Greenplum:你不可不知的实施与维护最佳实践
近两年,国内的大数据市场逐渐成熟,有真实的大数据处理需求的企业数量呈现爆炸性的增长,从传统的数据库产品往MPP数据库转型的增长势头十分迅猛。Greenplum作为MPP产品的领头羊,具有较低的学习成本,得到了国内大量客户的青睐。
目录
-
GP实施之道
1、前期规划的重要性
2、数据模型设计的重要性
-
日常运维最佳实践
1、日常维护关注这些
2、重点说说系统表的维护
3、检查工具
4、分析方法和处理技巧
第一篇 GP实施之道
国内的一位Greenplum大拿(也是翻译Greenplum官方资料的第一人),曾经说过:学会用Greenplum不难,但要用好Greenplum就要下一番苦工。Greenplum数据库产品在中国一路走来,期间不乏负面声音。除了竞争对手的恶意中伤以外,所有问题的解决都是我们一点一滴经验的积累,都是我们修炼之路上的宝贵财富。
我们在硬件配置方面曾吃过不少亏。早期不少案例都是去做实施时才感叹:“巧妇难为无米之炊”。总结出了好多宝贵的经验。后来有人跟我说:为什么没有早点看到这篇文章!因此,早期做好架构规划,做好选型是何等重要。
在硬件选型上,我们讲究达到平衡。是要在性能、容量、成本等多个方面综合考虑,取得平衡。不能一味追求容量而忽略了整体性能,忽略了日后维护和扩容的成本;也不能一味追求性能而忽略了成本,而让采购部门望而却步。
搭建Greenplum集群,首要考虑单个Segment host上的实例个数,随着现在单台PC服务器的处理能力不断提升,规划实例个数已经不能简单的按照CPU核数来推算。单台服务器的实例个数与数据库的并发处理能力是成反比的。因此,规划单台服务器的实例个数需要综合考虑服务器配置、生产环境的运行负载压力、跑批用户和前段查询用户并发需求等各个方面。大多数场景下,4或6个为宜。
同样,作为整体架构设计的重要组成部分,ETL服务器、监控管理,备份策略如何规划,如何高效组网都得在前期考虑好。在我们的成功案例中,同一个企业级数据平台中Greenplum集群和Hadoop集群配合运作的案例越来越多。在中国移动的大数据架构规范中,云化ETL是一个重要的组成部分。云化ETL就是构架在Hadoop集群之上。Greenplum提供了专用产品模块gphdfs,Greenplum通过gphdfs可以直接与HDFS上的数据进行交互,并且可以同时发挥Greenplum和Hadoop两者并行处理的优势。
实施Greenplum的项目,有的是从其他数据库产品迁移过来的数据模型,有的是新设计的数据模型。无论是哪种情况,设计时请重点关注Greenplum的特性,要充分发挥Greenplum所长:
-
分布键:均匀为第一大原则,选取更有业务意义的字段,并非必须选择原库的主键(PK)。
-
压缩表使用:大表都要采用压缩存储,既节省空间也节省IO资源。长远来看还可降低阵列卡和磁盘的故障率。
-
行存还是列存:列存储有更高的压缩率,合适于聚合运算,但不合适于宽表。一个数据库中不应只有一种存储方式,每张表应依据实际情况设计存储方式。
-
临时表:对于程序中所使用到的临时表和中间表,上述3点规则同样适用。
-
分区:Greenplum的分区原理与其他数据库无异。表的子分区个数不宜过多,子分区粒度不易过细,子分区之间无需均匀。
-
索引:在Greenplum中,可以使用索引但不能滥用。与OLTP类型数据库不同,Greenplum在绝大部分关联场景中不会用到索引。只有部分小结果集的查询场景中需要使用索引优化。
第二篇 日常运维最佳实践
第一篇介绍了GP实施前重点应该关注前期规划及模型设计,其实实施完运维更重要,切忌运而不维(只让其运行而不加以维护)!
想要一个数据库长久健康的运行,离不开一个称职的DBA。
从其他数据库的DBA转为Greenplum的DBA并不是一件很困难的事,成功转成Greenplum DBA的工程师越来越多。
现在企业客户中搭建的Greenplum集群服务器数量是越来越大,在电信行业和银行业,搭建50台服务器以上的Greenplum集群越来越多。而集群服务器数量越多也就代表故障发生率越高。作为Greenplum的DBA和运维人员,不单只关注Greenplum本身,还要关注集群中各硬件的状况,及时发现及时处理。硬盘状态、阵列卡状态、硬件告警、操作系统告警、空间使用率等都是应关注的重点。这些都可通过厂商提供的工具,编写监控程序,SNMP协议对接企业监控平台等手段提升日常巡检和监控的效率。
针对Greenplum,DBA需要关注的重点:
(1)Greenplum的状态:Standby master的同步状态往往容易被忽略。通过监控平台或者脚本程序,能够及时告警则最好。
(2)系统表:日常系统表维护(vacuum analyze),在系统投产时就应该配置好每天执行维护。
(3)统计信息收集:统计信息的准确性影响到运行效率,用户表应该及时收集统计信息。在应用程序中增加收集统计信息的处理逻辑,通过脚本定时批量收集统计信息,或者两者相结合。针对分区表日常可按需收集子分区的统计信息,可节省时间提升效率。
(4)表倾斜:表倾斜情况应该DBA的关注点之一,但无需每天处理。
(5)表膨胀:基于postgresql的MVCC机制,表膨胀情况不能忽视。重点应该关注日常更新和删除操作的表。
(6)报错信息:在日志中错误信息多种多样,大部分不是DBA需要关注的。应该重点关注PANIC、OOM、Internal error等关键信息。
Greenplum与其他所有关系型数据库一样,拥有一套管理数据库内部对象及关联关系的元数据表,我们称之为Greenplum系统表。Greenplum的产品内核是基于postgresql数据库基础上开发完成的,因此,Greenplum系统表很多继承于postgresql数据库。
Greenplum的系统表大致可分为这几类:
(1)数据库内部对象的元数据,如:pg_database、pg_namespace、pg_class、pg_attribute、pg_type、pg_exttable等。
这类系统表既涵盖了全局的对象定义,也涵盖了每个数据库内的各种对象定义。这类系统表的元数据不是分布式的存储,而是每一个数据库实例(不论是master实例还是segment实例)中都各有一份完整的元数据。但也有例外,如:gp_distribution_policy(分布键定义)表则只在master上才有元数据。
对于这类系统表,各个实例之间元数据保持一致十分重要。
(2)维护Greenplum集群状态的元数据,如:gp_segment_configuration、gp_configuration_history、pg_stat_replication等。
这类系统表主要由master实例负责维护,就如segment实例状态管理的两张表gp_segment_configuration和gp_configuration_history的数据是由master的专用进程fts负责维护的。
(3)Persistent table,如:gp_persistent_database_node、gp_persistent_filespace_node、gp_persistent_relation_node、gp_persistent_tablespace_node。
这类系统表同样是存在于每一个数据库实例中。在每个实例内,persistenttable与pg_class/pg_relation_node/pg_database等系统表有着严格的主外键关系。这类系统表也是primary实例与mirror实例之间实现同步的重要参考数据。
在Greenplum集群出现故障时,会有可能导致系统表数据有问题。系统表出现问题会导致很多种故障产生,如:某些数据库对象不可用,实例恢复不成功,实例启动不成功等。针对系统表相关的问题,我们应该结合各个实例的日志信息,系统表的检查结果一起定位问题,本文将介绍一些定位、分析及解决问题的方法和技巧。
Greenplum提供了一个系统表检查工具gpcheckcat。该工具在$GPHOME/bin/lib目录下。该工具必须要在Greenplum数据库空闲的时候检查才最准确。若在大量任务运行时,检查结果将会受到干扰,不利于定位问题。因此,在使用gpcheckcat前建议使用限制模式启动数据库,确保没有其他应用任务干扰。
1、遇到临时schema的问题,命名为pg_temp_XXXXX,可以直接删除。通过gpcheckcat检查后,会自动生成对临时schema的修复脚本。由于临时schema的问题会干扰检查结果,因此,处理完后,需要再次用gpcheckcat检查。
2、如遇个别表对象元数据不一致的情况,通常只会影响该对象的使用,不会影响到整个集群。如果只是个别实例中存在问题,可以通过Utility模式连接到问题实例中处理。处理原则是尽量不要直接更改系统表的数据,而是采用数据库的手段去解决,如:drop table/alter table等。
3、persistent table问题,这类问题往往比较棘手,影响也比较大。依据gpcheckcat的检查结果,必须把persistent table以外的所有问题修复完之后,才可以着手处理persistent table的问题。
针对persistent table再展开讲述几种问题的处理技巧:
(1)报错的Segment实例日志中出现类似信息

该错误可能会导致实例启动失败,数据库实例恢复失败等情况。首先可在问题的实例(postgresql.conf)中设置参数gp_persistent_skip_free_list=true。让出问题的实例先启动起来。再进行gpcheckcat检查。在gpcheckcat的结果中应该能找到类似的问题:

从上述检查结果可以看出persistent table的部分数据和其他系统表对应关系不正确。处理方法就是要修复persistent table数据。

(2)报错的实例日志中出现类似信息
该问题可能会导致实例启动失败。可在问题的实例(postgresql.conf)中设置参数gp_persistent_repair_global_sequence=true,便可修复相应问题,让相应实例正常启动。

(3)报错的实例日志中出现类似信息
该问题会出现在AO表中,表示个别实例上的数据文件被损坏。问题可能会导致进程PANIC,实例启动失败。首先可在问题的实例(postgresql.conf)中设置参数gp_crash_recovery_suppress_ao_eof=true。让出问题的实例先启动起来。再进行gpcheckcat检查。确定问题所在并修复。而通常出问题的AO表已经损坏,建议rename或者删除。
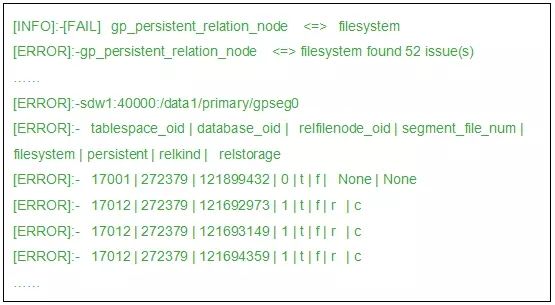
(4)在gpcheckcat的检查结果中如果出现如下信息
检查结果表明文件系统中存在部分数据文件在系统表中没有对应的关系,也就是文件系统中有多余的数据文件。这种情况不会影响Greenplum集群的正常运作,可以暂时忽略不处理。
修复persistent table表的问题,不可手工修改,只能够使用Greenplum提供的修复工具gppersistentrebuild进行修复。工具提供了备份功能,在操作修复之前必须要执行备份操作。然后通过gppersistentrebuild,指定待修复的实例的contentid进行修复。
另外,如果primary实例与mirror实例之间是处于changetracking状态。一旦primary实例进行了persistent table的修复操作,primary实例与mirror实例之间只能执行全量恢复操作(gprecoverseg -F)。
上面所介绍的一些GUC参数,都是在修复系统表过程中临时增加的参数,待集群恢复正常之后,请将所修改过的GUC参数值恢复回原有默认状态。
Greenplum已经开源了,生态圈在迅速地壮大,Greenplum的爱好者、拥护者人数也在不断地壮大。在使用和探索Greenplum的路途中,我们通过一点经验介绍,希望让大家少走弯路。在产品实施过程中的关键阶段,还应该更多地寻求专业顾问的支持。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2016-02-23