_00013 一致性哈希算法 Consistent Hashing 探讨以及相应的新问题出现解决
博文作者: 妳那伊抹微笑
博客地址: http://blog.csdn.net/u012185296
个性签名: 世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前,妳却感觉不到我的存在
技术方向: Flume+Kafka+Storm+Redis/Hbase+Hadoop+Hive+Mahout+Spark ... 云计算技术
转载声明: 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明,谢谢合作!
qq交流群: 214293307
一、业务场景
假如我们现在有12台Redis服务器(其它的什么东西也行),有很多User(用户)的数据数据从前端过来,然后往12台redis服务器上存储,在存储中就会出现一个问题,12台服务器,有可能其中几台Redis服务器上(简称集群A)存了很多的数据,然后另外几台Redis服务器(简称集群B)上存的数据很少,这样的话那 A 上的读写压力就会很大(当然,这个要看你的数据量的大小了,如果你数据量很小的话,基本无压力了,但是数据量很大,那就 、、、),对于这样的问题,我们通常的解决办法是什么呢 ?一般通常会想到的就是哈希取余了吧!也就是 Hash(userid)% N (N=12),这样的话也能适当的减小很多压力了,但是这样的话又会产生一些新的问题,增加节点跟减少节点 :
1、减少节点:
假如有一台Redis服务器挂掉了,那么是否这样 Hash(userid)% N (N=12) 哈希取余到该Redis的数据会全部丢失呢 ?如果不要该节点,那么只剩下11台Redis服务器了,原来的映射关系 Hash(userid)% N (N=12) 变成了 Hash(userid)% (N-1) (N=12),重点是数据丢失如何找回 ?
2、增加节点:
假如有一天想增加Redis服务器了,这时候麻烦来了,这时候需要将原来的映射关系 Hash(userid)% N (N=12) 变成 Hash(userid)% (N+1) (N=12) 了,跟 减少节点一样,这岂不是以前所有的映射全部失效了 ?这不是坑爹么!!!数据混乱,后台可能瞬间垮掉,那样的代价很大 、、、
3、硬件越来越便宜了,公司越来越大了,然后服务器越来越多了:
哈希取余 Hash(userid)% N (N=12) 就也完全不能满足需求了,不能修改映射关系,修改之后灰常麻烦 。
这时候该怎么办呢 ?有什么办法可以改变这个状况呢,当然就是一致性哈希 Consistent Hashing了 ......
自己懒得写原理了,下面引用了 http://blog.csdn.net/sparkliang/article/details/5279393,详细介绍了一致性哈希,灰常好 、、、
二、 hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
三、Consistent hashing 算法的原理
Consistent Hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
四、环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。
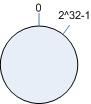
图 1 环形 hash 空间
五、把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
六、 把cache 映射到hash 空间
Consistent Hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash 值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为 hash输入。
七、把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2 和object3 对应到 cache C ; object4 对应到 cache B ;
八、 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时, cache会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
九、移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 顺时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
十、添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 顺时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。
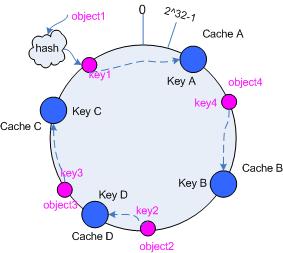
图 5 添加 cache D 后的映射关系
十一、虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。
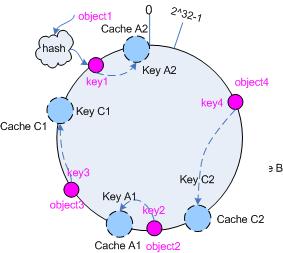
图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache 时的映射关系如图 7 所示。
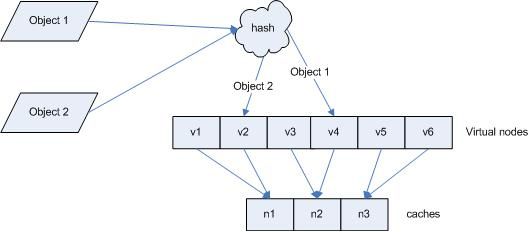
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
引用了这位大神的小结
Consistent hashing 的基本原理就是这些,具体的分布性等理论分析应该是很复杂的,不过一般也用不到。
http://weblogs.java.net/blog/2007/11/27/consistent-hashing 上面有一个 java 版本的例子,可以参考。
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx 转载了一个 PHP 版的实现代码。
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本
先上代码吧,等下说一下一致性哈希中的一些问题
1、未重构的代码
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHash {
private final HashFunction hashFunction;
private final int numberOfReplicas;
private final SortedMap circle = new TreeMap();
public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,
Collection nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
public void add(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.put(hashFunction.hash(node.toString() + i), node);
}
}
public void remove(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove(hashFunction.hash(node.toString() + i));
}
}
public T get(Object key) {
if (circle.isEmpty()) {
return null;
}
int hash = hashFunction.hash(key);
if (!circle.containsKey(hash)) {
SortedMap tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
} 2、重构后的代码,将哈希算法跟虚拟节点的方法给抽取出来,模版方法设计模式
2.1 AbstractConsistentHash
package cn.yting.conhash;
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 将Hash算法跟虚拟节点的虚拟方式给抽出来,模版方法设计模式
*
* @Author 妳那伊抹微笑
*
*/
public abstract class AbstractConsistentHash {
/**
* 复制节点,增加每个节点的复制节点有利于负载均衡
*/
protected int numberOfReplicas = 8;
/**
* 一致性哈希
*/
protected SortedMap circle = new TreeMap();
/**
* 自定义一致性哈希算法
*/
protected abstract long defineHash(String key);
/**
* 自定义circle key
*/
protected abstract String defineCircleKey(String node, int i);
public AbstractConsistentHash() {
}
public AbstractConsistentHash(int numberOfReplicas, Collection nodes) {
this.numberOfReplicas = numberOfReplicas;
for (String node : nodes) {
addNode(node);
}
}
/**
* 添加节点
*/
public void addNode(String node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
/*
* 计算key的哈希算法
*/
long key = defineHash(defineCircleKey(node, i));
circle.put(key, node);
}
}
/**
* 删除节点
*/
public void removeNode(String node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
/*
* 计算key的哈希算法
*/
long key = defineHash(defineCircleKey(node, i));
circle.remove(key);
}
}
/**
* 查找节点,取得顺时针方向上最近的一个虚拟节点对应的实际节点
*/
public String getNode(String node) {
if (circle.isEmpty()) {
return null;
}
/*
* 计算key的哈希算法
*/
long key = defineHash(node);
if (!circle.containsKey(key)) {
SortedMap tailMap = circle.tailMap(key);
key = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(key);
}
}
package cn.yting.conhash;
import java.util.Set;
/**
* HashCode 一致性哈希,使用自带的hashCode计算hash值
*
* @Author 妳那伊抹微笑
*
*/
public class HashCodeConsistentHash extends AbstractConsistentHash {
public HashCodeConsistentHash(int numberOfReplicas, Set nodes) {
super(numberOfReplicas, nodes);
}
@Override
protected long defineHash(String key) {
return key.hashCode();
}
@Override
protected String defineCircleKey(String node, int i) {
if(i > 99){
return node + "-" + i;
}else if(i > 9){
return node + "-0" + i;
}else{
return node + "-00" + i;
}
}
}
2.3 CRC32 一致性哈希实现方式
package cn.yting.conhash;
import java.util.Set;
import java.util.zip.CRC32;
/**
* HashCode 一致性哈希,使用CRC32算法计算hash值
*
* @Author 妳那伊抹微笑
*
*/
public class CRC32ConsistentHash extends AbstractConsistentHash {
public CRC32ConsistentHash(int numberOfReplicas, Set nodes) {
super(numberOfReplicas, nodes);
}
@Override
protected long defineHash(String key) {
CRC32 hash = new CRC32();
hash.update(key.getBytes());
return (int)hash.getValue();
}
@Override
protected String defineCircleKey(String node, int i) {
return (node+i);
}
}
2.4 MD5 一致性哈希 实现方式
package cn.yting.conhash;
import java.nio.charset.Charset;
import java.security.MessageDigest;
import java.util.Set;
/**
* HashCode 一致性哈希,使用自MD5算法计算hash值
*
* @Author 妳那伊抹微笑
*
*/
public class MD5ConsistentHash extends AbstractConsistentHash{
public MD5ConsistentHash(int numberOfReplicas, Set nodes) {
super(numberOfReplicas, nodes);
}
@Override
protected String defineCircleKey(String node, int i) {
if(i > 99){
return node + "-" + i;
}else if(i > 9){
return node + "-0" + i;
}else{
return node + "-00" + i;
}
}
@Override
protected long defineHash(String key) {
try {
MessageDigest md5 = MessageDigest.getInstance("MD5");
md5.update(key.getBytes(Charset.forName("UTF8")));
byte[] digest = md5.digest();
long hash = 0;
for (int i = 0; i < 4; i++) {
hash += ((long) (digest[i * 4 + 3] & 0xFF) << 24)
| ((long) (digest[i * 4 + 2] & 0xFF) << 16)
| ((long) (digest[i * 4 + 1] & 0xFF) << 8)
| ((long) (digest[i * 4 + 0] & 0xFF));
}
System.out.println(key+ "--->" + hash);
return hash;
} catch (Exception ex) {
return -1;
}
}
}
# 完整案例(CRC32实现方式)这里是网Redis集群中写入数据,HashMap类型的数据
package cn.yting.conhash;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* 一致性哈希Utils, 实现了redis中hash的一般操作
*
* @Author 妳那伊抹微笑
*
*/
public class ConsistentHashRedisUtils {
/**
* redis server properties 配置文件的路径
*/
private static final String REDIS_SERVERS_HANGZHOU_PROPERTIES = "../../conf/analysis-redis-servers-hangzhou.properties";
/**
* 日志对象
*/
private Log log = LogFactory.getLog(this.getClass());
/**
* 一致性哈希
*/
private AbstractConsistentHash hash;
/**
* Redis连接池
*/
private Map jedisPools = new HashMap();;
/**
* 外网地址到内网地IP映射
*/
private Map redisNodeMaps = new LinkedHashMap();
/**
* 是否转换到内网地址创建jedis对象
*/
private boolean isConvertIp = false;
/**
* 虚拟节点个数
*/
private static int numberOfReplicas = 8;
public ConsistentHashRedisUtils() {
this(numberOfReplicas);
}
public ConsistentHashRedisUtils(int numberOfReplicas) {
redisNodeMaps = getRedisConfNodeMaps();
hash = new CRC32ConsistentHash(numberOfReplicas, redisNodeMaps.keySet());
}
/**
* hset
*
* @param key
* @param field
* @param value
*/
public void hset(String key, String field, String value) {
JedisPool pool = null;
Jedis jedis = null;
try {
pool = getJedisPool(key);
jedis = pool.getResource();
jedis.hset(key, field, value);
} catch (Exception e) {
log.error("Redis hset exception : " + key, e);
pool.returnBrokenResource(jedis);
} finally {
pool.returnResource(jedis);
}
}
/**
* hincrBy
*
* @param key
* @param field
* @param value
*/
public void hincrBy(String key, String field, long value) {
JedisPool pool = null;
Jedis jedis = null;
try {
pool = getJedisPool(key);
jedis = pool.getResource();
jedis.hincrBy(key, field, value);
} catch (Exception e) {
log.error("Redis hincrBy exception : " + key, e);
pool.returnBrokenResource(jedis);
} finally {
pool.returnResource(jedis);
}
}
/**
* hget
*
* @param key
* @param field
* @return
*/
public String hget(String key, String field) {
JedisPool pool = null;
Jedis jedis = null;
String result = null;
try {
pool = getJedisPool(key);
jedis = pool.getResource();
result = jedis.hget(key, field);
} catch (Exception e) {
log.error("Redis hget exception : " + key, e);
pool.returnBrokenResource(jedis);
} finally {
pool.returnResource(jedis);
}
return result;
}
/**
* hgetAll
*
* @param key
* @return map
*/
public Map hgetAll(String key) {
JedisPool pool = null;
Jedis jedis = null;
Map result = null;
try {
pool = getJedisPool(key);
jedis = pool.getResource();
result = jedis.hgetAll(key);
} catch (Exception e) {
log.error("Redis hgetAll exception : " + key, e);
pool.returnBrokenResource(jedis);
} finally {
pool.returnResource(jedis);
}
return result;
}
/**
* hdel
*
* @param key
* @param field
*/
public void hdel(String key, String field) {
JedisPool pool = null;
Jedis jedis = null;
try {
pool = getJedisPool(key);
jedis = pool.getResource();
jedis.hdel(key, field);
} catch (Exception e) {
log.error("Redis hdel exception : " + key, e);
pool.returnBrokenResource(jedis);
} finally {
pool.returnResource(jedis);
}
}
/**
* 通过userid获取对应的jedis连接
*
* @param userid
* @return
* @throws Exception
*/
private JedisPool getJedisPool(String userid) throws Exception {
String key = this.hash.getNode(userid);
JedisPool pool = this.jedisPools.get(key);
if (pool == null) {
String outKey = key;
/*
* 将外网ip转换内网ip
*/
if (this.isConvertIp) {
key = this.redisNodeMaps.get(key);
if (key == null) {
throw new Exception("not " + key + " in redisNodeMaps");
}
}
String[] host_port = key.split(":");
pool = getJedisPool(host_port);
log.info("-------------------->Redis ip--->port : " + host_port[0] + "--->" + host_port[1]);
this.jedisPools.put(outKey, pool);
}
return pool;
}
/**
* 获得redis的连接池
*
* @param host_port
* @return
*/
private JedisPool getJedisPool(String[] host_port) {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxActive(500);
config.setMaxIdle(10);
config.setMaxWait(3000000);
config.setTestOnBorrow(true);
config.setTestOnReturn(true);
return new JedisPool(config, host_port[0], Integer.parseInt(host_port[1]));
}
/**
* 关闭所有redis链接
*/
public void closeAllConnection() throws Exception {
for (String key : this.jedisPools.keySet()) {
JedisPool pool = this.jedisPools.get(key);
if (pool != null) {
pool.destroy();
}
}
}
/**
* 从配置文件中获取Redis集群的IP
*
* @return
*/
private Map getRedisConfNodeMaps(){
Map rmaps = null;
String line = null;
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(this.getClass().getResourceAsStream(REDIS_SERVERS_HANGZHOU_PROPERTIES)));
rmaps = new LinkedHashMap();
String[] splits = null;
String outIp = null;
String inIp = null;
while((line=reader.readLine())!=null){
if(line.trim().length() <5 || line.trim().startsWith("#")) continue;
log.info("redis server : " + line);
splits = line.split(" +|\t+");
outIp = splits[0];
inIp = splits[1];
rmaps.put(outIp, inIp);
}
log.info("ConsistentHashRedisUtils initialize configure ../../conf/analysis-redis-servers-hangzhou.properties is successful ...");
} catch (Exception e) {
log.error("ConsistentHashRedisUtils initialize error : " + line, e);
}
return rmaps;
}
}
redis-servers.properties 参考的配置文件,这里是外网转内网的IP,读者可以自行修改一下、、、
# redis servers
20.20.20.234:6379 192.168.1.109:6379
20.20.20.234:6380 192.168.1.109:6380
20.20.20.234:6381 192.168.1.109:6381
20.20.20.235:6379 192.168.1.110:6379
20.20.20.235:6380 192.168.1.110:6380
20.20.20.235:6381 192.168.1.110:6381
20.20.20.236:6379 192.168.1.111:6379
20.20.20.236:6380 192.168.1.111:6380
20.20.20.236:6381 192.168.1.111:6381
20.20.20.237:6379 192.168.1.112:6379
20.20.20.237:6380 192.168.1.112:6380
20.20.20.237:6381 192.168.1.112:6381
20.20.20.238:6379 192.168.1.113:6379
20.20.20.238:6380 192.168.1.113:6380
20.20.20.238:6381 192.168.1.113:6381
20.20.20.239:6379 192.168.1.114:6379
20.20.20.239:6380 192.168.1.114:6380
20.20.20.239:6381 192.168.1.114:6381
20.20.20.243:6379 192.168.1.127:6379
20.20.20.243:6380 192.168.1.127:6380
20.20.20.243:6381 192.168.1.127:6381
20.20.20.243:6382 192.168.1.127:6382
20.20.20.243:6383 192.168.1.127:6383
20.20.20.243:6384 192.168.1.127:6384
20.20.20.243:6385 192.168.1.127:6385
20.20.20.243:6386 192.168.1.127:6386
20.20.20.244:6379 192.168.1.128:6379
20.20.20.244:6380 192.168.1.128:6380
20.20.20.244:6381 192.168.1.128:6381
20.20.20.245:6379 192.168.1.129:6379
20.20.20.245:6380 192.168.1.129:6380
20.20.20.245:6381 192.168.1.129:6381
20.20.20.246:6379 192.168.1.130:6379
20.20.20.246:6380 192.168.1.130:6380
20.20.20.246:6381 192.168.1.130:6381
20.20.20.247:6379 192.168.1.131:6379
20.20.20.247:6380 192.168.1.131:6380
20.20.20.247:6381 192.168.1.131:6381
20.20.20.248:6379 192.168.1.132:6379
20.20.20.248:6380 192.168.1.132:6380
20.20.20.248:6381 192.168.1.132:6381
20.20.20.249:6379 192.168.1.133:6379
20.20.20.249:6380 192.168.1.133:6380
20.20.20.249:6381 192.168.1.133:63811、减少节点
以上的代码还没有解决数据转移的问题,比如其中一台Redis服务器挂掉了,应该将数据转移到该服务器顺时针最近的那一台活着的服务器上去,而且以后数据恢复,还需要自己写代码做数据校验,数据找回等等!!!这也是一个麻烦的问题 、、、(至少数据不会丢失了,这点还是不错的,数据校验跟数据找回的代码写好后,也可以一劳永逸了,嘎嘎!)
2、增加节点
由于使用了虚拟节点的方式,上面的虚拟节点数量为8,现在新增一台Redis服务器,也会虚拟出8台虚拟节点出来,这里原先假设的是有12台Redis服务器,假如现在的这8台虚拟节点如果刚好分布到了其他8台虚拟节点之间,也就是意味着另外8台Redis中差不多每台Rdis服务器都会有八分之一的数据会跑到现在新增的这台Redis服务器上,这样也会造成数据混乱,这该如何解决 、、、也就是新增节点之后还是破坏了原有的映射关系,当然知道了这样的原理之后也是可以写代码数据校验跟找回的,重新平衡服务器的数据,不过那也太麻烦点了,伤不起啊!假如这里虚拟节点的数据变大了,那以后增加节点是不是要做的工作就更大了,这 、、、
综上所述,一致性哈希这个理论虽然不错,但是想要完美的实现出来还是要点时间的,重点就是数据校验跟数据找回了,不会有人把这样完美的成果给发到网上吧,这 、、、、、、
转载请注明本文地址: _00013 一致性哈希算法 Consistent Hashing 探讨以及相应的新问题出现解决