因为笔者在线上实习时的需求,需要做一个裁判文书网的爬虫,本以为,一个政府网站爬虫嘛会有多难?但当笔者开始爬的时候,笔者发现自己错了,困难重重!好在最后解决了,笔者将代码重构放在github上之后在这里写下了写这个爬虫的整个思路。
笔者实现的爬虫地址:https://github.com/cuijinyu/lawBug
原理分析
获取列表
首先,打开裁判文书网的页面,进入我们眼帘的是这样的画面
一个大大的搜索框,我们的思路大致也从这里开始。
我们打开开发者工具,进行一次搜索,看看都会发生哪些事情。
我们在这里搜索买票

然后我们点击搜索,看看开发者工具里所抓到的包
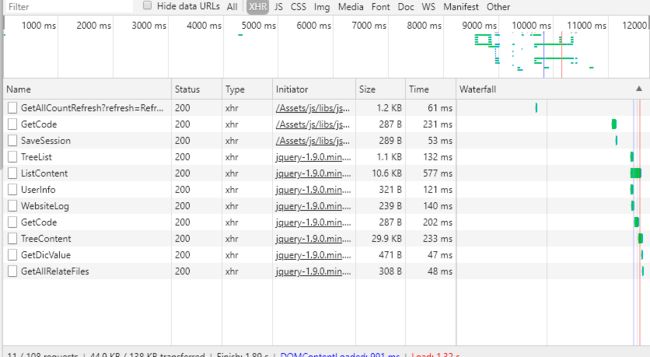
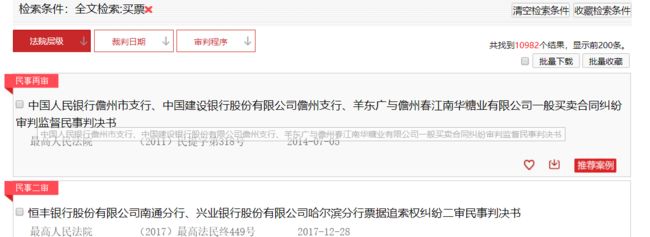
我们看到,整个搜索,经过了GetCode 、TreeList、 ListContent这三个关键的请求,我们分别对这三个请求进行分析看看。

![]()

首先是GetCode,我们可以看到浏览器向http://wenshu.court.gov.cn/ValiCode/GetCode这个地址发送了一个Post请求,发送了一个含有guid项的表单过去,那么这个guid是什么呢?我们暂时先不表。
另外这个请求还为我们反回了一串字符,这个字符串是什么?很奇怪不是吗,但是既然我们发送了这个请求,那么这个应该是有用的,我们之后看。




再看看ListContent这个请求,浏览器向http://wenshu.court.gov.cn/List/ListContent发送了一个post请求,post过去的表单里包含param 、 index 、 direction、vl5x、number、guid、order这几项。似乎,这个和我们的搜索有什么联系,我们再看看返回的数据,是一串非常非常非常长的JSON,我截取了其中的开头和结尾,在开头处我们可以看到RunEval这一项,奇奇怪怪的,我们再看结尾处,嘶,似乎,这就是我们所要找的数据了。我们先不管,我们先看看TreeList请求。



我们同样是发送了Post请求,我们看得到的结果,似乎是 网站中关键词的列表,这并不是我们所要的数据。
既然知道了整个搜索请求的流程和我们所需要的一些数据值,那么接下来我们分析一下这些值究竟来源于哪里。
首先是getCode里的guid值,这个guid值在之后的请求中也有用到。
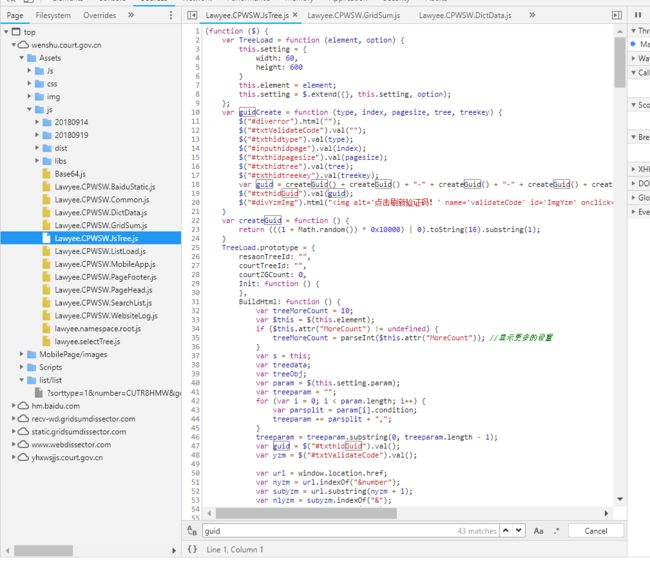
我们在源码中进行搜索,在其中lsTree这个文件中找到了如下定义,guid是由一个名为createGuid的函数拼接生成的,这个函数的功能就是用来生成随机字符串的。
var createGuid = function () {
return (((1 + Math.random()) * 0x10000) | 0).toString(16).substring(1);
}我们找到了guid的生成办法
var guid = createGuid() + createGuid() + "-" + createGuid() + "-" + createGuid() + createGuid() + "-" + createGuid() + createGuid() + createGuid(); //CreateGuid();
好了,这下找到了guid的生成方案,对于Node来说,我们只需要直接拿来使用就好啦。
找到了guid,我们接下来看number的生成办法
可以翻看一下GetCode请求,所拿到的一串字符串的前四位正是我们进行ListContent请求时的前四位(配图中的图片是刷新之后的,第一次请求中会进行ListContent请求)。
所以我们想要拿到number的话,需要对服务器发起GetCode请求,将我们的guid发给服务器。我们就可以从中取得我们所需要的number。
继续向下看,我们发现一个奇奇怪怪的值vl5x,那么这个值又是从哪里来的呢?
我们用同样的搜索源码的办法,来找找看有没有相关的源码。

我们在源码中看到了这样一段,在发送ajax请求时,调用了getKey()这个函数。
我们通过找找看getKey的源码。我们通过控制台提供给我们的源码查看的办法找到了它的源码。
并且这段代码是依赖于一个叫做vjkl5的值,我们通过分析发现这个vjkl5来自于cookie
function getKey() {
eval(de("eval(_fxxx('e n(7){9 d=0;j(9 i=0;i<7.k;i++){d+=(7.g(i)<<(i%m))}f d}e p(7){9 d=0;j(9 i=0;i<7.k;i++){d+=(7.g(i)<<(i%m))+i}f d}e E(7,o){9 d=0;j(9 i=0;i<7.k;i++){d+=(7.g(i)<<(i%m))+(i*o)}f d}e x(7,o){9 d=0;j(9 i=0;i<7.k;i++){d+=(7.g(i)<<(i%m))+(i+o-7.g(i))}f d}e z(7){9 7=7.8(5,5*5)+7.8((5+1)*(5+1),3);9 a=7.8(5)+7.8(-4);9 b=7.8(4)+a.8(-6);f h(7).8(4,l)}e w(7){9 7=7.8(5,5*5)+\"5\"+7.8(1,2)+\"1\"+7.8((5+1)*(5+1),3);9 a=7.8(5)+7.8(4);9 b=7.8(t)+a.8(-6);9 c=7.8(4)+a.8(6);f h(c).8(4,l)}e A(7){9 7=7.8(5,5*5)+\"r\"+7.8(1,2)+7.8((5+1)*(5+1),3);9 a=n(7.8(5))+7.8(4);9 b=n(7.8(5))+7.8(4);9 c=7.8(4)+b.8(5);f h(c).8(1,l)}e y(7){9 7=7.8(5,5*5)+\"r\"+7.8(1,2)+7.8((5+1)*(5+1),3);9 a=p(7.8(5))+7.8(4);9 b=7.8(4)+a.8(5);9 c=n(7.8(5))+7.8(4);f h(b).8(3,l)}e B(7){9 7=7.8(5,5*5)+\"2\"+7.8(1,2)+7.8((5+1)*(5+1),3);9 d=0;j(9 i=0;i<7.8(1).k;i++){d+=(7.g(i)<<(i%m))}9 s=d+7.8(4);9 d=0;9 a=7.8(5);j(9 i=0;i我们通过对这段源码打断点可知,这段源码实际依赖于
var _fxxx = function (p, a, c, k, e, d) { e = function (c) { return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36)) }; if (!''.replace(/^/, String)) { while (c--) d[e(c)] = k[c] || e(c); k = [function (e) { return d[e] } ]; e = function () { return '\\w+' }; c = 1; }; while (c--) if (k[c]) p = p.replace(new RegExp('\\b' + e(c) + '\\b', 'g'), k[c]); return p; };
function de(str, count, strReplace) {
var arrReplace = strReplace.split('|');
for (var i = 0; i < count; i++) {
str = str.replace(new RegExp('\\{' + i + '\\}', 'g'), arrReplace[i]);
}
return str;
} 通过对代码的分析,我们可以得知这些代码依赖于base64.js md5.js sha1.js 方便起见,我们可以直接将它的源码下载下来直接使用。
我们继续分析剩下的值,param很明显是搜索参数,并且以,隔开,Index为页码,Order为排序方式,我们按照默认法院层级,Direction暂时不知为何用,我们按照默认asc,这下我们就知道所有的参数来源了。
至此,我们就可以构造请求去获取列表了。
全文内容获取
接下来到了另外一个坑非常多的地方:获取全文内容。
在获取到列表后,我们发现一件事情,列表的内容只是缩略,很可能不能满足我们的需求,所以,我们就必须要想办法去获取到全文,那么我们该怎么办呢?
我们先打开一个详情页,看看它都做了什么事情。
我们首先看URL,详情页的URL的一个例子在这里
http://wenshu.court.gov.cn/content/content?DocID=4964b551-5353-48a0-ac37-30f0d7f981c5&KeyWord=%E4%B9%B0%E7%A5%A8
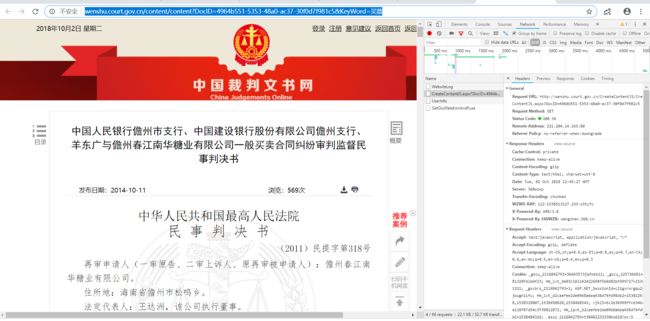
分析其格式,大致为
http://wenshu.court.gov.cn/content/content?DocID= 加上DocID再看请求
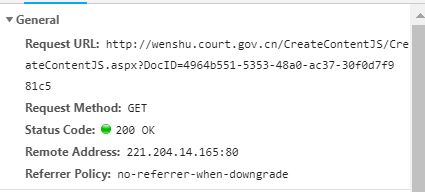

发现这样一个请求
它的返回结果正是文章的内容(需要正则表达式提取)
我们在列表页加载完后我们去用选中打开详情页的链接

发现其调用了一个名为Navi的函数,好吧,我们再来看看Navi函数是个什么鬼东西
同样的办法,我们拿到了Navi的函数本体
哈哈,还有这道反爬虫程序作者留下的注释~
//增加7道爬虫防御 段智峰 20180807
function Navi(id, keyword) {
var unzipid = unzip(id);
try {
var realid = com.str.Decrypt(unzipid);
if (realid == "") {
setTimeout("Navi('" + id + "','" + keyword + "')", 1000);
} else {
var url = "/content/content?DocID=" + realid + "&KeyWord=" + encodeURI(keyword);
openWin(url);
}
} catch (ex) {
setTimeout("Navi('" + id + "','" + keyword + "')", 1000);
}
}分析得知,Navi函数先将id解码,之后进行解密得到
我们看看unzip函数是什么
function unzip(b64Data) {
var strData ;
if(!window.atob){
// strData = $.base64.atob(b64Data)
}else{
// strData = atob(b64Data)
}
var charData ;
if (!Array.prototype.map) {
// charData =iemap( strData.split(''),function (x) { return x.charCodeAt(0); },null);
}else{
// charData = strData.split('').map(function (x) { return x.charCodeAt(0); });
}
strData = Base64_Zip.btou(RawDeflate.inflate(Base64_Zip.fromBase64(b64Data)));
// var binData = new Uint8Array(charData);
// var data = pako.inflate(binData);
// strData = String.fromCharCode.apply(null, new Uint16Array(data));
return strData;
}对字符串进行了base64解码,在之前我们请求拿到的数据中有文书的ID,我们要做的就是把ID先进行Base64解码,之后再进行解密,我们接着往下看,可以在同一个文件里发现解密所需要的函数。
var com = {};
com.str = {
_KEY: "12345678900000001234567890000000",//32λ
_IV: "abcd134556abcedf",//16λ
/**************************************************************
*�ַ�������
* str����Ҫ���ܵ��ַ���
****************************************************************/
Encrypt: function (str) {
var key = CryptoJS.enc.Utf8.parse(this._KEY);
var iv = CryptoJS.enc.Utf8.parse(this._IV);
var encrypted = '';
var srcs = CryptoJS.enc.Utf8.parse(str);
encrypted = CryptoJS.AES.encrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.ciphertext.toString();
},
/**************************************************************
*�ַ�������
* str����Ҫ���ܵ��ַ���
****************************************************************/
Decrypt: function (str) {
var result = com.str.DecryptInner(str);
try {
var newstr = com.str.DecryptInner(result);
if(newstr!=""){
result = newstr;
}
} catch (ex) {
var msg = ex;
}
return result;
},
DecryptInner: function (str) {
var key = CryptoJS.enc.Utf8.parse(this._KEY);
var iv = CryptoJS.enc.Utf8.parse(this._IV);
var encryptedHexStr = CryptoJS.enc.Hex.parse(str);
var srcs = CryptoJS.enc.Base64.stringify(encryptedHexStr);
var decrypt = CryptoJS.AES.decrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
var decryptedStr = decrypt.toString(CryptoJS.enc.Utf8);
var result = decryptedStr.toString();
try {
result = Decrypt(result);
} catch (ex) {
var msg = ex;
}
return result;
}
}
function iemap(myarray ,callback, thisArg) {
var T, A, k;
if (myarray == null) {
throw new TypeError(" this is null or not defined");
}
var O = Object(myarray);
var len = O.length >>> 0;
if (typeof callback !== "function") {
throw new TypeError(callback + " is not a function");
}
// 5. If thisArg was supplied, let T be thisArg; else let T be undefined.
if (thisArg) {
T = thisArg;
}
A = new Array(len);
k = 0;
while(k < len) {
var kValue, mappedValue;
if (k in O) {
kValue = O[ k ];
mappedValue = callback.call(T, kValue, k, O);
A[ k ] = mappedValue;
}
k++;
}
return A;
}; 分析可得,在对字符串进行Base64解码之后,我们还需要对这个字符串进行两次AES解密就可以得到docID
但是
到这里还没有完,在经过尝试之后,笔者发现此处的iv向量不会发生变化,但是,进行AES解密的key会发生改变,这个key是哪里来呢?
经过一步一步打断点测试可得,
我们在第一次进行请求列表时,得到的RunEval值需要被我们进行Base64解码后执行,这段源码会改变Key的值,让我们可以正确的解析。
笔者在解码后发现,神奇的Fuckjs在此处现身了

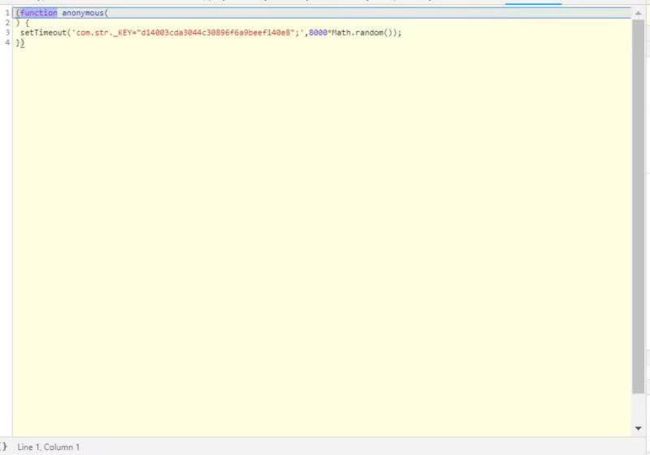
到这里,我们就基本解决了整个分析破解过程。
但是当笔者在用Node去实现整个解密过程时,遇到了更多的坑,包括Node运行时与浏览器运行时的差异。
文书网潜在的坑和解决方案
坑:
- 每种搜索条件下,给出的只有两百条数据,之后的页面以200条中最后的数据填充
- 请求列表时,有时候会出现remind key
解决方案:
- 采用多种请求模式,笔者爬取了全国几乎所有的中级以上人民法院名单列表,分别加在参数末尾进行请求,按照每种条件最多200条,可以获得最多200*3500=700000数据,足够大部分情况使用。另外的一种方案是按照时间,时间可以出现更多种组合,适合百万以上的数据量。
- 出现remind key时重新获取参数,再次请求。
Node爬虫实现时的坑
- Node中没有全局对象是global,而浏览器是window,在改写时,需要替换window为global
- 文书网上AES解密用的源码直接移植在Node时会出现奇怪的问题,笔者用Crypto模块进行了重写
- Node中的setTimeout和浏览器中setTimeout表现不一致,浏览器中支持运行字符串参数,但是Node中只支持函数,在fuckjs被解析后得到的结果即为字符串。
- 笔者对于setTimeout问题的解决方案是覆盖了setTimeout,直接解析执行了setTimeout,但是带来的问题是,让Node实现sleep函数与定时变得非常困难。
畅想
笔者在此次重构中并没有实现存储过程与解析文章具体内容过程,并且覆盖setTimeout的方法不见得多么优雅,非常希望能够得到大家的指正。
笔者实现的爬虫地址:https://github.com/cuijinyu/lawBug
欢迎大家提出issue和提pr~~~
给个star吧~