本篇同样是使用TF-IDF算法提取关键词,只不过是使用sklearn中封装好的包进行提取。不同的是对原始语料库格式的要求,sklearn要求语料库中文章的分词之间以空格分隔,如以下示例:
segment
第一篇文章 我 是 中国 人 。
第二篇文章 你 是 美国 人 。
第三篇文章 他 叫 什么 名字?
第四篇文章 她 是 谁 啊?
TF-IDF的实验参考上一篇使用TF-IDF算法提取文章的关键词
开发环境
系统: macOS Sierra; 开发软件: PyChram CE; 运行环境: Python3.6
-
导入需要用到的包
import os
import codecs
import pandas
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import numpy
-
创建语料库
# 创建语料库
filePaths = []
fileContents = []
for root, dirs, files in os.walk(
'data/SogouC.mini/Sample'
):
for name in files:
filePath = os.path.join(root, name)
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
filePaths.append(filePath)
fileContents.append(fileContent)
corpus = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
语料库中的文章是从搜狗实验室下载的,内容如下:

目录结构.png
创建的语料库如下:

语料库.png
-
文章分词
# 匹配中文分词
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
# 分词,转化为sklearn能识别的数据格式(分词之间以空格分开)
for index, row in corpus.iterrows():
segments = []
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if zhPattern.search(seg):
segments.append(seg)
row['fileContent'] = ' '.join(segments) # 将文章分词以空格分开,以便符合sklearn数据格式要求
分词后结果如下:

分词.png
-
读取停用词文件
# 读取停用词文件
stopWords = pandas.read_csv(
'data/StopwordsCN.txt',
encoding='utf-8',
index_col=False,
quoting=3,
sep='\t'
)
停用词文件内容如下:

停用词.png
-
使用Count创建词频矩阵(即得到TF矩阵)
# 提取TF
countVectorizer = CountVectorizer( # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
stop_words=list(stopWords['stopword'].values), # stopWords['stopword'].values为ndarray类型.stop_words接受list类型
min_df=0,
token_pattern=r"\b\w+\b"
)
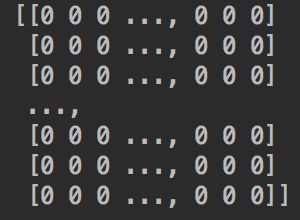
textVector = countVectorizer.fit_transform(corpus['fileContent']) # 将文章转化为词频矩阵,得到TF矩阵
print(textVector.todense()) # 使用todense 方法获得该矩阵
运行结果如下:
TF.png
-
使用计算TF-IDF(即得到TF-IDF矩阵)
# 计算TF-IDF
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(textVector) # 为词频矩阵的每个词加上权重(即TF * IDF),得到TF-IDF矩阵
print(tfidf.todense())
运行结果如下:

TF-IDF.png
-
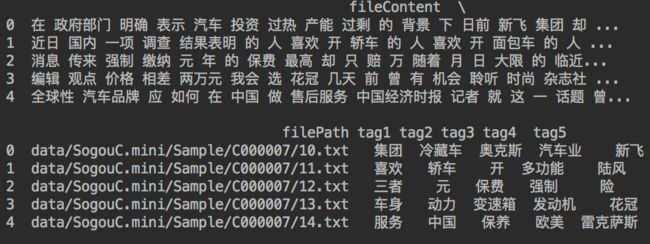
提取每篇文章的前五个关键词
# 提取关键词
sort = numpy.argsort(tfidf.toarray(), axis=1)[:, -5:] # 将二维数组中每一行按升序排序,并提取每一行的最后五个(即数值最大的的五个)
names = countVectorizer.get_feature_names() # 获取词袋模型中的所有词语
keyWords = pandas.Index(names)[sort].values
tagDF = pandas.DataFrame({
'filePath': corpus.filePath,
'fileContent': corpus.fileContent,
'tag1': keyWords[:, 0],
'tag2': keyWords[:, 1],
'tag3': keyWords[:, 2],
'tag4': keyWords[:, 3],
'tag5': keyWords[:, 4]
})
运行结果如下:
result.png
-
参考:
小蚊子数据分析