课程首先从计算机的工作原理以及操作系统应该具备具备的核心功能开始讲起。
整个计算机是如何协作的
存储程序计算机以存储为核心,即无论是指令还是数据都存储到内存中,CPU通过地址找到相应的内存单元,取其中的指令或者读写其中的数据,数据的来源不仅仅是内存,也可以是外设。整体上计算机的各个部分的连接如图所示:

函数调用框架理解
其次为了理解函数调用堆栈框架,学习了一些汇编指令、寄存器以及寻址方式,寄存器最主要讲的三个是EIP.EBP与ESP分别用来指示即将要执行的指令的地址,一个栈的栈底与栈顶。
汇编主要讲的是常见的汇编指令,包括mov,push,pop,call,ret,sub等等。
具备了以上知识作为前提,深入的讲述了函数调用的堆栈框架。
首先是当我们使用call指令去调用一个函数的时候,我们首先会存储call之后的那条指令的地址到栈顶,以便于我们的被调用函数执行完毕后可以返回调用处后继续执行。其次是把调用函数的函数栈的ebp入栈,方便返回时恢复它的栈。然后就是为被调用函数分配栈空间:具体位置首先把ebp=esp,然后esp-x分配该函数的栈[由于运行时的栈的大小是可判断的,所以可以直接分配器大小。],然后分配的堆栈就用来存储局部变量。在退出函数时会有ret,它的动作与call的相反:先出栈返回地址,然后把它填充到EIP就返回到call指令之后了。

系统调用栈图
之后讲述了中断上下文与进程上下文:两者最主要的区别就是中断上下文发生在同一个进程中,即一个进程从用户态进入了内核态,并为之分配内核堆栈从而存储执行内核代码的局部变量;而进程上下文主要是发生在不同进程中,即从一个进程切换到另一个进程时,需要保存上一个进程的执行环境,尽管每个进程都有自己的堆栈段,但寄存器是共享的,所以需要保存,为了进程切换回来的时候恢复。[之前一直困扰的一个问题:中断的时候为什么不能切换进程?=》其实是因为中断上下文是保存在被中断进程的内核堆栈里,如果是从用户态到达内核态,用户态执行时的用户堆栈地址需要保存在该进程的内核堆栈中,如果在中断的时候发生了进程切换,那么在恢复时就找不到之前的那个进程,因为也就不能够获得那个进程的内核栈中的数据,会造成中断不能正常退出。]
以系统调用为例讲述了中断上下文[以fork与execve做了实验]:
整个系统调用的过程是:[以32位操作系统为例]首先在start_kernel的时候会初始化IDT表,并将IDT表初始化将该表的首地址填入IDTR寄存器中,当用户代码中有sys_call系统调用时,就会查找IDT表,根据IDT边首地址+8*128找到sys_call表项,表项中存储的有sys_call中断处理程序的地址,转去执行它,在sys_call中有类似于call sys_call_table(,eax,4)的一段代码用来根据系统调用号来找SCT表中的对应项[eax中存储系统调用号,在执行int0x80时存储],表项内容为对应的系统调用例程的地址,从而就去执行响应的系统调用了。可以结合下图理解。
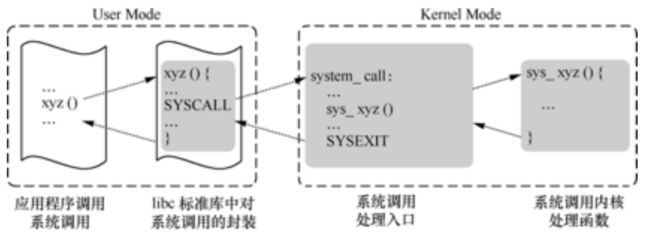
fork与execve是两个比较特殊的系统调用:
fork有"两个返回值"其实只是一个形象的说法,其实背后的原因是fork产生的子进程完全是按照父进程复制而来,所以堆栈都是一样的,那么其中断后的retaddress也一定是一样的,父进程从fork()后指令返回一次,返回一个pid,自进程返回一次,所以就造成了有两个返回值的假像。
execve的特殊之处在于他的返回地址,当我们刚执行execve系统调用的时候,会有个返回地址在栈中即execve()之后的那条指令,但是当我们执行execve的时候,内核就会更新他的可执行程序,从而返回地址就不是之前的那个了,而是execve参数中所要执行的代码。且execve经常与fork一起使用。=>可执行程序的加载就是通过它来完成的。
通用进程概述以及linux中的进程的实现
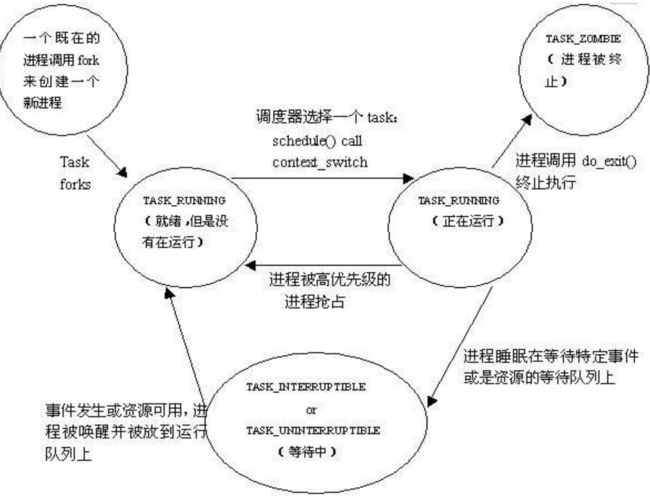
首先是讲述操作系统中描述的进程的几个部分:即进程描述符[PCB],进程的状态以及状态之间的转换,进程的调度策略,进程的切换[即进程上下文的保存]。
之后对linux的进程实现做了详细的描述:
PCB的实现为task_struct:[和进程的内核栈在一起放着的,一共占8KB]
主要包括:进程标识、 进程状态(State)、 进程调度信息和策略、进程通信有关的信息(IPC)、进程链接信息(Links)、 时间和定时器信息(Times and Timers)、文件系统信息(Files System) 、处理器相关的上下文信息。
进程表示即为pid。
linux的进程状态的转换如下图所示:[需要注意的就绪态与运行态均用TASK_RUNNING表示,区别即在于占了CPU没]
进程的链接信息:
除了把所有的进程组成一个链之外,还有其他的链,例如可执行队列也组成一个了方便在调度时直接遍历该链调度。
linux的进程调度策略:
总的来说,linux进程的调度策略是根据优先级来的,不同类型的进程采取不同的调度策略。
普通进程按照SCHED_OTHER调度策略进行进程调度。 实时进程按照SCHED_FIFO或SCHED_RR策略进行调度。 SCHED_FIFO是按先进先出方法选择下一个使用CPU的进程。 SCHED_RR是实时进程的时间片轮转法策略(Round Robin)。
之后由分别从硬件级别与软件级别对中断与异常做了描述:
软件级别上边已经描述过了过程,从硬件级别来讲有外部中断与内部中断,以外部中断为例:所有的外设都通过IRQ连接在一个中断控制器上,当外设到来的数据需要cpu读取的时候,中断控制器便会向cpu 的中断引脚[INTR]发送有中断到来,通知cpu来中断控制器的寄存器中读取。CPU读取到该中断号之后便会执行执行中断服务程序来完成对应的中断。[中断处理程序:目的是执行中断找到中断向量,为中断服务历程提供运行环境(比如保存中断前的各工作寄存器状态,屏蔽中断,中断嵌套计数,或者取消屏蔽)等等,搞定后跳转到中断向量指向的位置,执行中断服务例程[真正的服务,读取IO设备的数据等]。]
linux驱动程序基础
驱动程序作为软件与硬件的桥梁程序,替我们管理着硬件的读与写[Linux将硬件设备看作一个特殊的文件来操作, 该文件被称为设备文件;系统通过对设备文件 的读写等操作,实现对外设的读写等操作],又同时为文件系统提供了方便的接口,来实现对硬件读写。由于外设多,一般通过insmod与rmmod来动态的加载与删除驱动程序。即我们通过编写LKM来动态的加载驱动程序到内核中去.
驱动程序通过中断来通知CPU有中断来了,但是中断又要求快速响应[设想如果一个设备中的数据长时间没被读那么又来了新数据就会被覆盖从而丢失数据],所以加入了中断延迟机制:通过Tasklet或者工作队列来实现。
以read系统调用为例说明驱动程序的作用:用户程序执行一个read(),然后到内核态调用sys_read(),然后判断该设备文件的类型[块设备/字符设备等]调用使用insmod注册的设备驱动程序的对应的read进行读取硬件中的数据并写入到设备文件中去。
linux文件系统
linux有一个非常出名的哲学:一切皆文件,即不管是网络连接,外部设备,又或者是真正的文件,linuxOS都把他当做一个文件来操作。一切皆文件是如何实现的呢?通过VFS,VFS定义抽象的接口[即所有的文件都要实现的函数]以及一些数据结构,向下交所有对文件的操作定向到相应的特定文件系统函数上去。对上提供统一的接口,即read,write,open等一套函数来统一使用各种文件,外设,网络连接等。
整个具体是怎么实现的?
以read()函数为例:首先read调用sys_read的过程前边有说过,就不赘述了,sys_read是如何根据特定的文件类型实现读呢?它是根据read传入的fd,在进程文件打开表中找到fd[]数组,该数组中存储的是指向系统打开文件表中的一个file结构,在file结构中又有file_op结构,当中定义了该类文件的文件系统的读写函数,从而对具体的文件系统进行读写。
总结:
通过这个课程的学习,还是收获颇丰的。之前只有对操作系统原理的学习,对具体的实现并未涉及过,通过学习linuxOS,对原理部分有了更深刻的理解,而且也看到了部分原理与实现的冲突;其次就是对linux的一切皆文件的实现原理有了一定的理解,一切皆文件这种架构其实和我们许多中间件的设计思想颇为相似,对下层提供统一接口让其实现,对上层简化操作。最后,感谢两位老师的付出。