Unet——用于图像边缘检测,是FCN的改进
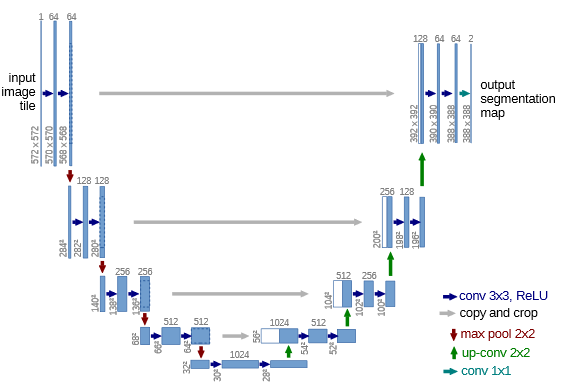
如上图是UNET的架构图,可以发现器输入图像和输出图像不一致,如果我们需要输入图像和输出图像一致时,在卷积时,使用padding=“SAME”即可,然后再边缘检测时,就相当与像素级别的二分类问题,用交叉熵做loss函数即可。但位置检测常用IOU作为loss函数。
个人觉得UNET的优点:
1.Unet的去除了全链接层,可以接受图像大小不一致的输入(在训练时,同一个批图像大小可以不一致吗?)
2.Unet的最重要的是,他还保留了位置信息,讲低级特征图和编码部分对应连接,保留位置信息,所以可以用于图像生成、图像的语义分割和GAN相结合等等,和胶囊网络的比较?
3.U-Net: Convolutional Networks for Biomedical Image Segmentation,是边缘检测的论文,边缘检测这类问题,标签数据是非常少且昂贵的,而要训练deep network需要很多数据,所以应该应用用了图像镜像,图像扭曲,仿射变换等图像增强技术。
tensorflow的实现


#coding:utf-8 import tensorflow as tf import argparse import Augmentor import os import glob from PIL import Image import numpy as np from data import * parser = argparse.ArgumentParser() parser.add_argument('--image_size', type=int, default=512) parser.add_argument('--batch_size', type=int, default=2) parser.add_argument('--n_epoch', type=int, default=2000) param = parser.parse_args() def conv_pool(input,filters_1,filters_2,kernel_size,name = 'conv2d'): with tf.variable_scope(name): conv_1 = tf.layers.conv2d(inputs=input,filters= filters_1,kernel_size=kernel_size,padding="same", activation=tf.nn.relu,kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),name = "conv_1") conv_2 = tf.layers.conv2d(inputs=conv_1,filters= filters_2,kernel_size=kernel_size,padding="same", activation=tf.nn.relu,kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),name = "conv_2") pool = tf.layers.max_pooling2d(inputs = conv_2,pool_size = [2,2],strides = 2,padding = "same",name = 'pool') return conv_2,pool def upconv_concat(inputA,inputB,filters,kernel_size,name="upconv"): with tf.variable_scope(name): up_conv = tf.layers.conv2d_transpose(inputs = inputA,filters = filters,kernel_size = kernel_size,strides = (2,2),padding ="same", activation=tf.nn.relu,kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),name = 'up_conv') return tf.concat([up_conv, inputB], axis=-1, name="concat") class U_net(object): def __init__(self): self.name = "U_NET" def __call__(self,x,reuse = False): with tf.variable_scope(self.name) as scope: if reuse: scope.reuse_variables() conv_1,pool_1 = conv_pool(x,64,64,[3,3],name="conv_pool_1") conv_2,pool_2 = conv_pool(pool_1,128,128,[3,3],name="conv_pool_2") conv_3,pool_3 = conv_pool(pool_2,256,256,[3,3],name="conv_pool_3") conv_4,pool_4 = conv_pool(pool_3,512,512,[3,3],name="conv_pool_4") conv_5,pool_5 = conv_pool(pool_4,1024,1024,[3,3],name="conv_pool_5") upconv_6 = upconv_concat(conv_5,conv_4,512,[2,2],name="upconv_6") conv_6,pool_6 = conv_pool(upconv_6,512,512,[3,3],name="conv_pool_6") upconv_7 = upconv_concat(conv_6,conv_3,256,[2,2],name="upconv_7") conv_7,pool_7 = conv_pool(upconv_7,256,256,[3,3],name="conv_pool_7") upconv_8 = upconv_concat(conv_7,conv_2,128,[2,2],name="upconv_8") conv_8,pool_8 = conv_pool(upconv_8,128,128,[3,3],name="conv_pool_8") upconv_9 = upconv_concat(conv_8,conv_1,64,[2,2],name="upconv_9") conv_9,pool_9 = conv_pool(upconv_9,64,64,[3,3],name="conv_pool_9") conv_10 = tf.layers.conv2d(inputs=conv_9,filters= 2,kernel_size=[3,3],padding="same", activation=tf.nn.relu,kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),name = "conv_10") output_image = tf.layers.conv2d(inputs=conv_10,filters= 1,kernel_size=[1,1],padding="same", activation=tf.nn.sigmoid,kernel_initializer=tf.contrib.layers.variance_scaling_initializer(),name = "output_image") return output_image @property def vars(self): return tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.name) class U_net_train(object): def __init__(self,unet,data,name = "unet_train"): self.name = name self.unet = unet self.imagesize = param.image_size self.train_data = tf.placeholder(tf.float32, shape=[None, self.imagesize, self.imagesize, 1], name = "train_data") tf.summary.image("train_image",self.train_data,2) self.train_label = tf.placeholder(tf.float32, shape=[None, self.imagesize, self.imagesize, 1], name = "train_label") tf.summary.image("train_label",self.train_label,2) self.data = data self.predict_label = self.unet(self.train_data) tf.summary.image("output_image",self.predict_label,2) with tf.name_scope('loss'): self.loss = - tf.reduce_mean(self.train_label * tf.log(self.predict_label + 1e-8) + (1-self.train_label) * tf.log(1 - self.predict_label + 1e-8 )) tf.summary.scalar('loss',self.loss) #self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels = self.train_label,logits = self.predict_label,name = 'loss')) with tf.name_scope("train"): self.optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(self.loss) self.saver = tf.train.Saver() gpu_options = tf.GPUOptions(allow_growth = True) with tf.name_scope('init_sessoin'): self.sess = tf.InteractiveSession(config=tf.ConfigProto(gpu_options=gpu_options)) #self.sess = tf.Session() self.merged = tf.summary.merge_all() def train(self, sample_dir, restore = False,ckpt_dir='ckpt'): if restore: print("hhhh") self.saver.restore(self.sess,"ckpt/unet.ckpt") self.sess.run(tf.global_variables_initializer()) writer = tf.summary.FileWriter("./logs_1/", self.sess.graph) for epoch in range(param.n_epoch): images, labels = self.data(param.batch_size) loss,_,rs = self.sess.run([self.loss,self.optimizer,self.merged],feed_dict={self.train_data: images, self.train_label: labels}) writer.add_summary(rs, epoch) if epoch % 50 == 1: print('Iter: {}; loss: {:.10}'.format(epoch, loss)) if (epoch + 21) % 100 == 1: self.saver.save(self.sess, os.path.join(ckpt_dir, "unet.ckpt")) self.test() self.saver.save(self.sess, os.path.join(ckpt_dir, "unet.ckpt")) def test(self): #test_image = glob.glob("./data/test/*.tif") test_images = np.zeros((1,512,512,1)) for i in range(1): test_images[i,:,:,:] = np.array(Image.open("./data/test/"+str(i)+".tif")).reshape(512,512,1)/255. #saver = tf.train.Saver() #gpu_options = tf.GPUOptions(allow_growth=True) #self.sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) self.saver.restore(self.sess,"ckpt/unet.ckpt") #test_labels = self.unet(test_images,reuse = True) test_labels = self.sess.run(self.predict_label,feed_dict={self.train_data: test_images}) for i in range(1): image = test_labels[i,:,:,:] * 255. testimage = image.reshape((512,512)) testimage =testimage.astype(np.uint8) im = Image.fromarray(testimage) im.save("./data/test/label"+str(i)+".tif") if __name__ == '__main__': # constraint GPU #os.environ['CUDA_VISIBLE_DEVICES'] = '0' unet = U_net() data = DATA() u_train = U_net_train(unet,data) u_train.train("./data/model/",restore=False) u_train.test()
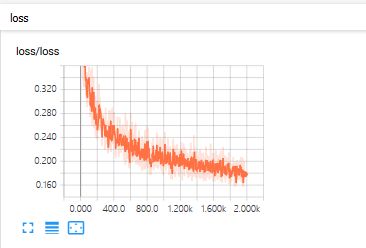
效果图
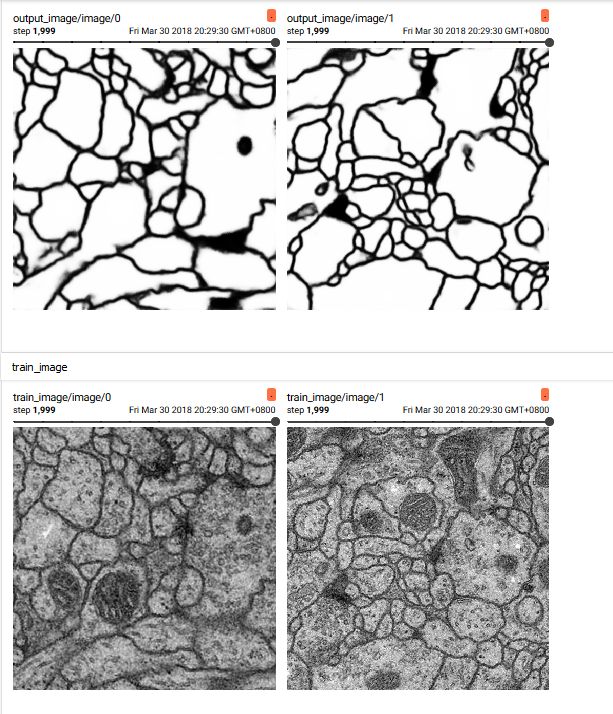
踩过的坑,原论文中网络之后一层变成2个通道的没加,直接加上了输出通道效果一直不好,个人以为可能特征太多,没有转化为高级特征,所以造成不收敛效果不好的问题。
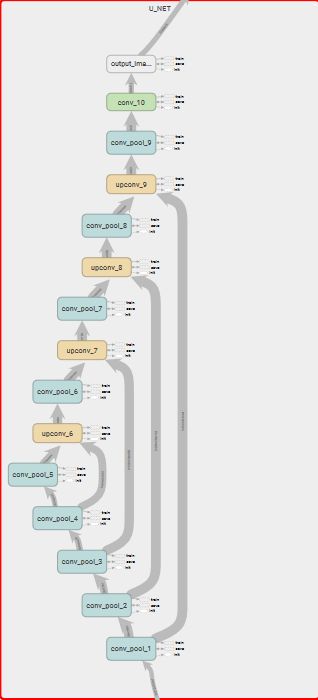
因tensorboard的图太大,这里就截个一个tensorboard的局部图: