原文 ImageNet Classification with Deep ConvolutionalNeural Networks
下载地址:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
在这之前,关于AlexNet的讲解的博客已经有很多,我认为还是有必要自己亲自动手写一篇关于AlexNet相关的博客,从而巩固我的理解。
一 介绍
Alex Krizhevsky等人训练了一个大型的卷积神经网络用来把ImageNet LSVRC-2010比赛中120万张高分辨率的图像分为1000个不同的类别。在测试卷上,获得很高准确率(top-1 and top-5 error rates of 37.5%and 17.0% ).。通过改进该网络,在2012年ImageNet LSVRC比赛中夺取了冠军,且准确率远超第二名(top-5 test error rate of 15.3%,第二名26.2%。这在学术界引起了很大的轰动,开启了深度学习的时代,虽然后来大量比AlexNet更快速更准确的卷积神经网络结构相继出现,但是AlexNet作为开创者依旧有着很多值得学习参考的地方,它为后续的CNN甚至是R-CNN等其他网络都定下了基调,所以下面我们将从AlexNet入手,理解卷积神经网络的一般结构。
AlexNet网络包括了6000万个参数和65000万个神经元,5个卷积层,在一些卷积层后面还有池化层,3个全连接层,输出为 的softmax层。
二 数据集
实验采用的数据集是ImageNet。ImageNet是超过1500万个标记的高分辨率图像的数据集,大约有22,000个类别。这些图像是从网上收集的,并使用亚马逊的Mechanical Turk众包服务进行了标记。从2010年开始,举办ILSVRC比赛,数据使用的是ImageNet的 一个子集,每个类别大约有1000个图像,总共有1000个类别。总共有大约120万个训练图像,50000个验证图像,以及150000个测试图像。ImageNet比赛给出两个错误率,top-1和top-5,top-5错误率是指你的模型预测的概率最高的5个类别中都不包含正确的类别。ImageNet由可变分辨率的图像组成,而神经网络输入维度是固定的。 因此,我们将图像下采样到256×256的固定分辨率矩形图像,我们首先重新缩放图像,使短边长度为256,然后从结果图像中裁剪出中心256×256的图片。 我们没有预先处理图像以任何其他方式,我们在像素的原始RGB值上训练了我们的网络。
三 ReLU激活函数

四 局部归一化( Local Response Normalization)

其中aix,y表示第i个卷积在(x,y)产生的值然后应用ReLU激活函数的结果,n表示相邻的几个卷积核,N表示这一层总的卷积核数量。k,n,α,β都是超参数,他们的值是在验证集实验上得到的,k=2,n=5,α=1e-4,β=0.75.这种归一化操作实现了某种形式的横向抑制,这也是真实神经元的某种行为启发。这种具有对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得更大,而对响应比较小的值更加加以抑制,从而增强模型的泛化能力,这和让更加明显的特征更加明显,很细微不明显的特征加以抑制是一个道理。
后来证明该步骤起到的作用很小,所以后来就很少使用。
五 重叠poolin(overlap pooling)
六 网络结构
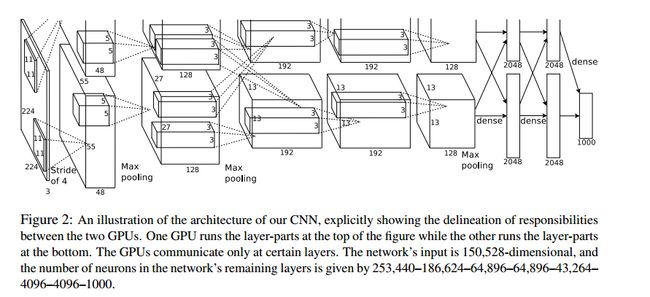
从图上可以明显看到网络结构分为上下两侧,这是因为网络分布在两个GPU上,这种药是因为NVIDIA GTX 580 GPU只用3GB内存,装不下那么大的网络。为了减少GPU之间的通信,第2,4,5个卷积层只连接同一个GPU上的上一层的kernel map(指和卷积核相乘后得到的矩阵)。第三个卷积层连接第二层的所有的kernel map。全连接的神经元连接到上一层的所有神经元。第1,2个卷积层里ReLU操作后轴LRN操作。第1,2,5卷积层卷积之后进行max pooling操作。ReLU激活函数应用于所有的卷积层和全连接层。
在AlexNet中,我们标记5个卷积层依次2为C1,C2,C3,C4,C5。而每次卷积后的结果在上图中可以看到,比如经过卷积层C1后,原始的图像变成了55x55的尺寸,一共有96个通道,分布在2张3G的显卡上,所以上图中一个立方体的尺寸是55x55x48,48是通道数目(后面会详细的说明),而在这个立方体里面还有一个5x5x48的小立方体,这个就是C2卷积层的核尺寸,48是核的厚度(后面会详细说明)。这样我们就能看到它每一层的卷积核尺寸以及每一层卷积之后的尺寸。我们按照上面的说明,推到下每一层的卷积操作:
需要说明的是,虽然AlexNet网络都用上图的结构来表示,但是其实输入图像的尺寸不是224x224x3,而应该是227x227x3,大家可以用244的尺寸推导下,会发现边界填充的结果是小数,这显然是不对的,在这里就不做推导了。
C1:96x11x11x3 (卷积核个数/高/宽/深度)
C2:256x5x5x48(卷积核个数/高/宽/深度)
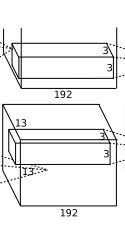
C3:384x3x3x256(卷积核个数/高/宽/深度)
C4:384x3x3x192(卷积核个数/高/宽/深度)
C5:256x3x3x192(卷积核个数/高/宽/深度)

更详细的结构如下:









- 采用的是1000个神经元,然后对FC7中4096个神经元进行全链接,然后会通过高斯过滤器,得到1000个float型的值,也就是我们所看到的预测的可能性,。
- 如果是训练模型的话,会通过标签label进行对比误差,然后求解出残差,再通过链式求导法则,将残差通过求解偏导数逐步向上传递,并将权重进行推倒更改,类似与BP网络思虑,然后会逐层逐层的调整权重以及偏置.
由于上面网络是分布在两个GPU上面,看起来有些凌乱,因此我们把AlexNet网络整合在一块,如下:

- AlexNet 首先用一张 227×227×3 的图片作为输入,实际上原文中使用的图像是 224×224×3,但是如果你尝试去推导一下,你会发现 227×227 这个尺寸更好一些。
- C1 第一层我们使用 96 个11×11 的过滤器,步幅为 4,由于步幅是 4,因此尺寸缩小到 55×55,缩小了 4 倍左右。然后用一个 3×3 的过滤器构建最大池化层,f=3,s=2,尺寸缩小为 27×27×96。
- C2 接着再执行一个 5×5 的same卷积, p=3,s=1,输出是 27×27×256。然后再次进行最大池化,尺寸缩小到 13×13。
- C3 再执行一次 same 卷积,p=1,s=1,得到的结果是 13×13×384, 384 个过滤器。
- C4 再做一次 same 卷积,p=1,s=1,得到的结果是 13×13×384, 384 个过滤器。
- C5 再做一次 same 卷积,p=1,s=1,得到的结果是 13×13×256。最后再进行一次最大池化,尺寸缩小到 6×6×256。
- 6×6×256 等于 9216,将其展开为 9216 个单元,然后是一些全连接层。最后使用 softmax 函数输出识别的结果。
七 防止过拟合
1.增加图片数据集(Data Augmentation)
- 对图片进行变化,例如裁切,缩放,翻转等。
- 在图片每个像素的RGB值上加入一个偏移量,使用主成分分析方法处理。将每个像素的RGB值x,y = [Ix,yR,Ix,yG,Ix,yB]加上下面的值:
![]()
其中pi和λi分别是RGB值3x3协方差矩阵的第i个特征向量和特征值。αi是一个服从均值0,标准差为0.1的高斯分布的随机变量,在训练一张图片之前生成,同一张图片训练多次会生成多次。这两个矩阵相乘,得到一个3x1的矩阵。
这种方法将top-1错误率减少了1%。
2.Dropout
dropout是以一定的概率使神经元的输出为0,AlexNet设置概率为0.5,这种技术打破了神经元之间固定的依赖,使得学习到的参数更加健壮。AlexNet在第1,2个全连接网络中使用了dropout,这使得迭代收敛的速度增加了一倍。
八 训练学习
该模型训练使用了随机梯度下降法,每批图片有180张,权重更新公式如下:

其中i是迭代的索引,v是动量,0.9是动量参数,ε是学习率,0.0005是权重衰减系数,在这里不仅起到正则化的作用,而且减少了模型的训练误差。 是这一批图片代价函数对权重w的偏导数。
是这一批图片代价函数对权重w的偏导数。
所有的权重都采用均值为0,方差为0.01的高斯分布进行初始化。第2,4,5卷积层和所有全连接层的偏置都初始化为1,其他层的偏置初始化为0.学习率ε=0.01,所有层都使用这个学习率,在训练过程中,当错误率不在下降时,将学习率除以10,在终止训练之前减少3次,我们把120万张图片训练了90遍,总过花费了5到6天。
参考文章
[1]从AlexNet理解卷积神经网络的一般结构
[2]AlexNet 网络详解及Tensorflow实现源码
[3]神经网络模型之AlexNet的一些总结
[4]lenet-5,Alexnet详解以及tensorflow代码实现
[5]【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络AlexNet(推荐)