爬取目标:https://maoyan.com/board/4?offset=0
一、爬取首页
1 def get_one_page(url): 2 headers = { 3 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36' 4 } #添加user—agent(浏览器信息) 5 response = requests.get(url,headers=headers) #爬取指定的URL源码 6 if response.status_code == 200: #如果访问正常,返回网站源码 7 return response.text 8 return None
二、正则提取
正则提取首先要分析网站源代码

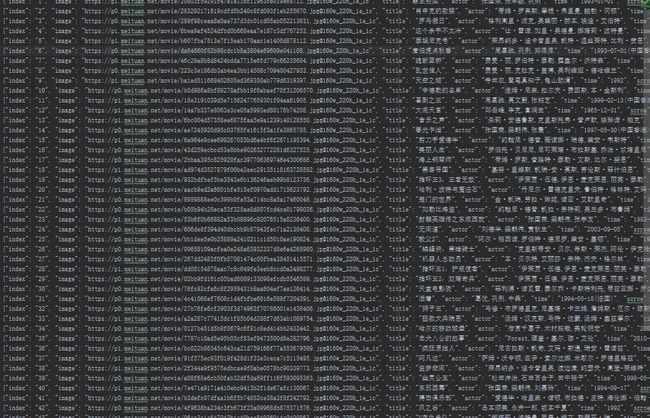
需要提取的信息有:排名,图片地址,片名,主演,上映日期和评分
从代码中可以看出,每个影片信息存放在一个
标签中正则匹配时必须加上class名(class名唯一),非必要内容可用非贪婪匹配.*?,提取内容必须用(.*?)放在括号里,方便后面提取
正则表达式如下:
使用compile方法将正则表达式变成正则对象
1 def parse_one_page(html): 2 pattern = re.compile( 3 '.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',re.S 4 ) 5 items = re.findall(pattern,html) 6 # print(items) 7 for item in items: #使显示结果清楚明了 8 yield{ 9 'index':item[0], 10 'image':item[1], 11 'title':item[2].strip(), 12 'actor':item[3].strip()[3:], 13 'time':item[4].strip()[5:], 14 'scroe':item[5].strip()+item[6].strip() 15 }
三、写入文件
使用json库中的dumps()方法实现字典的序列化
1 def write_to_file(content): 2 with open('result.txt','a',encoding='utf-8') as f: 3 print(type(json.dumps(content))) 4 f.write(json.dumps(content,ensure_ascii=False)+'\n') #ensure_ascii设为False,保证输入内容是中文字符而不是Unicode编码
四、整合代码
使用main()方法来实现前面实现的方法
1 def main(): 2 url = 'https://maoyan.com/board/4?offset=' 3 html = get_one_page(url) #爬取首页 4 for item in parse_one_page(html): #解析首页,正则提取 5 write_to_file(item) #写入文件
五、分页爬取
每页的网址:'https://maoyan.com/board/4?offset=' + str(offset),等号后面为n * 10,n为整数,为零是第一页,为10时,第二页,以此类推
完整代码如下:
1 import requests 2 import re 3 import json 4 import time 5 from requests.exceptions import RequestException 6 7 def get_one_page(url): 8 try: 9 headers = { 10 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36' 11 } 12 response = requests.get(url,headers=headers) 13 if response.status_code == 200: 14 return response.text 15 return None 16 except RequestException: 17 return None 18 19 def parse_one_page(html): 20 pattern = re.compile( 21 '.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',re.S 22 ) 23 items = re.findall(pattern,html) 24 # print(items) 25 for item in items: 26 yield{ 27 'index':item[0], 28 'image':item[1], 29 'title':item[2].strip(), 30 'actor':item[3].strip()[3:], 31 'time':item[4].strip()[5:], 32 'scroe':item[5].strip()+item[6].strip() 33 } 34 35 def write_to_file(content): 36 with open('result.txt','a',encoding='utf-8') as f: 37 print(type(json.dumps(content))) 38 f.write(json.dumps(content,ensure_ascii=False)+'\n') 39 40 def main(offset): 41 url = 'https://maoyan.com/board/4?offset=' + str(offset) 42 html = get_one_page(url) 43 for item in parse_one_page(html): 44 write_to_file(item) 45 46 if __name__ == '__main__': 47 for i in range(10): 48 main(offset=i * 10) 49 time.sleep(1)
六、爬取结果