本之间的M的行向量计算L1距离,得到![]() ,然后将
,然后将![]() 所有的相加得到
所有的相加得到![]() ,最后将B个
,最后将B个![]() 并起来得到一个大小为B的向量
并起来得到一个大小为B的向量![]() :
:
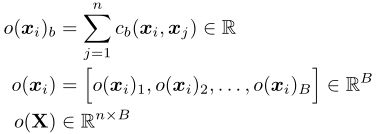
上述过程如下图所示:
接着,将![]() 和合并成一个向量作为D网络下一层的输入。
和合并成一个向量作为D网络下一层的输入。
和以前一样,鉴别器仍然需要为每个样本输出一个数字(1/真,0/假),表示它来自训练数据的可能性:因此,鉴别器的任务仍然有效地将单个例子分类为真实数据或生成数据,但它现在可以使用minibatch中的其他特征作为辅助信息。 Minibatch使我们能够非常快速地生成视觉上吸引人的样本,并且在这方面它优于特征匹配(第6节)。 然而,有趣的是,如果目标是使用第5节中描述的半监督学习方法获得强分类器,则发现特征匹配更好。
3.3 历史平均(Historical averaging)
在生成网络和判别网络的损失函数中添加一个项:
![\left \| \theta -\frac{1}{t}\sum _{i=1}^{t}\theta [i] \right \|^{2}](http://img.e-com-net.com/image/info8/bfa7b963f026435583c389233a7a249d.gif)
公式中![]() 表示在i时刻的参数。这个项在网络训练过程中,也会更新。加入这个项后,梯度就不容易进入稳定的轨道,能够继续向均衡点更新。
表示在i时刻的参数。这个项在网络训练过程中,也会更新。加入这个项后,梯度就不容易进入稳定的轨道,能够继续向均衡点更新。
3.4 类别标签平滑(One-side label smoothing)
将正例label乘以 ,, 负例label乘以
,, 负例label乘以 ,最优的判别函数分类器变为:
,最优的判别函数分类器变为:
![]()
也就是判别器的目标函数中正负样本的系数不再是0-1,而是α和β。在应用的时候将真实数据的正样本判别为0.9和生成数据的负样本设置为0.1既可。
3.5 虚拟的BN(Virtual batch normalization)
DCGAN使用了BN,取得了不错的效果。但是BN有个缺点,即BN会时G网络生成一个batch的图片中,每张图片都有相关联(如,一个batch中的图片都有比较多的绿色)。为了解决这个问题可以使用Reference batch normalization。Reference batch normalization(包含运行网络两次: 第一次是对一个minibatch的参考样本, 这里的参考样本是在训练开始以前被采样并且是保持不变的; 另一个是对当前的minibatch的样本进行训练。 特征的平均值和标准差使用参考样本的batch进行计算。 然后,使用这些统计的信息对两个batch的特征进行标准化处理。 此方法的一个缺点是模型容易对参考batch的样本过拟合。 为了稍微缓解此问题, 作者提出了virtual batch normalization, 对一个样本标准化时使用的统计信息是通过此样本与参考batch的联合来进行计算的。
4、评估生成图像质量
GAN缺乏目标函数,难以比较不同模型的性能,所以作者提出了两种评估图像生成质量的方法。
①MTurk
类似于图灵测验,选定一部分人,将真实图片和生成图片掺杂在一起,这些邀请人需要逐个指出给定图片是真实的还是生成的。这种方法是不可靠的,因为人的判断极易受实验设置以及反馈信息的影响。
② inception score
作为图灵测验的一个替代标准,作者提出了一个inception model,这个模型以生成图片x为输入,以x的推断类标签概率![]() 为输出。作者认为良好的样本(图像看起来像来自真实数据分布的图像)预计会产生:
为输出。作者认为良好的样本(图像看起来像来自真实数据分布的图像)预计会产生:
低熵![]() :即高预测置信度,好样本应该包含明确有意义的目标物体。
:即高预测置信度,好样本应该包含明确有意义的目标物体。
高熵![]() 即高度变化的预测(也就是生成图像的多样性),这是一个边际分布,也就是说所有的x应该尽量分属于不同的类别,而不是属于同一类别。
即高度变化的预测(也就是生成图像的多样性),这是一个边际分布,也就是说所有的x应该尽量分属于不同的类别,而不是属于同一类别。
因此,inception score定义为![]() .
.
5、半监督学习
标准的分类网络将数据输出为可能的 个classes,然后对K维的向量
个classes,然后对K维的向量![]() (这里面的l就是softmax之前的输出)使用softmax:
(这里面的l就是softmax之前的输出)使用softmax:
![]()
标准的分类是有监督的学习,模型通过最小化交叉熵损失,获得最优的网络参数。
对于GAN网络,可以把生成网络的输出作为第K+1类,相应的判别网络变为K+1类的分类问题。用![]() 表示生成网络的图片为假,用来代替标准GAN的
表示生成网络的图片为假,用来代替标准GAN的![]() 。对分类网络,只需要知道某一张图片属于哪一类,不用明确知道这个类是什么,通过
。对分类网络,只需要知道某一张图片属于哪一类,不用明确知道这个类是什么,通过![]() 就可以训练。 所以损失函数就变为了:
就可以训练。 所以损失函数就变为了:
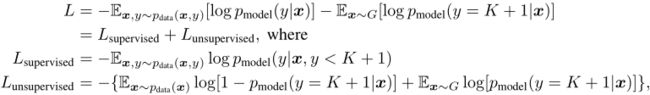
如果令![]() ,上述无监督的表达式就是GAN的形式:
,上述无监督的表达式就是GAN的形式:
![]()
模型的结构可看做:
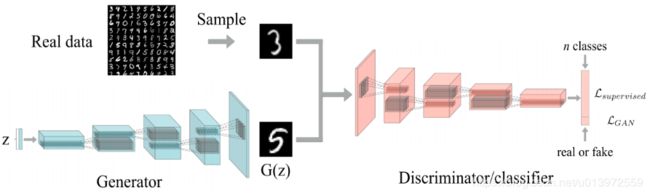
其实整个系统将误差函数拆开,共有三种误差:
对于训练集中的有标签样本,考察估计的标签是否正确。即,计算分类为相应的概率:
![]()
对于训练集中的无标签样本,考察是否估计为“真”。即,计算不估计为K+1类的概率:
![]()
对于生成器产生的伪样本,考察是否估计为“伪”。即,计算估计为K+1类的概率:
![]()
考虑softmax函数的一个特性:
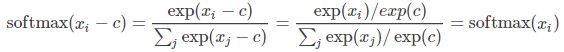
即,如果softmax的输入各维减去同一个数,softmax结果不变。
于是可以令![]() ,就有
,就有![]() ,
,![]() ,并且最终结果不会改变.那么上述的三个误差将会变化。
,并且最终结果不会改变.那么上述的三个误差将会变化。
对于第一个误差,由于分类器输入必定来自前K类,所以可以直接使用 的前K维:
的前K维:
后面两个误差(略去期望号)变为:
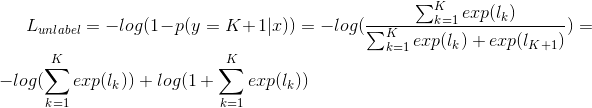
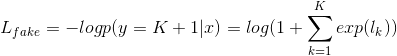
这样我们的优化目标就变为:
对于分类器来说,希望上述误差尽量小。引入权重 ,得到分类器优化目标:
,得到分类器优化目标:
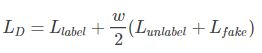
对于生成器来说,希望其输出的伪样本能够骗过分类器。生成器优化目标与分类器的第三项相反:
![]()
除了在半监督学习中实现最先进的结果之外,上述方法还具有改善由人类注释者判断的所生成图像的质量的惊人效果。原因似乎是人类视觉系统非常适合图像统计,这可以帮助推断图像所代表的对象类别,而对于对图像解释不太重要的局部统计数据可能不那么敏感。我们在人类注释器报告的质量与我们在第4节中开发的初始得分之间发现了高度相关性,这得到了明确构建以测量生成图像的“客观性”。通过使鉴别器D对图像中所示的对象进行分类,我们将其偏向于开发内部表示,其强调人类强调的相同特征。该效果可以被理解为用于转移学习的方法,并且可以更广泛地应用。我们将进一步探索这种可能性以用于未来的工作。
6、实验
6.1 MNIST
在使用特征匹配(第3.1节)的半监督学习期间由发生器生成的样本看起来不具有视觉吸引力(左图3)。 通过使用minibatch鉴别器(第3.2节),我们可以提高他们的视觉质量。 在MTurk上,注释者能够在52.4%的案例(总共2000票)中区分样本,其中50%将通过随机猜测获得。 同样,我们机构的研究人员无法找到任何可以让他们区分样本的文物。 然而,具有小批量识别的半监督学习不能产生与特征匹配一样好的分类器。

(左)半监督训练过程中模型生成的样本。样品与来自MNIST数据集的图像有着明显的区别。(右)小批量鉴别产生的样品。样品与数据集样本完全不可区分。

分类错误的样本数量
6.2 CIFAR-10(与MNIST相同)



上图是Inception score。该评分与人的判断高度相关,自然图像得分最高,生成样本得分相对最低。该指标使我们能够避免依赖人类评估。 “我们的方法”包括本工作中描述的所有技术,但特征匹配和历史平均除外。剩下的实验是消融实验,表明我们的技术是有效的。 “-VBN + BN”用BN替换生成器中的VBN,如在DCGAN中那样。这导致CIFAR上的样品质量略有下降。 VBN对ImageNet更重要。 “-L + HA”从训练过程中删除标签,并添加历史平均值以进行补偿。 HA使得仍然可以生成一些可识别的对象。如果没有HA,样品质量会大大降低(参见“-L”)。 “-LS”消除了标签平滑,并且相对于“我们的方法”,性能明显下降。“ - MBF”消除了小批量功能,导致性能大幅下降,甚至比移除标签时产生的下降更大。添加HA无法阻止此问题。
6.3 SVHN
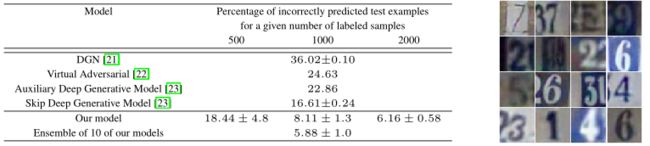
6.4 ImageNet
我们在前所未有的数据集上测试了我们的技术:来自ILSVRC2012数据集的128×128图像,包含1,000个类别。由于GAN倾向于低估分布中的熵,因此大量的对象类对于GAN尤其具有挑战性。 我们使用TensorFlow [26]广泛修改了公开可用的DCGAN实现,以使用多GPU实现实现高性能。 没有修改的DCGAN学习一些基本的图像统计数据并生成具有某种自然颜色和纹理的连续形状,但不学习任何对象。 使用本文中描述的技术,GAN学习生成类似于动物但具有不正确解剖结构的对象。 结果如图所示,左边是DCGAN的生成图像,右边是我们的技术生成的图像(新技术使GAN能够学习动物的可识别特征,例如毛皮,眼睛和鼻子,但是这些特征没有被正确地组合以形成具有真实解剖结构的动物。)。

7、结论
生成性对抗性网络是一类很有前途的生成模型,迄今为止一直受到不稳定训练和缺乏适当评估指标的阻碍。 这项工作为这两个问题提供了部分解决方案。 我们提出了几种稳定训练的技术,使我们能够训练以前无法解决的模型。 此外,我们提出的评估指标(the Inception score)为我们提供了比较这些模型质量的基础。 我们将我们的技术应用于半监督学习的问题,在计算机视觉中的许多不同数据集上实现最先进的结果。 这项工作的贡献具有实际意义; 我们希望在未来的工作中培养更严格的理论知识。