泛型是 JDK1.5 的一个新特性,其实就是一个『语法糖』,本质上就是编译器为了提供更好的可读性而提供的一种小「手段」,虚拟机层面是不存在所谓『泛型』的概念的。
在我看来,『泛型』的存在具有以下两点意义,这也是它被设计出来的初衷。
一是,通过泛型的语法定义,编译器可以在编译期提供一定的类型安全检查,过滤掉大部分因为类型不符而导致的运行时异常,例如:
ArrayList list = new ArrayList<>();
list.add("ddddd"); //编译失败 由于我们的 ArrayList 是符合泛型语法定义的容器,所以你可以在实例化的时候指定一个类型,限定该容器只能容纳 Integer 类型的元素。而如果你强行添加其他类型的元素进入,那么编译器是不会通过的。
二是,泛型可以让程序代码的可读性更高,并且由于本身只是一个语法糖,所以对于 JVM 运行时的性能是没有任何影响的。
当然,『泛型』也有它与身俱来的一些缺点,虽然看起来好像只是提供了一种类型安全检查的功能,但是实际上这种语法糖的实现却没有看起来的那样轻松,理解好泛型的基本原理将有助于你理解各类容器集合框架。
类型擦除
『类型擦除』的概念放在最开始进行介绍是为了方便大家初步建立起对于『泛型』的一个基本认识,从而对于后续介绍的使用方式上会更容易理解。
泛型这种语法糖,编译器会在编译期间「擦除」泛型语法并相应的做出一些类型转换动作。例如:
public class Caculate {
private T num;
} 我们定义了一个泛型类,具体定义泛型类的细节待会会进行详细介绍,这里关注我们的类型擦除过程。定义了一个属性成员,该成员的类型是一个泛型类型,这个 T 具体是什么类型,我们也不知道,它只是用于限定类型的。
当然,我们也可以反编译一下这个 Caculate 类:
public class Caculate{
public Caculate(){}
private Object num;
}会得到这样一个结果,很明显的是,编译器擦除 Caculate 类后面的两个尖括号,并且将 num 的类型定义为 Object 类型。
当然,有人可能就会问了,「是不是所有的泛型类型都以 Object 进行擦除呢?」
答案是:大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。
public class Caculate {
private T num;
} 这种情况的泛型类型,num 会被替换为 String 而不再是 Object。
这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类,也就是你构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类,所以无论你限定 T 为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
那么很多人也会有这样的疑问,你类型擦除之后,所有泛型相关方法的返回值都是 Object,那我当初泛型限定的具体类型还有用吗?例如这样一个方法:
ArrayList list = new ArrayList();
list.add(10);
Integer num = list.get(0); //这是 ArrayList 内部的一个方法
public E get(int index) {
.....
}就是说,你类型擦除之后,方法 get 的返回值 E 会被擦除为 Object 类型,那么为什么我们看到的确实返回的 Integer 类型呢?
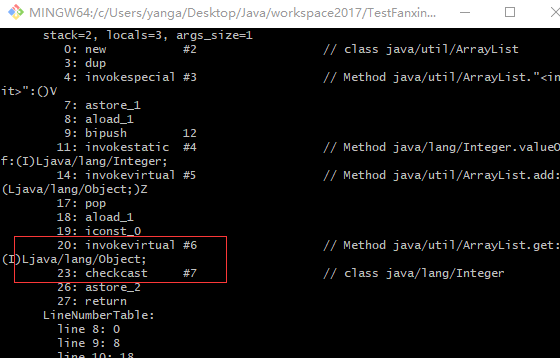
这是上述三行代码的一个反编译结果,可以看到,实际上编译器会正常的将 ArrayList 编译并进行类型擦除,然后返回实例。但是除此之外的是,如果构建 ArrayList 实例时使用了泛型语法,那么编译器将标记该实例并关注该实例后续所有方法的调用,每次调用前都进行安全检查,非指定类型的方法都不能调用成功。
其实还有一点可能大家都很少关注,大多数人只是知道编译器会类型擦除一个泛型类并对创建出来的实例进行一定的安全检查。但是实际上编译器不仅关注一个泛型方法的调用,它还会为某些返回值为限定的泛型类型的方法进行强制类型转换,由于类型擦除,返回值为泛型类型的方法都会擦除成 Object 类型,当这些方法被调用后,编译器会额外插入一行 checkcast 指令用于强制类型转换。
其实这一个过程,我们管它叫做『泛型翻译』。不得不感叹一下,编译器为了蒙骗虚拟机对程序员提供泛型服务可是没少费心思啊。
泛型的基本使用
泛型类与接口
定义一个泛型类或接口是容易的,我们看几个 JDK 中的泛型类。
- public class ArrayList
- public interface List
- public interface Queue
基本格式是这样的:
访问修饰符 class/interface 类名或接口名<限定类型变量名>其中「限定类型变量名」可以是任意一个变量名称,你叫它 T 也好,E 也好,只要符合 Java 变量命名规范就可以。在这里相当于声明了一个泛型限定类型,该类中的成员属性或者方法都可以直接拿来用。
泛型方法
这里大家需要明确一点的是,泛型方法并不一定依赖其外部的类或者接口,它可以独立存在,也可以依赖外围类存在。例如:
public E get(int index) {
rangeCheck(index);
return elementData(index);
}ArrayList 的这个 get 方法就是一个泛型方法,它依赖外围 ArrayList 声明的 E 这个泛型类型,也就是它没有自己声明一个泛型类型而用的外围类的。
当然,另一种方式就是自己申明一个泛型类型并使用:
public class Caculate {
public T add(T num){
return num;
}
} 这是泛型方法的另一种形态,其中
所以外部调用该方法都需要指定一个限定类型才能调用,像这样:
Caculate caculate = new Caculate();
caculate.add(12);
caculate.add("fadf"); 使用泛型的目的就是为了限定类型,本来不使用泛型语法,那么所有的参数都是 Object 类型的,现在泛型允许我们限定具体类型,这一点要明确。
当然,大家可能没怎么见过这样的调用语法,无论是日常写代码,或是看 JDK 源码实现里,基本上都省略了类型限定部分,也就是上述代码等效于:
Caculate caculate = new Caculate();
caculate.add(12);
caculate.add("fadf");为什么呢?因为编译会推断你的参数类型,所以允许你省略,但前提是你这个方法是有参数的,如果你这个方法的逻辑是不需要传参的,那么你依然需要显式指定限定的具体类型。例如:
public class Caculate {
public T add(){
T num = null;
return num;
}
} Caculate caculate = new Caculate();
caculate.add();这样的 add 方法调用,就意味着你没有限定 T 的类型,那么这个 T 实际上就是 Object 类型,并没有被限定。
泛型的类型限定
这里的类型限定其实指的是这么个语法:
它既可以应用于泛型类或者接口的定义上,也可以应用在泛型方法的定义上,它声明了一个泛型的类型 T,并且 T 类型必须是 String 或者 String 的子类,也就是外部使用时所传入的具体限定类型不能是非 String 体系的类型。
使用这种语法时,由于编译器会确保外部使用时传入的具体限定类型不会超过 String,所以在编译期间将不再使用 Object 做类型擦除,可以使用 String 进行类型擦除。
通配符
通配符是用于解决泛型之间引用传递问题的特殊语法。看下面一段代码:
public static void main(String[] args){
Integer[] integerArr = new Integer[2];
Number[] numberArr = new Number[2];
numberArr = integerArr;
ArrayList integers = new ArrayList<>();
ArrayList numbers = new ArrayList<>();
numbers = integers;//编译不通过
} Java 中,数组是协变的,即 Integer extends Number,那么子类数组实例是可以赋值给父类数组实例的。那是由于 Java 中的数组类型本质上会由虚拟机运行时动态生成一个类型,这个类型除了记录数组的必要属性,如长度,元素类型等,会有一个指针指向内存某个位置,这个位置就是该数组元素的起始位置。
所以子类数组实例赋值父类数组实例,只不过意味着父类数组实例的引用指向堆中子类数组而已,并不会有所冲突,因此是 Java 允许这种操作的。
而泛型是不允许这么做的,为什么呢?
我们假设泛型允许这种协变,看看会有什么问题。
ArrayList integers = new ArrayList<>();
ArrayList numbers = new ArrayList<>();
numbers = integers;//假设的前提下,编译器是能通过的
numbers.add(23.5); 假设 Java 允许泛型协变,那么上述代码在编译器看来是没问题的,但运行时就会出现问题。这个 add 方法实际上就将一个浮点数放入了整型容器中了,虽然由于类型擦除并不会对程序运行造成问题,但显然违背了泛型的设计初衷,容易造成逻辑混乱,所以 Java 干脆禁止泛型协变。
所以虽然 ArrayList
那么,假如有某种需求,我们的方法既要支持子类泛型作为形参传入,也要支持父类泛型作为形参传入,又该怎么办呢?
我们使用通配符处理这样的需求,例如:
public void test2(ArrayList list){
}ArrayList 表示泛型类型具体是什么不知道,但是具体类型必须是 Number 及其子类类型。例如:ArrayList
但是,通配符往往用于方法的形参中,而不允许用于定义和调用语法中。例如下面的语句是不被支持的:
ArrayList list = new ArrayList<>();当然了,除了 这种通配符,还有另外两种:
- :通配任意一种类型
- :必须是某个类型的父类
通配符相当于一个集合,符合通配符描述的类型都被框进集合中,方法调用时传入的实参都必须是这个集合中的一员,否则将不能通过编译。
细节与局限
通配符的只读性
考虑这样一段代码:
ArrayList list = new ArrayList<>();
ArrayList arrayList = list;
arrayList.add(32);
arrayList.add("fadsf");
arrayList.add(new Object()); 上述的三条 add 语句都不能通过编译,这就是通配符的一个局限点,通配符匹配出来的泛型类型只能读取,不能写。
原因也很简单,? 代表不确定类型,即你不知道你这个容器里面放的是什么类型的数据,所以你只能读取里面的数据,不能瞎往里面添加元素。
泛型不允许创建数组
我们刚开始介绍通配符的时候说过,数组具有协变性,即子类数组实例可以赋值给父类数组实例。我们也说过,泛型类型不具有协变性,即便两个泛型类实例的具体类型是父子关系,他们之间也不能相互转换。
具体原因是什么,我们也详细介绍了,大致意思就是,父类容器可以放任意类型的元素,而子类容器只能放某种特殊类型的元素,如果父类代表了某一个子类容器,那么父类容器就有可能放入非当前子类实例所允许的元素进入容器,这会导致逻辑上的混乱,所以 Java 不允许这么做。
那么,如果允许泛型创建数组,由于数组的协变性,泛型数组必然也具有协变性,而泛型本身又不允许协变,自然冲突,所以泛型数组也是不允许创建的。
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
欢迎关注微信公众号:OneJavaCoder,所有文章都将同步在公众号上。
